IDM:连续超分辨率隐空间扩散模型 |
您所在的位置:网站首页 › ddpm模型 › IDM:连续超分辨率隐空间扩散模型 |
IDM:连续超分辨率隐空间扩散模型
文章名:Implicit Diffusion Models for Continuous Super-Resolution 文章链接 三月份最新的扩散模型超分辨率文章。 作者认为目前的超分辨率(SR)方法通常存在过渡平滑和伪影,且大多只能在固定放大倍率下工作,因此提出了一种隐式扩散模型(Implicit Diffusion Model, IDM),一种简单的端到端框架,具有有效的规模自适应调节机制和隐式扩散过程,可生成高保真分辨率连续输出。 一、模型架构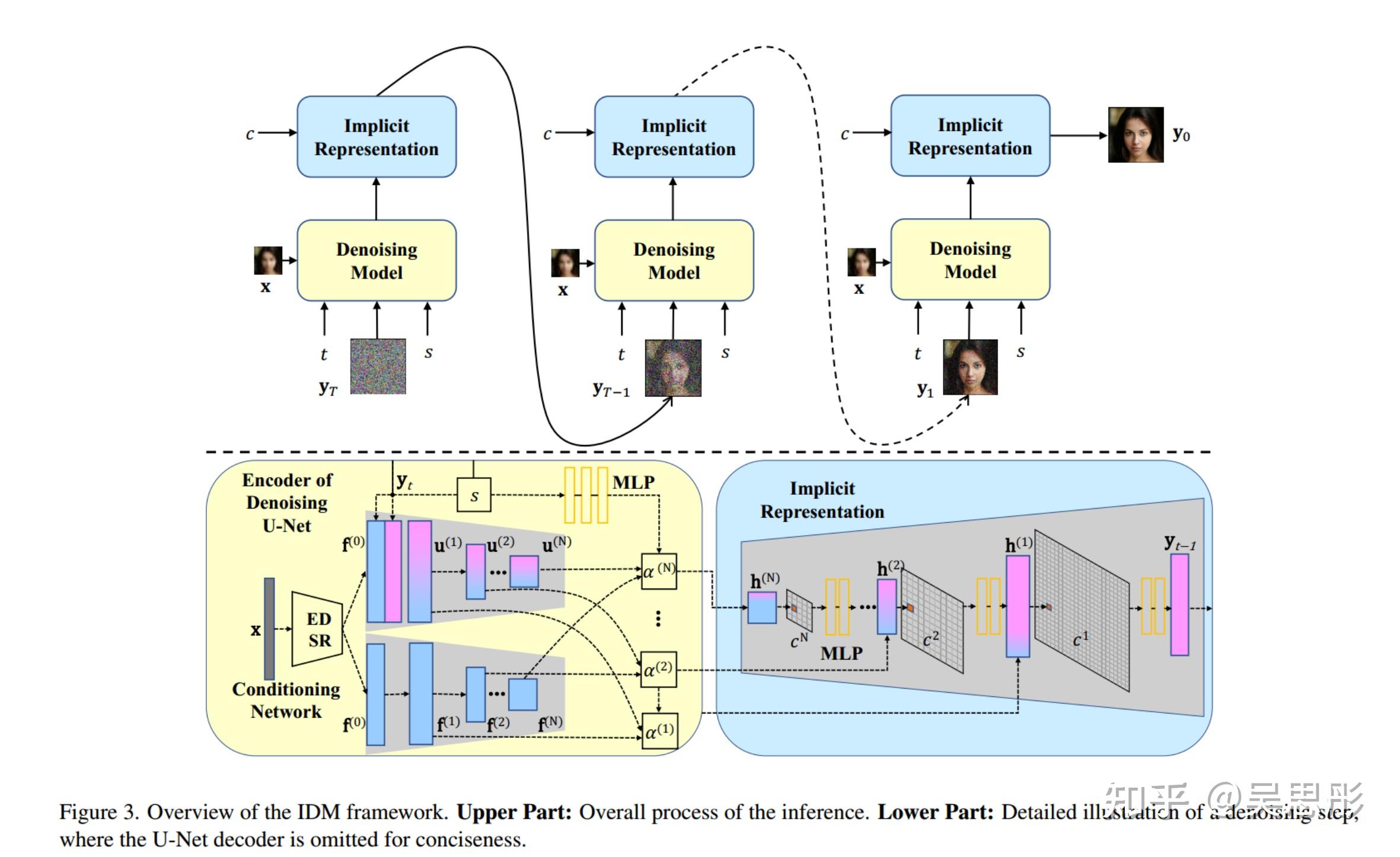 作者主体采用的普通DDPM的架构,模型为UNet。数据集image pair表示为 (\mathbf{x}_i,\mathbf{y}_i) 以及一个比例因子 s 。 x_i 是从 y_i 中退化得到, s 控制了输出的分辨率。总体公式可以概括为: p_{\theta}\left({\mathbf{y}}_{t-1}\mid{\mathbf{y}}_{t},{\mathbf{x}}\right)={\mathcal{N}}\left(\mathbf{y}_{t-1}\mid\mu_{\theta}\left(\mathbf{x},\mathbf{y}_{t},t\right),\sigma_{t}^{2}\mathbf{I}\right) 二、尺度自适应的条件机制LR条件网络采用了一个CNN网络来提取条件特征。作者使用了一个EDSR来建立初始SR特征 f^{(0)} ,并通过bilinear interpolation确保它与 y_t 的分辨率一致。最终将 f^{(0)} 与 y_t 进行concat并送进UNet。同时, f^{(0)} 还被送进CNN中被逐步下采样为: \mathbf f^{(i)}=\mathbf C\text{onv}\left(\mathbf f^{(i-1)}\right) 与基于gan的依赖额外先验的方法不同,此条件网络只提供编码的多分辨率特征。它将它们发送到U-Net,而不需要额外的先验来建模潜在的表征。 比例因子调制(Scaling Factor Modulation)。为了解除固定放大倍数的限制,作者引入了缩放因子 s 作为扩散过程的条件来使放大倍率具有连续的分辨率。首先定义一个区间(1,M],其中M为最大放大比,并在训练过程中从区间中随机选择 s 。然后根据 s 对 y_t 进行重塑,控制生成图像的分辨率,如图3中黄色部分所示。比例因子 s 用于调整调理网络的原始输入信息 f^{(i)} 与去噪网络的输出信息 u^i 的比值。如图三所示,没有使用cross-attention以及concat,作者将 s通过MLP 投影到一系列比例因子的集合 \alpha=\left\{\alpha_{1}^{(1)},\alpha_{2}^{(1)},\ldots,\alpha_{1}^{(i)},\alpha_{2}^{\left(i\right)},\ldots,{\alpha_{1}^{\left(N\right)},}\alpha_{2}^{(N)}\right\} ,其中 i 代表不同分辨率输出的深度序号。 随后 \alpha_1^{(i)}和\alpha_2^{(i)} 被L2标准化后用于调整 \textbf{f}^{(i)} 和 \textbf{u}^{(i)} 。具体过程为: \alpha=Reshape(\operatorname{MLP}(s)) \bar{\alpha}_1^{(i)}=\dfrac{\left|\alpha_1^{(i)}\right|}{\sqrt{\alpha_1^{(i)^2}+\alpha_2^{(i)^2} +\delta}} \bar{\alpha}_{2}^{(i)}=\dfrac{\left|\alpha_{2}^{(i)}\right|}{\sqrt{\alpha_{1}^{(i)^2}+\alpha_{2}^{{(i)}^2}+\delta}} \mathbf{h}^{(i)}=\bar{\alpha}_1^{(i)}\cdot{\mathbf{f}}^{(i)}+\bar{\alpha}_2^{(i)}\cdot\text{Concat}\left(\mathbf{u_{up}}^{(i)},\mathbf{u_{down}}^{(i)}\right) 其中 \delta=1e-8 用来避免分母为零。 \mathbf{u}_{\text{up}}{}^{(i)} 和 \mathbf{u}_{\text{down}}{}^{(i)} 分别是来自U-Net解码器和编码器的特征映射。最终结果如图三所示。 三、隐式神经表征(Implicit Neutral Representation)考虑到目前流行的SR方法往往受到复杂的级联或两阶段训练策略的影响,为了产生多个分辨率的输出,我们创新性使用了隐式神经表示来学习连续图像表示,简化了IDM。如图3蓝框所示,作者将几个基于坐标的mlp插入到U-Net架构的上采样中来参数化隐式神经表示,这可以在连续尺度范围内恢复高保真质量的LR图像。假设多分辨率特征作为参照的连续坐标为 c=\{c^{(1)},...,c^{(i)},...,c^{(N)}\} ,它是使用缩放因子 s 从去噪网络中获得的。输入当前的特征以及对应的坐标来计算目标特征,具体过程为: \mathbf{u}_{\mathrm{up}}^{(i)}=D_i\left(\hat{\mathbf{h}}^{(i+1)},c^{(i)}-\hat{c}^{(i+1)}\right) D 是一个两层的MLP, \hat{\mathbf{h}}^{(i+1)}和\hat{c}^{(i+1)} 通过计算 \mathbf{h}^{(i+1)}和c^{(i+1)} 在 i+1 深度的最近欧式距离(nearest Euclidean distance)来插值。 四、优化去噪模型的最终输出定位白噪声。同时,为了实现连续分辨率的输出,去噪模型 \epsilon_\theta(\mathbf{x},t,s,\tilde{\mathbf{y}}_t,\gamma_t) 应该通过训练适用于任何尺度并确保预测噪声的有效性。用如下公式进行优化: \mathbb{E}_{(\mathbf{x},\mathbf{y})}\mathbb{E}_{\epsilon,\gamma_t,t,s}\left\|\epsilon-\epsilon_\theta(\mathbf{x},t,s,\tilde{\mathbf{y}}_t,\gamma_t)\right\|_1^1 |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |