编译原理(二)词法分析:3.记号的识别―NFA与DFA |
您所在的位置:网站首页 › dfa和nfa等价 › 编译原理(二)词法分析:3.记号的识别―NFA与DFA |
编译原理(二)词法分析:3.记号的识别―NFA与DFA
|
文章目录
一、NFA1.NFA的定义2.状态转换图(transition diagram)3.状态转换矩阵4.例题5.NFA的特点不确定性6.NFA识别输入序列的一般方法
二、DFA1.DFA的定义2.例题3.DFA的特征(确定性)4.算法2.1
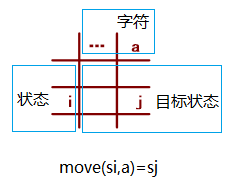
【编译原理博客列表】》》》》》》 两种有限自动机(FA,Finite Automation): NFA(Nondeterministic Finite Automata,不确定的有限自动机)DFA (Deterministic Finite Automata,确定的有限自动机)三种转化形式 定义状态转换图状态转换矩正规式与有限自动机从两个侧面表示正规集: 正规式是描述自动机是识别 一、NFA 1.NFA的定义M =(S,∑,move,s0,F) 左项: M:自动机( autoMata, Machine,)右项: S: M的状态集合(有限个元素)(the Set of States of M) ∑:M的字母表(the alphabet of M) 是由有限个字符(可以包括ε)构成的集合。M 仅能接受/识别其中字符; move: 状态转移函数(transition function) move(si,ch)=sj 表示 M 处在状态 si 时若遇到输入字符 ch,则转移到(下一)状态 sj。其中 ch 可以是 Σ 中的某个字符(包含 ε,它表示空字符/不需要输入); s0:initial state(start state),(唯一的)初态/开始状态。 s0是S中的元素,代表识别一个记号的开始; F: 终态集/接受状态集( final states / accepting states)。 F 是 S 的一个非空子集。识别记号时只要能够到达 F 中某个状态,则认为刚才扫描过的字符串可被 M 接受(即是一个记号)。 提示: (1)从定义可知,一个 NFA 的终态可以不唯一! (2)转移函数 move 实际上定义了这样一个映射关系: m o v e : S × ( Σ ∪ ϵ ) → T move: S ×( \Sigma \cup {\epsilon}) → T move:S×(Σ∪ϵ)→T 其中集合 T 是 S 的所有子集形成的集合,即 对于给定的一个状态 s 和一个字符 c,其下一状态可能不唯一,这就是“不确定”的表现。 理解: 不确定有限自动机中的有限是指 状态的数量 是有限的。 2.状态转换图(transition diagram)一个“有向图”: NFA中的每个状态,对应转换图中的一个节点;NFA中的每个move(si, a)=sj,对应转换图中的一条有向边;表示从节点si出发进入节点sj,字符a(或ε)是边上的标记。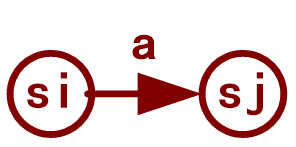
绘制状态转换图时应注意初态、终态的特别之处: 状态注意 NFA的初态 S0 对应的结点一定是图中唯一没有前驱状态的状态。且它必须由一个“不标记任何字符”的入边。 NFA的初态 S0 对应的结点一定是图中唯一没有前驱状态的状态。且它必须由一个“不标记任何字符”的入边。 为区分终态和非终态,一般将终态画为双圆或加粗的圆。 为区分终态和非终态,一般将终态画为双圆或加粗的圆。
注意: 画完圈,连完状态转换函数的关系后一定要记着给初态加进入→,给终态加双圈或加粗。 3.状态转换矩阵状态转换矩阵(也称为状态转换表, transition table)是这样一个二维表格: (1)行下标(状态)、列下标(字符 或 ε); 状态转换矩阵每行的行首表示状态集合S中的状态。状态转换矩阵每列的列首表示字母表∑中的字符。 字母表中的每个字符对应一列,可用该字符作为该列的列下标。若状态转移函数中存在经过 ε 的转移,则对应列下标用ε表示;(2)单元格中的目标状态 单元格 M[si, a] 内:填写状态转移 move(si, a) 的所有目标状态。在 NFA的矩阵中,采用集合方式书写(一对花括号)。在 DFA 的矩阵中,不用集合方式书写;NFA中没有对应的状态转移,则填写一个减号-(3)初态和终态 一般让初态对应第1行,而终态应在矩阵之外另行说明。 例2.7:识别正规式(a|b)*abb所描述正规集的NFA的三种表示形式分别如下。(其中转换矩阵表示中0为初态,3为终态) 定义: S={0, 1, 2, 3}, Σ={a, b} move={ move(0,a)=0, move(0,a)=1, move(0,b)=0, move(1,b)=2, move(2,b)=3 } s0 = 0, // 注意,初态只有一个,不用集合花括号 F={3} // 注意,终态集可能有多个终态,用集合花括号 状态转换矩阵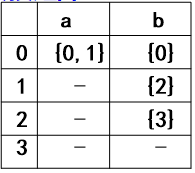 状态转换图 状态转换图 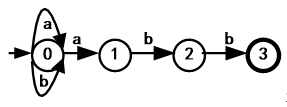 5.NFA的特点不确定性
5.NFA的特点不确定性
即在当前状态下对同一字符有多于一个的下一状态转移。 具体体现: 定义: move函数是1对多的;状态转换图:同一状态有多于一条边标记相同字符转移到不同的状态;状态转换矩阵: M[si,a]是一个状态的集合
不确定性识别记号的困惑 识别输入序列时,在当前状态下遇到同一字符,应转移到哪个下一状态? NFA识别记号存在的问题 只有尝试了全部可能的路径,才能确定一个输入序列不被接受,而这些路径的条数随着路径长度的增长成指数增长。识别过程中需要进行大量回溯,时间复杂度升高且算法趋于复杂。 6.NFA识别输入序列的一般方法反复试探所有路径,直到到达终态,或者到达不了终态。
DFA是NFA的一个特例,所以定义还是M =(S,∑,move,s0,F) 其中特殊在: (1)没有状态具有ε状态转移(ε-transition),即状态转换图中没有标记ε的边 (2)对每个状态s和每个字符a,最多有一个下一状态。 2.例题例2.10 正规式(a|b)*abb的DFA和识别输入序列abb和abab
算法2.1: s:=s0; ch:=nextchar; -- 初值 while ch≠eof -- 循环 loop s:=move(s,ch); ch:=nextchar; end loop; if s is in F -- 返回 then return "yes"; else return "no"; end if;
用算法2.1识别abb: 1. s=0, ch=a 2. s=1, ch=b 3. s=2, ch=b 4. s=3, ch=eof 5. yes用算法2.1识别abab: 1. s=0, ch=a 2. s=1, ch=b 3. s=2, ch=a 4. s=1, ch=b 5. s=2, ch=eof 6. no |


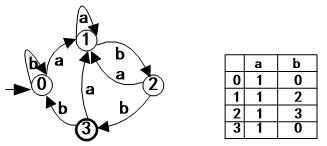 识别abb:0a1b2b3,接受 识别abab:0a1b2a1b2,拒绝
识别abb:0a1b2b3,接受 识别abab:0a1b2a1b2,拒绝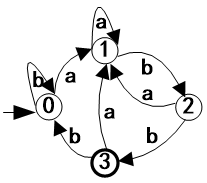
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |