高速缓存与一致性 |
您所在的位置:网站首页 › linux内存对齐 › 高速缓存与一致性 |
高速缓存与一致性
|
DMA应该多多少少知道点吧。DMA(Direct Memory Access)是指在外接可以不用CPU干预,直接把数据传输到内存的技术。这个过程中可以把CPU解放出来,可以很好的提升系统性能。那么DMA和Cache有什么关系呢?这也需要我们关注? 需要解决什么问题我们知道DMA可以帮我们在I/O和主存之间搬运数据,且不需要CPU参与。高速缓存是CPU和主存之间的数据交互的桥梁。而DMA如果和cache之间没有任何关系的话,可能会出现数据不一致。例如,CPU修改了部分数据依然躺在cache中(采用写回机制)。DMA需要将数据从内存搬运到设备I/O上,如果DMA获取的数据是从主存那里,那么就会得到旧的数据。导致程序的不正常运行。这里告诉我们,DMA通过总线获取数据时,应该先检查cache是否命中,如果命中的话,数据应该来自cache而不是主存。但是是否先需要检查cache呢?这取决于硬件设计。 
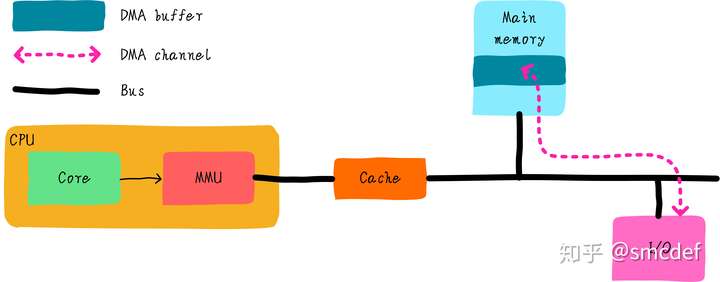 总线监视技术
总线监视技术
还记得《Cache组织方式》文章提到的PIPT Cache吗?它是操作系统最容易管理的Cache。PIPT Cache也很容易实现总线监视技术。什么是总线监视技术呢?其实就是为了解决以上问题提出的技术,cache控制器会监视总线上的每一条内存访问,然后检查是否命中。根据命中情况做出下一步操作。我们知道DMA操作的地址是物理地址,既然cache控制器可以监视总线操作,说明系统使用的cache必须是支持物理地址查找的。而PIPT完全符合条件。VIVT是根据虚拟地址查找cache,所以不能实现总线监视技术。VIPT可以吗?没有别名的VIPT也可以实现总线监视,但是有别名的情况的VIPT是不行的(当然硬件如果强行检查所有可能产生别名的cache line,或许也可以)。总线监视对于软件来说是透明的,软件不需要任何干涉即可避免不一致问题。但是,并不是所有的硬件都支持总线监视,同时操作系统应该兼容不同的硬件。因此在不支持总线监视的情况下,我们在软件上如何避免问题呢? 最简单的方法(nocahe)当我们使用DMA时,首先是配置。我们需要在内存中申请一段内存当做buffer,这段内存用作需要使用DMA读取I/O设备的缓存,或者写入I/O设备的数据。为了避免cache的影响,我们可以将这段内存映射nocache,即不使用cache。映射的最小单位是4KB,因此在内存映射上至少4KB是nocahe的。这种方法简单实用,但是缺点也很明显。如果只是偶尔使用DMA,大部分都是使用数据的话,会由于nocache导致性能损失。这也是Linux系统中dma_alloc_coherent()接口的实现方法。 软件维护cache一致性为了充分使用cache带来的好处。我们映射依然采用cache的方式。但是我们需要格外小心。根据DMA传输方向的不同,采取不同的措施。 如果DMA负责从I/O读取数据到内存(DMA Buffer)中,那么在DMA传输之前,可以invalid DMA Buffer地址范围的高速缓存。在DMA传输完成后,程序读取数据不会由于cache hit导致读取过时的数据。如果DMA负责把内存(DMA Buffer)数据发送到I/O设备,那么在DMA传输之前,可以clean DMA Buffer地址范围的高速缓存,clean的作用是写回cache中修改的数据。在DMA传输时,不会把主存中的过时数据发送到I/O设备。注意,在DMA传输没有完成期间CPU不要访问DMA Buffer。例如以上的第一种情况中,如果DMA传输期间CPU访问DMA Buffer,当DMA传输完成时。CPU读取的DMA Buffer由于cache hit导致取法获取最终的数据。同样,第二情况下,在DMA传输期间,如果CPU试图修改DMA Buffer,如果cache采用的是写回机制,那么最终写到I/O设备的数据依然是之前的旧数据。所以,这种使用方法编程开发人员应该格外小心。这也是Linux系统中流式DMA映射dma_map_single()接口的实现方法。 DMA Buffer对齐要求假设我们有2个全局变量temp和buffer,buffer用作DMA缓存。初始值temp为5。temp和buffer变量毫不相关。可能buffer是当前DMA操作进程使用的变量,temp是另外一个无关进程使用的全局变量。 int temp = 5; char buffer[64] = { 0 };假设,cacheline大小是64字节。那么temp变量和buffer位于同一个cacheline,buffer横跨两个cacheline。 

假设现在想要启动DMA从外设读取数据到buffer中。我们进行如下操作: 按照上一节的理论,我们先invalid buffer对应的2行cacheline。启动DMA传输。当DMA传输到buff[3]时,程序改写temp的值为6。temp的值和buffer[0]-buffer[60]的值会被缓存到cache中,并且标记dirty bit。DMA传输还在继续,当传输到buff[50]的时候,其他程序可能读取数据导致temp变量所在的cacheline需要替换,由于cacheline是dirty的。所以cacheline的数据需要写回。此时,将temp数据写回,顺便也会将buffer[0]-buffer[60]的值写回。在第4步中,就出现了问题。由于写回导致DMA传输的部分数据(buff[3]-buffer[49])被改写(改写成了没有DMA传输前的值)。这不是我们想要的结果。因此,为了避免出现这种情况。我们应该保证DMA Buffer不会跟其他数据共享cacheline。所以我们要求DMA Buffer首地址必须cacheline对齐,并且buffer的大小也cacheline对齐。这样就不会跟其他数据共享cacheline。也就不会出现这样的问题。 Linux对DMA Buffer分配的要求Linux中,我们要求DMA Buffer不能是从栈和全局变量分配。这个主要原因是没办法保证buffer是cacheline对齐。我们可以通过kmalloc分配DMA Buffer。这就要求某些不支持总线监视的架构必须保证kmalloc分配的内存必须是cacheline对齐。所以linux提供了一个宏,保证kmalloc分配的object最小的size。例如ARM64平台的定义如下: #define ARCH_DMA_MINALIGN (128)ARM64使用的cacheline大小一般是64或者128字节。为了保证分配的内存是cacheline对齐,取了最大值128。而x86_64平台则没有定义,因为x86_64硬件保证了DMA一致性。所以我们看到x86_64平台,slub管理的kmem cache最小的是kmalloc-8。而ARM64平台,slub管理的kmem cache最小的是kmalloc-128。其实ARM64平台分配小内存的代价挺高的。即使申请8字节内存,也给你分配128字节的object,确实有点浪费。 编辑于 2020-06-06 「真诚赞赏,手留余香」 赞赏1 人已赞赏  高速缓存
Linux 内核
计算机体系架构
赞同 134
26 条评论
分享
喜欢
收藏
申请转载
文章被以下专栏收录
高速缓存
Linux 内核
计算机体系架构
赞同 134
26 条评论
分享
喜欢
收藏
申请转载
文章被以下专栏收录
 iCache和dCache一致性
smcde...
发表于高速缓存与...
Cache一致性的那些事儿 (3)--Directory方案
iCache和dCache一致性
smcde...
发表于高速缓存与...
Cache一致性的那些事儿 (3)--Directory方案
3. Directory-based 解决方案在一个大型的计算系统中,当其处理器的数目比较多时, 采用snooping方案存在两个方面的弊端: 由于所有cache的一致性操作全部需要通过shared bus来完成,shared… shawn 发表于RISC-... 缓存一致性 的 总结(一)当我们讨论缓存一致性的时候我们在讨论什么: 当系统中用cache来缓存dram的数据时,如何保证任意一cpu的写请求会被所有其他cpu看到。 两大类 bus snooping: 所有cache相关的信息都在共享bus… 走起兄de... 发表于数字芯片设... 缓存一致性 的 总结(二)上一章我们总结了protocol上的内容,主要是设计缓存的状态机,当cpu发出的指令或bus上传来的指令时,状态转换。今天来总结一下实际设计时需要考虑的各种问题。(强行扒cmu课件hhh) 如果cpu… 走起兄de... 发表于数字芯片设... 26 条评论 切换为时间排序 写下你的评论... 发布楼主你好,“这种方法简单实用,但是缺点也很明显。如果只是偶尔使用DMA,大部分都是使用数据的话,会由于nocache导致性能损失。这也是Linux系统中dma_alloc_coherent()接口的实现方法。” 这里是不是应该着重强调一下是损失了cpu的对访问dma buffer的性能。 另外问一下,dma传输应该是不经过cache直接到主存吧。 1 回复 踩 举报“CPU读取的DMA Buffer由于cache hit导致取法获取最终的数据。” 其中的“取法”是“无法”吧。 还有我对楼上提出的问题有同样的疑惑,大佬有时间解答下咩 
1
回复
踩
举报
1
回复
踩
举报
谢谢 赞 回复 踩 举报看文章,硬件不支持一致性的时候就需要cacheline对齐。可以参考文章的宏定义,可以搜索代码。 赞 回复 踩 举报kmalloc 只保证返回的 object 可以 DMA 操作,是否对齐取决于架构 赞 回复 踩 举报"而x86_64平台则没有定义,因为x86_64硬件保证了DMA一致性", X86_64怎么保证的,哪里有介绍?谢谢! 赞 回复 踩 举报硬件做了一致性 赞 回复 踩 举报请问一下 linux是如何实现nocache映射的呢?我的理解是cache是CPU内部的硬件实现,有什么指令可以告诉CPU跳过CACHE吗? 赞 回复 踩 举报可以参考部分arch的io_remap实现 赞 回复 踩 举报这点有疑惑,在做DMA的时候会LOCK住总线的,这个时候temp不会被Load到cache中,会被总线仲裁器阻塞的;所以在DMA的时候不会出现影响cache行中的temp的;DMA使用对齐地址是DMA控制器的要求,有地址对齐的限制;但是会配合MASK或者OFFSET来做非对齐的地址操作的; 所以说这个是不是和处理器的架构有关?大拿在实际的工作中遇见过这种情况吗? 赞 回复 踩 举报应该是说cpu直接把temp写进cahce里的,而不是从内存load的吧 赞 回复 踩 举报工作用不用倒是不用在意,而是现在的内核代码是怎么实现的。既然代码这么写的,说明是存在这种硬件的。至于DMA是否一定使用对齐地址这取决于硬件设计。 赞 回复 踩 举报"buffer[0]-buffer[60]" 应该为“buffer[0]-buffer[59]” 赞 回复 踩 举报“流失DMA映射” 是否应为 ”流式DMA映射”? 赞 回复 踩 举报感谢解惑,对于dma的cache line对齐动作,一直不是很理解为什么要这么做,今天找到了一个角度。 赞 回复 踩 举报麻烦问下这些图是用什么软件画的呢?画的真好 赞 回复 踩 举报 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |