【YOLOv8/RT |
您所在的位置:网站首页 › mccp检测结果 › 【YOLOv8/RT |
【YOLOv8/RT
|
本人最近正在使用YOLOv8和RT-DETR两个模型做小目标检测方面的研究,YOLOv8相信大家已经耳熟能详,而RT-DETR是百度新开发的一款实时目标检测模型,是基于VIT算法的。尽管用的推理框架与YOLOv8不属于同一派别,但目前也已经集成到了YOLOv8的Ultralytics中,无论是预测、追踪还是结果处理与YOLOv8的方式都是一样的。本文在已经训练好模型的情况下,使用模型进行预测+追踪,并对追踪返回的results结果进行解析和处理。 目录 1 预测+追踪(predict + track) 1.1 直接调用官方封装的方法 1.2 视频流处理时遇到的问题 1.3 自定义追踪方法 2 results结果解析和处理 2.1 results包含的参数 2.2 结果获取与简单处理 1 预测+追踪(predict + track)官方关于预测(predict)的文档:Predict - Ultralytics YOLOv8 Docs 官方关于追踪(track)的文档:Track - Ultralytics YOLOv8 Docs 1.1 直接调用官方封装的方法由于ultralytics包对于predict和track方法都已经封装好,因此只要直接调用就可以,如下面的代码: from ultralytics.models import YOLO,RTDETR # 初始化模型 model = YOLOv8(weights_path) model = RTDETR(weights_path) # weights_path为指向训练好的权重文件的路径 # 调用track方法进行追踪 results = model.track( source=source_path, # 待处理视频的地址,如果是webcam实时录制处理,则source=0 stream=True, # 对于视频采用流模式处理,防止因为因为堆积而内存溢出 # show=True, # 实时推理演示 tracker="botsort.yaml", # 默认tracker为botsort save=True, # 选择是否保存处理后的视频 save_dir=save_path, # 处理视频的保存路径 # vid_stride=2, # 视频帧数的步长,即隔几帧检测跟踪一次 # save_txt=True, # 把结果以txt形式保存 # save_conf=True, # 保存置信度得分 # save_crop=True, # 保存剪裁的图像 conf=0.4, # 规定阈值,即低于该阈值的检测框会被剔除 iou=0.5, # 交并比阈值,用于去除同一目标的冗余框 device=0, # 用GPU进行推理,如果使用cpu,则为device="cpu" ) # 对每一帧返回的结果进行处理 for r in results: boxes = r.boxes # Boxes object for bbox outputs masks = r.masks # Masks object for segment masks outputs probs = r.probs # Class probabilities for classification outputs # 加上自己的结果处理代码由于我进行的是小目标实时检测,因此处理的是视频流而不是单张图片,为了避免内存堆积导致程序崩溃,我选用了流模式处理方式,即stream=True,选用此处理方式,也就意味着在推理时每一帧都会返回一个results对象(关于results对象的解析在第2节),因此通过下面的for循环,我们可以轻松获取每一帧的结果(比如检测框对应的类别、置信度、位置,或是在某一帧的图像上进行二次绘制并保存等等)。 当然,我调用track是因为我有追踪的需求,如果仅仅是进行预测的话,将model.track替换为model.predict即可,要注意的是替换为predict之后有些参数是不能使用的,比如trakcer这个参数,它的意思是选用哪一种多目标跟踪算法(我选用的是botsort),如果仅仅是预测的话就不需要跟踪算法了。 关于predict和track的更多参数可以参考我在上面给出的官方文档链接。 1.2 视频流处理时遇到的问题可能有些小伙伴在运行track代码的时候会遇到下面OMP的错误: 解决办法很简单,在代码前面加上这个就好啦: import os os.environ['KMP_DUPLICATE_LIB_OK'] = 'True' 1.3 自定义追踪方法官方的track方法其实是已经封装好的了,其背后的原理就是:首先通过模型推理获取某一帧的results,接着根据results里面的信息对该帧的图片进行检测框及标签的绘制,最后合并为一个完整的视频。 因此,如果有友友觉得直接调用track方法自由度不高的话,也可以尝试bortsort提供的自定义追踪框架。自定义追踪框架的意义主要在于两个方面: 用户可以定义自己的bortsort追踪模型,也可以加入Reid机制;用户可以更自由地绘制检测结果。代码框架如下: import cv2 import numpy as np from pathlib import Path from boxmot import BoTSORT tracker = BoTSORT( model_weights=Path('osnet_x0_25_msmt17.pt'), # which ReID model to use device='cuda:0', fp16=True, ) vid = cv2.VideoCapture(0) color = (0, 0, 255) # BGR thickness = 2 fontscale = 0.5 while True: ret, im = vid.read() # substitute by your object detector, input to tracker has to be N X (x, y, x, y, conf, cls) dets = np.array([[144, 212, 578, 480, 0.82, 0], [425, 281, 576, 472, 0.56, 65]]) tracks = tracker.update(dets, im) # --> (x, y, x, y, id, conf, cls, ind) xyxys = tracks[:, 0:4].astype('int') # float64 to int ids = tracks[:, 4].astype('int') # float64 to int confs = tracks[:, 5] clss = tracks[:, 6].astype('int') # float64 to int inds = tracks[:, 7].astype('int') # float64 to int # in case you have segmentations or poses alongside with your detections you can use # the ind variable in order to identify which track is associated to each seg or pose by: # segs = segs[inds] # poses = poses[inds] # you can then zip them together: zip(tracks, poses) # print bboxes with their associated id, cls and conf if tracks.shape[0] != 0: for xyxy, id, conf, cls in zip(xyxys, ids, confs, clss): im = cv2.rectangle( im, (xyxy[0], xyxy[1]), (xyxy[2], xyxy[3]), color, thickness ) cv2.putText( im, f'id: {id}, conf: {conf}, c: {cls}', (xyxy[0], xyxy[1]-10), cv2.FONT_HERSHEY_SIMPLEX, fontscale, color, thickness ) # show image with bboxes, ids, classes and confidences cv2.imshow('frame', im) # break on pressing q if cv2.waitKey(1) & 0xFF == ord('q'): break vid.release() cv2.destroyAllWindows()下面给出一张我使用自定义模型推理出来的某一帧图片(主要是识别人和安全帽的):
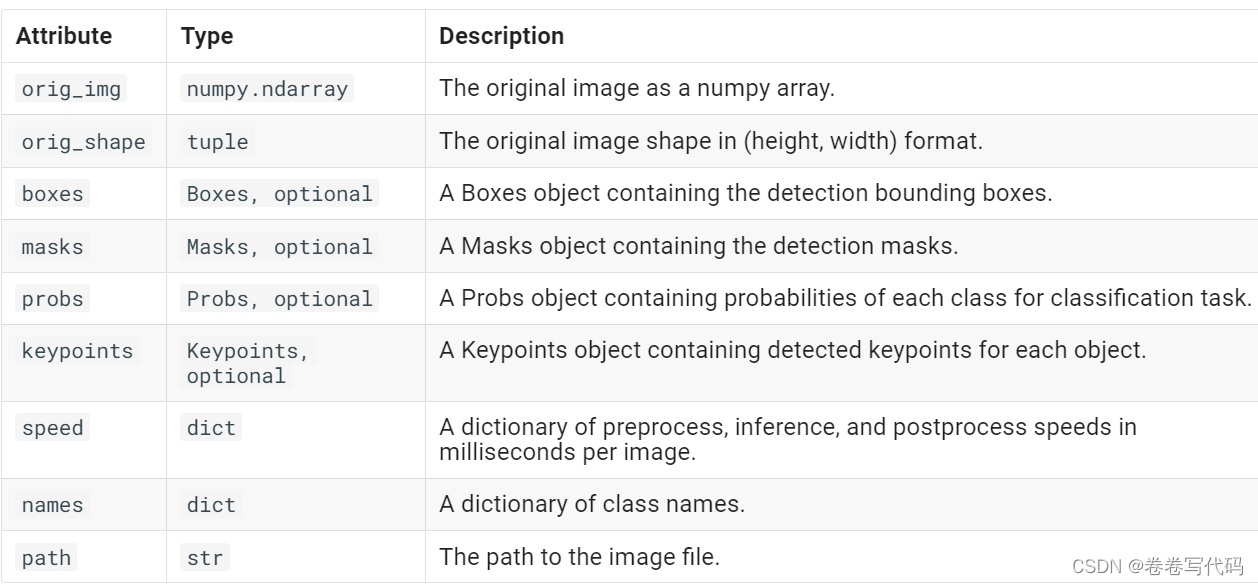
刚刚在第一节中已经知道,如果使用流模式处理视频,我们会逐帧获得一个results对象,而这个results对象对于我们的后续处理是非常重要的。以工地的小目标检测为例,我们需要从每一帧的results中获取当前的人数、工程车辆数等等,并且根据检测框所在的位置,判断当前工地是否有违规行为发生。这些都涉及到对于results结果的处理。 2.1 results包含的参数根据官方文档的描述,result主要包含如下几个对象:
简单解释一下: orig_img: numpy数组格式的原图,可以在此原图上进行进一步绘制orig_shape:原图的shapeboxes:十分重要的一个对象,包含所有检测框的信息masks:包含检测掩码的mask对象probs:一个包含分类任务中每个类别的概率的Probs对象keypoints:包含每个对象检测到的关键点speed:字典类型,表示以毫秒为单位的预处理、推理和后处理速度names:字典类型,表示所有类的名称path:图片的路径其中,boxes比较重要,里面又包含了几个对象:
当然,其他几个对象在特定情况下也有很大用处,比如names可以用来输出看一下所有待检测目标的类名,keypoints对于关注人体姿态的小伙伴们会起到很大作用,orig_img可以供我们在此基础上进行绘制,等等。 2.2 结果获取与简单处理1.1节中已经给出了track的代码,我们可以在此基础上对boxes等结果进行获取,代码如下: from ultralytics import YOLO # Load a pretrained YOLOv8n-cls Classify model model = YOLO('xxx') # Run inference on an image results = model('xxx') # results list for r in results: boxes = r.boxes # Boxes object for bbox outputs masks = r.masks # Masks object for segment masks outputs probs = r.probs # Class probabilities for classification outputs在上面的for循环中,我们已经获取到了boxes对象,接下来可以进一步获取里面的几个参数。比如我想要对某一类检测框的数目作一个统计,代码如下: import numpy as np from ultralytics import YOLO # Load a pretrained YOLOv8n-cls Classify model model = YOLO('xxx') # Run inference on an image results = model('xxx') # results list for r in results: boxes = r.boxes # Boxes object for bbox outputs class_ids = boxes.cls.cpu().numpy().astype(int) # 转为int类型数组 num = np.sum(class_ids == 0) # 对类别为0的检测框数目作一个统计当然,我们也可以仿照上面的格式,对所有目标检测框的位置作处理,如果要获取到精确的位置,建议用xyxy格式(因为本人根据实践发现,xywh框的位置相较于原图会有一些偏差,而xywhn和xyxyn是归一化之后的相对位置,主要是方便于训练时收敛的),在数据获取后要注意进行tensor和numpy类型的转换(根据实际需求选择)。 获取到的xyxy信息可以帮助我们处理很多实际问题,比如可以根据位置计算两个框之间的IoU来判断两个框是否重叠,也可以计算不同框之间的相对距离,判断人和大型机器是否保持在安全范围内。关于更多的计算细节,大家就要结合自己的应用场景自己摸索啦~ 有时候,我们在处理一个视频时需要保存某一帧时的检测图片,这时候可以调用result的plot方法进行绘制,代码如下: from PIL import Image from ultralytics import YOLO # Load a pretrained YOLOv8n model model = YOLO('xxx') # Run inference results = model('xxx') # results list # Show the results for r in results: im_array = r.plot() # plot a BGR numpy array of predictions im = Image.fromarray(im_array[..., ::-1]) # RGB PIL image im.show() # show image im.save('results.jpg') # save image按照官方文档所说,plot()里面也是有挺多可供选择的参数的,比如 r.plot(conf=False, line_width=1, font_size=1.5),就是规定了绘制的时候不显示置信度信息、设置检测框的宽度为1、标签字体大小为1.5。 当然,也可以在r.plot()的基础上进行进一步的绘制,可以使用自定义绘制方法,如下: for r in results: boxes = r.boxes # Boxes object for bbox outputs # plot a BGR numpy array of predictions im_array = r.plot(conf=False, line_width=1, font_size=1.5) # 使用自定义的绘制方法,根据boxes进一步提取信息并绘制到图片上 custom_plot(im_array, boxes.xywh, boxes.xyxy, boxes.cls, boxes.id)本人关于results的处理方式也还在进一步挖掘中。YOLOv8由于实时性好、检测性强、对于结果的获取便利,因此可以用于各种各样不同的目标检测场景。并且钟爱RT-DETR的友友们也可以采用相同的结果获取方式,因为RT-DETR目前是被集成到了YOLO项目中的,results的格式与YOLO的一模一样~ 新人发帖,多多关照 ~ 觉得有帮助的小朋友们点个赞吧! wink~ |



【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |