CCA Spark and Hadoop Developer Exam(CCA175)考试模拟题讲解一(每日一更两题) |
您所在的位置:网站首页 › cloudera考试内容 › CCA Spark and Hadoop Developer Exam(CCA175)考试模拟题讲解一(每日一更两题) |
CCA Spark and Hadoop Developer Exam(CCA175)考试模拟题讲解一(每日一更两题)
|
NO.1 CORRECT TEXT(第一题:正确文本) Problem Scenario 49 : You have been given below code snippet (do a sum of values by key}, with intermediate output.(问题场景49:下面给出了代码片段(按key进行求和),并提供中间输出。) val keysWithValuesList = Array("foo=A", "foo=A", "foo=A", "foo=A", "foo=B", "bar=C","bar=D", "bar=D") val data = sc.parallelize(keysWithValuesList) //Create key value pairs(创建键值对) val kv = data.map(_.split("=")).map(v => (v(0), v(1))).cache() val initialCount = 0 val countByKey = kv.aggregateByKey(initialCount)(addToCounts, sumPartitionCounts) Now define two functions (addToCounts, sumPartitionCounts) such, which will produce following results.(现在定义两个这样的变量(addToCounts、sumPartitionCounts),它将产生以下结果。) Output 1:(输出1:) countByKey.collect() res0: Array[(String, Int)] = Array((foo,5), (bar,3)) import scala.collection._ val initialSet = scala.collection.mutable.HashSet.empty[String] val uniqueByKey = kv.aggregateByKey(initialSet)(addToSet, mergePartitionSets) Now define two functions (addToSet, mergePartitionSets) such, which will produce following results.(现在定义两个这样的变量(addToSet,mergePartitionSets),这将产生以下结果。) Output 2:(输出2:) uniqueByKey.collect() res1: Array[(String, scala.collection.mutable.HashSet[String])] = Array((foo,Set(B, A}},(bar,Set(C, D}}} Answer:(答) See the explanation for Step by Step Solution and configuration.(请参阅逐步解决方案和配置的说明。) Explanation:(说明:) Solution :(解决方案) val addToCounts = (n: Int, v: String) => n + 1 val sumPartitionCounts = (p1: Int, p2: Int) => p1 + p2 val addToSet = (s: mutable.HashSet[String], v: String) => s += v val mergePartitionSets = (p1: mutable.HashSet[String], p2: mutable.HashSet[String]) => p1 ++= p2 解析: 针对output1解析: val keysWithValuesList = Array("foo=A", "foo=A", "foo=A", "foo=A", "foo=B", "bar=C","bar=D", "bar=D") val data = sc.parallelize(keysWithValuesList) //Create key value pairs(创建键值对) val kv = data.map(_.split("=")).map(v => (v(0), v(1))).cache() val initialCount = 0 以上代码题中已给出的,到这里需要你定义两个变量(addToCounts, sumPartitionCounts,从下面题中给出的已知代码可知是这两个变量),不然下面一行执行会报错。 val countByKey = kv.aggregateByKey(initialCount)(addToCounts, sumPartitionCounts) 解答:缺失的代码如下(也是你要填写的代码) val addToCounts = (n: Int, v: String) => n + 1 val sumPartitionCounts = (p1: Int, p2: Int) => p1 + p2 继续执行题中给出的已知代码: val countByKey = kv.aggregateByKey(initialCount)(addToCounts, sumPartitionCounts) countByKey.collect() 结果:Array[(String, Int)] = Array((foo,5), (bar,3)) 针对output2解析: import scala.collection._ val initialSet = scala.collection.mutable.HashSet.empty[String] 以上代码题中已给出的,到这里需要你定义两个变量(addToSet,mergePartitionSets,从下面题中给出的已知代码可知是这两个变量),不然下面一行执行会报错。 val uniqueByKey = kv.aggregateByKey(initialSet)(addToSet, mergePartitionSets) 解答:缺失的代码如下(也是你要填写的代码) val addToSet = (s: mutable.HashSet[String], v: String) => s += v val mergePartitionSets = (p1: mutable.HashSet[String], p2: mutable.HashSet[String]) => p1 ++= p2 注意:这里的”++=”不可以有空格,不然会报错,具体原因,以后讲解spark的时候详细介绍 继续执行题中给出的已知代码: val uniqueByKey = kv.aggregateByKey(initialSet)(addToSet, mergePartitionSets) uniqueByKey.collect() 结果:Array[(String, scala.collection.mutable.HashSet[String])] = Array((foo,Set(B, A}},(bar,Set(C, D}}} 执行步骤如下图:红色框中的是要补充的代码,绿色框中的是执行结果
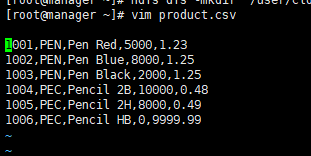
NO.2 CORRECT TEXT(第二题:正确文本) Problem Scenario 81 : You have been given MySQL DB with following details. You have been given following product.csv file product.csv (问题场景81:MySQL数据库提供了以下详细信息。你已经得到如下product.csv文件) productID,productCode,name,quantity,price 1001,PEN,Pen Red,5000,1.23 1002,PEN,Pen Blue,8000,1.25 1003,PEN,Pen Black,2000,1.25 1004,PEC,Pencil 2B,10000,0.48 1005,PEC,Pencil 2H,8000,0.49 1006,PEC,Pencil HB,0,9999.99 Now accomplish following activities.(现在完成以下活动(任务)。) 1 . Create a Hive ORC table using SparkSql(使用SparkSql创建Hive ORC表) 2 . Load this data in Hive table.(把数据加载到hive表) 3 . Create a Hive parquet table using SparkSQL and load data in it.(使用SparkSQL创建Hive parquet表并把数据加载进去) Answer:(答) See the explanation for Step by Step Solution and configuration.(请参阅逐步解决方案和配置的说明) Explanation:(说明) Solution :(解决方案) Step 1 : Create this tile in HDFS under following directory (Without header)(在HDFS上创建如下目录(没有header)) /user/cloudera/he/exam/task1/ 在Linux创建product.csv文本 [root@manager ~]# vim product.csv
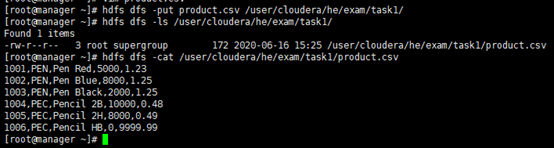
创建hdfs目录: [root@manager ~]# hdfs dfs -mkdir /user/cloudera/he/exam/task1/
上传csv文件到hdfs目录: [root@manager ~]# hdfs dfs -put product.csv /user/cloudera/he/exam/task1/
Step 2 : Now using Spark-shell read the file as RDD(现在使用Spark shell将文件读取为RDD) // load the data into a new RDD(将数据加载到新的RDD中) val products = sc.textFile("/user/cloudera/he/exam/task1/product.csv") // Return the first element in this RDD(返回此RDD中的第一个元素) products.first() Step 3 : Now define the schema using a case class(现在使用case class定义模式) case class Product(productid: Integer, code: String, name: String, quantity:Integer, price:Float) Step 4 : create an RDD of Product objects(创建Product对象RDD) val prdRDD = products.map(_.split(",")).map(p =>Product(p(0).toInt,p(1),p(2),p(3).toInt,p(4).toFloat)) prdRDD.first() prdRDD.count() Step 5 : Now create data frame (现在创建分布式数据集) val prdDF = prdRDD.toDF() Step 6 : Now store data in hive warehouse directory. (However, table will not be created )(现在将数据存储在hive仓库目录中。(但是,不会创建表)我这里有数据,可能是我的环境与考试环境、参数不同导致,如果没有数据按照Step7、Step9执行) import org.apache.spark.sql.SaveMode prdDF.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("product_orc_table") Step 7: Now create table using data stored in warehouse directory. With the help of hive.(在hive命令行的帮助下,使用存储在仓库目录中的数据创建表) hive show tables;
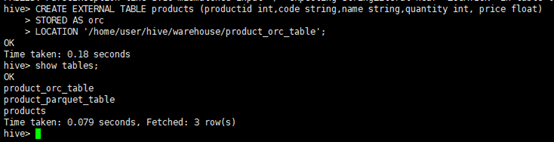
hive> CREATE EXTERNAL TABLE products (productid int,code string,name string,quantity int, price float) > STORED AS orc > LOCATION '/home/user/hive/warehouse/product_orc_table';
Step 8 : Now create a parquet table(现在创建一个parquet表) import org.apache.spark.sql.SaveMode prdDF.write.mode(SaveMode.Overwrite).format("parquet").saveAsTable("product_parquet_table")
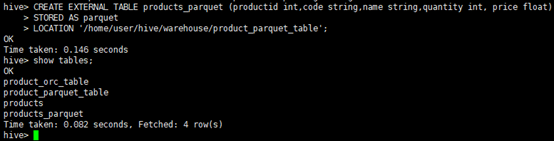
Step 9 : Now create table using this(用如下命令创建parquet表) hive> CREATE EXTERNAL TABLE products_parquet (productid int,code string,name string,quantity int, price float) > STORED AS parquet > LOCATION '/home/user/hive/warehouse/product_parquet_table';
Step 10 : Check data has been loaded or not.(检查数据是否已加载) Select * from products; Select * from products_parquet;
|




【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |