JPEG压缩过程原理 |
您所在的位置:网站首页 › jpeg图像编码过程 › JPEG压缩过程原理 |
JPEG压缩过程原理
|
目录 前言 JPEG压缩过程 第一步:RGB到YUV的映射转换(无损可逆变换) 第二步:下采样(有损压缩) 第三步 DCT变换(无损可逆变换) 第四步 量化 (留低频,弃高频)(有损压缩) 第五步 熵编码(zigzag scan & 霍夫曼编码)无损 总结: 前言JPEG也就是大家常见的图片格式之一,它还有一个小名,ipg。JPEG是一种有损压缩格式,相比于其他图片格式文件更小,也就是一些细节在压缩过程中丢失了,比较适合存储复杂的照片图像,不适合保存具有细节(线条)的图片。
其他常见的图片格式有png,tiff等等。PNG是一种无损压缩格式,而且支持透明度,也就是说可以不保存那个白色的大背景,生成一种素材图,JPG格式就不支持透明。虽然PNG文件通常比JPG文件大,但是PNG文件的文件大小通常比其他无损压缩格式小。TIFF格式支持多种压缩方式,包括无损压缩和有损压缩,也支持透明。此外,TIFF保存的文件比较大,保存的图失真度极小,而且TIFF格式可以保存分层和透明信息。比如我保存了图层信息,打开还是可以编辑的。 JPEG压缩原理的动机:人眼对图像的亮度更敏感,对于色度变化不敏感。如下图,
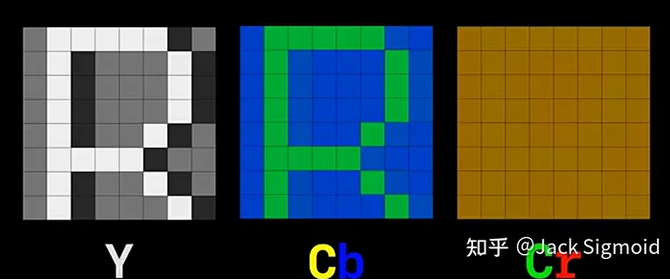
所以,JPEG首先将图像的RGB空间进行映射,到YUV(也称YCbCr)颜色空间。Y表示明亮度,也是灰度(luma);UV表示色度(也称CbCr,Chrominance-Blue,Chrominance-Red,其中Cb是蓝色色度分量,Cr是红色色度分量)。JPEG压缩要做的,就是保留明亮度,压缩色度。
RGB 转 YUV 的过程实际上就是 把 RGB 3分量里面的亮度信息提取出来,放到 Y 分量。再把 RGB 3分量里面的色调 ,色饱和度 信息提取出来放到 U跟 V分量。 Y亮度:
其中Kr,Kg,Kb分别表示不同的通道权重,且Kr+Kg+Kb=1。 那剩下的差值就是Cb,Cr,Cg,其中Cg是不用知道的,因为已知Y,Cb,Cr的话,Cg也是已知的了,我们只需要前三个就可以,Cg为冗余信息。 因为: 因此,Y分量写为: U分量,即Cb分量写为:
V分量,即Cr分量写为:
但是,我们需要给他们规定范围,进行范围归一化,首先计算范围, 对于V分量:
范围为:
同理,U分量范围为:
因此,缩放系数设置为:
最后,公式为:
实验获得的参数为:
但是,对于YCbCr和RGB均在[0,255]时的转换关系的转换公式(未经伽玛校正),加上了偏移量: Y = 0.299R + 0.587G + 0.114BU = -0.1687R - 0.3313G + 0.5B + 128V= 0.5R - 0.4187G - 0.0813G + 128
例子:
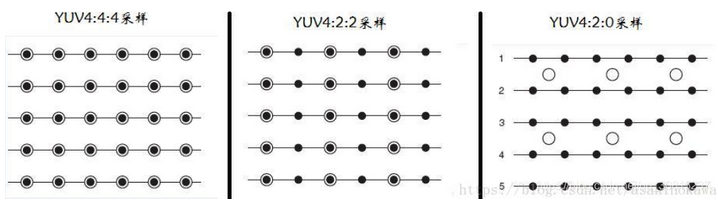
保留Y分量,对U和V进行下采样压缩,这是有损的。 YUV有多种采样比例,采用A:B:C表示法来描述Y,U,V采样频率比例:以黑点表示采样该像素点的Y分量,以空心圆圈表示采用该像素点的UV分量。
在JPEG压缩中,采用的就是4:2:0,这种采样方式是指对于扫描线上相邻的4个像素点的每个点的Y全部进行采集,而对于扫描线上,上下相邻的4个点,仅仅采集由这4个点计算得到的一个Cr和一个Cb值。换一种说法,即4个Y分量共用一组UV。Y'00、Y'01、Y'10、Y'11共用Cr00、Cb00,其他依次类推。 接上面的例子,如下图所示,只选取4个像素的左上角。
最终UV为:
DCT变换,也是离散余弦变换,是与傅里叶变换相关的一种变换,它类似于离散傅里叶变换(DFT for Discrete Fourier Transform),但是只使用实数。 而傅里叶变换的实质是,将信号从时域变为频域:
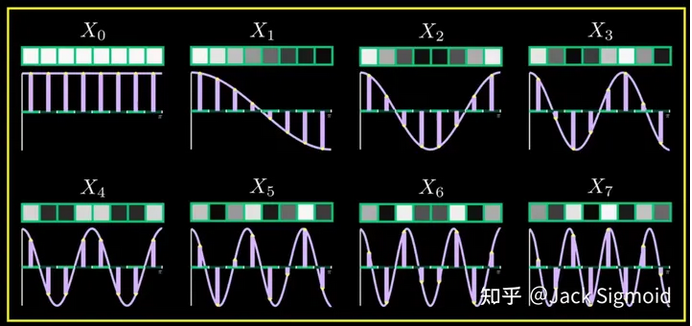
详细见: 详解离散余弦变换(DCT) - 知乎 变换的原理是:一切信号都可以用若干不同频率的标准余弦信号通过特定的组合形式表示出来。 首先考虑8个像素组成的序列,这里可以理解为信号序列了。对这个信号序列,进行DCT变换,它将拆解为八个余弦函数的组合。
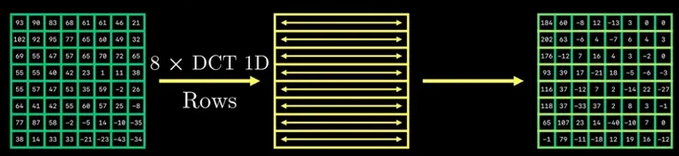
其中xn,就是我们想要的DCT系数。 而对于图像(这里应该是采样后的YUV分量),JPEG采用二维DCT(即对于8*8的矩阵,依次进行行列DCT):
一般来说,人眼对于图像的高频信息不敏感,对低频信息敏感。图像中的高频信息就是那些颜色变化快的,相邻区域之前差别大的(比如,细节、噪声),而低频信息是那些颜色变化慢的(大致轮廓)。 因此,我们要把高频信息去掉,那哪些是高频信息呢? 还记得上面DCT变换的八个余弦函数不,其实,这八个余弦函数就对应不同的频率,越往后,对应的频率越高。
因此,我们要做的就是保留前面的Xn,去掉后面Xn,对应到二维,就是保留左上角的系数,去掉右下角的系数。 那怎么去呢?需要规则,这就是量化矩阵(有量化表):
上表分别为亮度量化表和色彩量化表,表示 50% 的图像质量。这两张表中的数据基于人眼对不同频率的敏感程度制定。 量化过程为,使用量化矩阵与前面得到的 DCT 矩阵逐项相除并取整。
量化是有损的,在解码时,反量化会乘回量化表的相应值。由于存在取整,低频段会有所损失,高频段的0字段则会被舍弃,最终导致图像质量降低。 第五步 熵编码(zigzag scan & 霍夫曼编码)无损这是最后一步压缩了,其实在图片显示上,上一步已经压缩完成,但是在存储上,我们还可以进行编码压缩。先进行zigzag 排列(游程编码),对于8*8矩阵,将相似频率组在一起,这很简单:
然后进行huffuman编码,实现进一步压缩。这里就不赘述了。 到此,对于一个8*8像素块的压缩就完成了,全图像就把图像分为多个像素块,分别进行压缩就可以了。 总结:JEPG压缩的整个流程分五步(我这里分五步,哈哈): 先将图像从RGB空间映射到YUV空间下采样UV,有损压缩进行DCT变换,得到DCT系数通过量化表留低频去高频进一步编码压缩有什么不对的还望指正! |
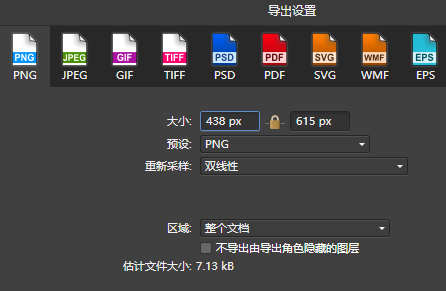
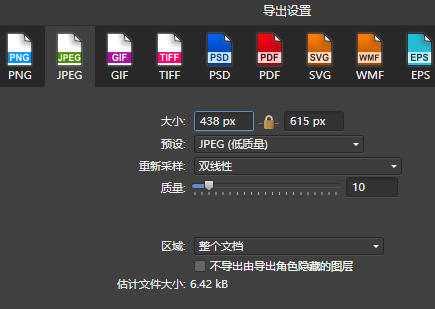 我这里为了比较,选择低质量。
我这里为了比较,选择低质量。

 经典的视错觉图,两个灰色是一样的,不信挡住中间看看。
经典的视错觉图,两个灰色是一样的,不信挡住中间看看。




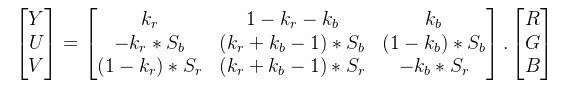

 其他更加详细的转换公式见:详解RGB和YUV色彩空间转换_yuv转rgb_古楼望月的博客-CSDN博客
其他更加详细的转换公式见:详解RGB和YUV色彩空间转换_yuv转rgb_古楼望月的博客-CSDN博客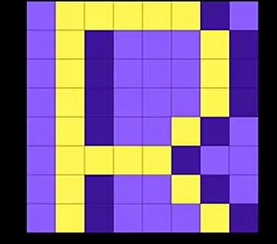
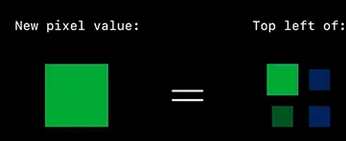








【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |