hadoop 集群节点查看 |
您所在的位置:网站首页 › hadoop集群包括哪些节点 › hadoop 集群节点查看 |
hadoop 集群节点查看
|
本文档介绍了如何设置和配置单节点Hadoop安装,以便您可以使用Hadoop MapReduce和Hadoop分布式文件系统(HDFS)快速执行简单的操作。 先决条件 支持平台 支持GNU / Linux作为开发和生产平台。Hadoop已在具有2000个节点的GNU / Linux集群上进行了演示。 Windows也是受支持的平台,但是以下步骤仅适用于Linux。 必备软件 Linux所需的软件包括: 必须安装Java™。HadoopJavaVersions中描述了推荐的Java版本。 必须安装ssh并且sshd必须正在运行才能使用管理远程Hadoop守护程序的Hadoop脚本。 安装步骤如果您的群集没有必需的软件,则需要安装它。 例如在CentOS Linux上: [root@centos001 ~]# sudo yum install ssh -y [root@centos001 ~]# sudo yum install rsync -y 注意:三台服务器必须是安装了jdk的(没有安装的小伙伴也不用慌张,请看我上一期文章) 下载和上传要获得Hadoop发行版,请从其中一个Apache Download Mirrors下载最新的稳定版本。 创建software目录用于上传软件安装包。 [root@centos001 ~]# mkdir /opt/software 通过xftp工具将Hadoop发行版上传至服务器的 /opt/software/目录下。
解压缩下载的Hadoop发行版。在发行版中,编辑文件etc/hadoop/hadoop-env.sh来定义一些参数,如下所示: [root@centos001 ~]# mkdir /usr/apps [root@centos001 ~]# tar -zxvf /opt/software/hadoop-2.7.2.tar.gz -C /usr/apps/ 查看是否解压完整[root@hadoop001 software]# cd /usr/apps/ [root@hadoop001 apps]# lshadoop-2.7.2 jdk [root@hadoop001 apps]# cd hadoop-2.7.2/ [root@hadoop001 hadoop-2.7.2]# lsbin include libexec NOTICE.txt sbin etc lib LICENSE.txt README.txt share [root@hadoop001 apps]# mv /usr/apps/hadoop-2.7.2/ /usr/apps/hadoop
[root@hadoop001 apps]# cd hadoop/ [root@hadoop001 hadoop]# pwd #查看当前路径 /usr/apps/hadoop [root@hadoop001 hadoop]# vi /etc/profile #HADOOP_HOME# export HADOOP_HOME=usr/apps/hadoop #注意自己的路径 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin [root@hadoop001 hadoop]# source /etc/profile 验证hadoop[root@hadoop001 hadoop]# hadoop version
1. [root@hadoop001 /]# cd /usr/apps/hadoop/etc/hadoop/ 2. [root@hadoop001 hadoop]# vi hadoop-env.sh(修改第25行) -- export JAVA_HOME=/usr/apps/jdk/ #注意自己的jdk路径,按Esc在set nu 回车可以显示序号
[root@hadoop001 hadoop]#vi mapred-site.xml(重命名) mapreduce.framework.name yarn
[root@hadoop001 apps]# scp -r /usr/apps/jdk [email protected]:/usr/apps/ 注意hadoop002要有apps这个目录,没有就用mkidr apps创建hadoop003同样 [root@hadoop001 apps]# scp -r /usr/apps/jdk [email protected]:/usr/apps/ [root@hadoop001 apps]# scp -r /usr/apps/hadoop/ [email protected]:/usr/apps/ [root@hadoop001 apps]# scp -r /etc/profile [email protected]:/etc/profile [root@hadoop001 apps]# scp -r /etc/profile [email protected]:/etc/profile 注意:自己的ip和文件路径
注意查看是否复制成功 [root@hadoop002 apps]# source /etc/profile [root@hadoopoo3 apps]# source /etc/profile hadoop运行测试先关闭防火墙 [root@hadoopoo3 /]# systemctl stop firewalld [root@hadoopoo3 /]# systemctl disable firewalld 1. 格式化 HDFS(初次安装需要才执行) hadoop namenode -format (第一台执行) 2.启动 Hadoop 守护进程 -- 在第一台执行 start-dfs.sh -- 在第三台执行 start-yarn.sh 3.jps 命令检查Hadoop守护进程是否启动成功 [root@hadoopoo3 /]# jps -- 第一台守护进程有 Namenode,DataNode NodeManager -- 第二台守护进程有 SecondaryNameNode,DataNode NodeManager -- 第三台守护进程有 DataNode ResourceManager,NodeManager 4.运行测试 Hadoop -- 在浏览器输入 192.168.xx.x:50070(第一台IP地址)
5.在命令行执行 WordCount 案例 -- hadoop fs -mkdir /input -- hadoop fs -put /etc/profile /input -- cd /opt/apps/hadoop/(自己的目录) -- bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /input/profile /output 7. mkdir: Cannot create directory /input. Name node is in safe mode. -- hadoop dfsadmin -safemode leave 8.关闭守护进程 -- stop-dfs.sh(第一台执行)
注意事项: 1. 如果第一步格式化 HDFS 失败,执行以下命令后重新格式化 -- rm -rf /opt/apps/hadoop/tmp 2. 如果第 3 步缺失守护进程,请重新执行第 2 步 3. 如果第 4 步无法正常访问网址,请检查 Linux 防火墙是否关闭 -- systemctl stop firewalld -- systemctl disable firewalld 这就完毕了,是不是很简单,有兴趣可以加QQ群:1011197972一起学习 |





 3. [root@hadoop001 hadoop]# vi yarn-env.sh(第23行,放开注释进行修改) -- export JAVA_HOME=/usr/apps/jdk/
3. [root@hadoop001 hadoop]# vi yarn-env.sh(第23行,放开注释进行修改) -- export JAVA_HOME=/usr/apps/jdk/ 5. [root@hadoop001 hadoop]#vi hdfs-site.xml dfs.replications 3 dfs.namenode.secondary.http-address hadoop002:50090
5. [root@hadoop001 hadoop]#vi hdfs-site.xml dfs.replications 3 dfs.namenode.secondary.http-address hadoop002:50090  6.[root@hadoop001 hadoop]# mv mapred-site.xml.template mapred-site.xml
6.[root@hadoop001 hadoop]# mv mapred-site.xml.template mapred-site.xml 7. [root@hadoop001 hadoop]#vi yarn-site.xml yarn.resourcemanager.hostname hadoop003 yarn.nodemanager.aux-services mapreduce_shuffle
7. [root@hadoop001 hadoop]#vi yarn-site.xml yarn.resourcemanager.hostname hadoop003 yarn.nodemanager.aux-services mapreduce_shuffle  8.[root@hadoop001 hadoop]# vi slaves hadoop01 hadoop02 hadoop03
8.[root@hadoop001 hadoop]# vi slaves hadoop01 hadoop02 hadoop03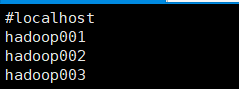


 -- 在浏览器输入 192.168.xx.x:8088(第三台IP地址)
-- 在浏览器输入 192.168.xx.x:8088(第三台IP地址)
 -- stop-yarn.sh(第三台执行)
-- stop-yarn.sh(第三台执行)
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |