【2024年最新】Bilibili/B站视频/动态评论爬虫 |
您所在的位置:网站首页 › b站怎么关闭自己视频的评论区 › 【2024年最新】Bilibili/B站视频/动态评论爬虫 |
【2024年最新】Bilibili/B站视频/动态评论爬虫
|
废话不多说,直接先放git仓库:GitHub - linyuye/Bilibili_crawler: bilibili爬虫,基于selenium获取oid与cookie,request获取api内容 〇:概念简述oid:视频/动态的uuid,b站对于发布内容的通用唯一识别码 cookie:内含个人登录信息,爬虫头必需 其余内容请看该文档含义: bilibili-API-collect/docs/comment/list.md at master · SocialSisterYi/bilibili-API-collect · GitHub哔哩哔哩-API收集整理【不断更新中....】. Contribute to SocialSisterYi/bilibili-API-collect development by creating an account on GitHub. 首先,让我们了解,动态网站/静态网站的区别: 动态网站除了要设计网页外,还要通过数据库和编程序来使网站具有更多自动的和高级的功能。动态网站体现在网页一般是以asp,jsp,php,aspx等技术,而静态网页一般是HTML(标准通用标记语言的子集)结尾,动态网站服务器空间配置要比静态的网页要求高,费用也相应的高,不过动态网页利于网站内容的更新,适合企业建站。动态是相对于静态网站而言。——百度百科 通俗来说,就是网页内容是否写在网站源代码里面的区别。 以编写日期时,bilibili每周必看视频榜一为例:https://www.bilibili.com/video/BV1ay411h74i/ 对于第一条评论:
api分析来源:GitHub - SocialSisterYi/bilibili-API-collect: 哔哩哔哩-API收集整理【不断更新中....】哔哩哔哩-API收集整理【不断更新中....】. Contribute to SocialSisterYi/bilibili-API-collect development by creating an account on GitHub. https://github.com/SocialSisterYi/bilibili-API-collect/blob/master/docs/comment/list.md 通过翻阅上述API文档,我们得知,使用正常API获取评论,在页数到达400页之后无法返回内容,好在b站提供了一个懒加载api能够爬取所有内容。 https://api.bilibili.com/x/v2/reply/main懒加载api,无需wbi签名 https://api.bilibili.com/x/v2/reply/reply获取子评论的api 对评论区请求需要以下data数据:(1为评论,2为子评论) 参数名类型内容必要性备注access_keystrAPP 登录 TokenAPP 方式必要typenum评论区类型代码必要类型代码见表oidnum目标评论区 id必要modenum排序方式非必要默认为 3 0 3:仅按热度 1:按热度+按时间 2:仅按时间nextnum评论页选择非必要按热度时:热度顺序页码(0 为第一页) 按时间时:时间倒序楼层号 默认为 0psnum每页项数非必要默认为 20 定义域:1-30 access_keystrAPP登录 TokenAPP 方式必要typenum评论区类型代码必要类型代码见表oidnum目标评论区 id必要rootnum根回复 rpid必要psnum每页项数非必要默认为20 定义域:1-49 但 data_replies 的最大内容数为20,因此设置为49其实也只会有20条回复被返回pnnum页码非必要默认为1 data_2 = { 二级评论的data 'type': type, # 类型 'oid': oid, # 原视频/动态oid 'ps': ps, # 每页含有条数,不能大于20 'pn': str(page_pn), # 二级评论页数,需要转换为字符串 'root': rpid # 一级评论的rpid } 三:爬虫使用了request库,对api访问,解析返回数据 for comment in json_data['data']['replies']: count = comment['rcount'] rpid = str(comment['rpid']) name = comment['member']['uname'] sex = comment['member']['sex'] ctime = comment['ctime'] dt_object = datetime.datetime.fromtimestamp(ctime, datetime.timezone.utc) formatted_time = dt_object.strftime('%Y-%m-%d %H:%M:%S') + ' 北京时间' # 可以加上时区信息,但通常不需要 like = comment['like'] message = comment['content']['message'].replace('\n', ',') # 检查是否存在 location 字段 location = comment['reply_control'].get('location', '未知') # 如果不存在,使用 '未知' location = location.replace('IP属地:', '') if location else location current_level = comment['member']['level_info']['current_level'] mid = str(comment['member']['mid']) 四:小白化处理因为对于小白来说,获取cookie和oid比较困难,所以使用了selenium库,自动抓包自己的cookie和视频/动态oid last_request = None # 遍历所有请求 for request in driver.requests: if "main?oid=" in request.url and request.response: # 更新last_request为当前请求 last_request = request # 检查是否找到了符合条件的请求 if last_request: print("URL:", last_request.url) # 从URL中提取oid parsed_url = urlparse(last_request.url) query_params = parse_qs(parsed_url.query) oid = query_params.get("oid", [None])[0] type = query_params.get("type", [None])[0] print("OID:", oid) print("type:", type) 五:完整代码 from seleniumwire import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.by import By import time from urllib.parse import urlparse, parse_qs import requests from requests.adapters import HTTPAdapter from requests.packages.urllib3.util.retry import Retry import csv import pytz import datetime from fake_useragent import UserAgent import random options = { 'ignore_http_methods': ['GET', 'POST'], # 提取XHR请求,通常为GET或POST。如果你不希望忽略任何方法,可以忽略此选项或设置为空数组 'custom_headers': { 'X-Requested-With': 'XMLHttpRequest' # 筛选XHR请求 } } # 配置Selenium chrome_options = Options() chrome_service = Service("前面是你这个文件夹的绝对路径\\venv\\chrome-win64\\chromedriver.exe") driver = webdriver.Chrome(service=chrome_service, options=chrome_options) # 打开目标网页,改成你想爬的网页,直接是网址就行 driver.get("https://www.bilibili.com/video/BV1WM4m1Q75H/") login_div = driver.find_element(By.XPATH, "//div[contains(@class, 'right-entry__outside') and contains(@class, 'go-login-btn')]") login_div.click() time.sleep(5) # 注意替换下面的选择器以匹配你要自动登录的网站 username_input = driver.find_element(By.XPATH, "//input[@placeholder='请输入账号']") password_input = driver.find_element(By.XPATH, "//input[@placeholder='请输入密码']") login_button = driver.find_element(By.XPATH, "//div[contains(@class,'btn_primary') and contains(text(),'登录')]") #第一个写账号,第二个写密码 username_input.send_keys("") password_input.send_keys("") # 点击登录按钮 time.sleep(5) # login_button.click() # 等待几秒确保登录成功 driver.implicitly_wait(10) # 替换为你需要的等待时间 # 等待页面加载完成(根据实际情况调整时间或使用更智能的等待方式) time.sleep(5) driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(5) driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 获取捕获的网络请求 # 初始化一个变量,用来保存最后一个符合条件的请求 last_request = None # 遍历所有请求 for request in driver.requests: if "main?oid=" in request.url and request.response: # 更新last_request为当前请求 last_request = request # 检查是否找到了符合条件的请求 if last_request: print("URL:", last_request.url) # 从URL中提取oid parsed_url = urlparse(last_request.url) query_params = parse_qs(parsed_url.query) oid = query_params.get("oid", [None])[0] type = query_params.get("type", [None])[0] print("OID:", oid) print("type:", type) # 从WebDriver中获取所有cookies all_cookies = driver.get_cookies() cookies_dict = {cookie['name']: cookie['value'] for cookie in all_cookies} cookies_str = '; '.join([f"{name}={value}" for name, value in cookies_dict.items()]) # 从cookies中获取bili_jct的值 bili_jct = cookies_dict.get('bili_jct', '') print("bili_jct:", bili_jct) sessdata = cookies_dict.get('SESSDATA', '') print("SESSDATA:", sessdata) # 打印请求头 response = last_request.response driver.quit() # 重试次数限制 MAX_RETRIES = 5 # 重试间隔(秒) RETRY_INTERVAL = 10 file_path_1 = 'comments/主评论_1.1.csv' file_path_2 = 'comments/二级评论_1.2.csv' beijing_tz = pytz.timezone('Asia/Shanghai')#时间戳转换为北京时间 ua=UserAgent()#创立随机请求头 ps= 20 down = 1 #开始爬的页数a up = 30#结束爬的页数 one_comments = [] all_comments = []#构造数据放在一起的容器 总共评论,如果只希望含有一级评论,请注释 line 144 all_2_comments = []#构造数据放在一起的容器 二级评论 comments_current = [] comments_current_2 = [] # 将所有评论数据写入CSV文件 with open(file_path_1, mode='a', newline='', encoding='utf-8-sig') as file: writer = csv.writer(file) writer.writerow(['昵称', '性别', '时间', '点赞', '评论', 'IP属地','二级评论条数','等级','uid','rpid']) writer.writerows(all_comments) with open(file_path_2, mode='a', newline='', encoding='utf-8-sig') as file:#二级评论条数 writer = csv.writer(file) writer.writerow(['昵称', '性别', '时间', '点赞', '评论', 'IP属地','二级评论条数,条数相同说明在同一个人下面','等级','uid','rpid']) writer.writerows(all_2_comments) with requests.Session() as session: retries = Retry(total=3, # 最大重试次数,好像没有这个函数 backoff_factor=0.1, # 间隔时间会乘以这个数 status_forcelist=[500, 502, 503, 504]) for page in range(down, up + 1): for retry in range(MAX_RETRIES): try: headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',#'ua.random',#随机请求头,b站爸爸别杀我,赛博佛祖保佑 'Cookie': cookies_str, 'SESSDATA': sessdata, 'csrf' : bili_jct, } url = 'https://api.bilibili.com/x/v2/reply?'#正常api,只能爬8k url_long = 'https://api.bilibili.com/x/v2/reply/main'#懒加载api,理论无上限 url_reply = 'https://api.bilibili.com/x/v2/reply/reply'#评论区回复api #示例:https://api.bilibili.com/x/v2/reply/main?next=1&type=1&oid=544588138&mode=3(可访问网站) data = { 'next':str(page), # 页数,需要转换为字符串,与pn同理,使用懒加载api 'type': type, # 类型 11个人动态 17转发动态 视频1) 'oid': oid, #id,视频为av,文字动态地址栏id,可自查 'ps':ps, #(每页含有条数,不能大于20)用long的话不能大于30 'mode': '3' #3为热度 0 3:仅按热度 1:按热度+按时间 2:仅按时间 使用懒加载api } proxies = { #"http": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel}, #"https": "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password, "proxy": tunnel} #代理ip来源:https://www.kuaidaili.com/free/inha/ } prep = session.prepare_request(requests.Request('GET', url_long, params=data, headers=headers)) print(prep.url) response = session.get(url_long, params=data, headers=headers) # 检查响应状态码是否为200,即成功 if response.status_code == 200: json_data = response.json()#获得json数据 if 'data' in json_data and 'replies' in json_data['data']: #以下为核心内容,爬取的数据 for comment in json_data['data']['replies']: #one_comments.clear() count = comment['rcount'] rpid = str(comment['rpid']) name = comment['member']['uname'] sex = comment['member']['sex'] ctime = comment['ctime'] dt_object = datetime.datetime.fromtimestamp(ctime, datetime.timezone.utc) formatted_time = dt_object.strftime('%Y-%m-%d %H:%M:%S') + ' 北京时间' # 可以加上时区信息,但通常不需要 like = comment['like'] message = comment['content']['message'].replace('\n', ',') # 检查是否存在 location 字段 location = comment['reply_control'].get('location', '未知') # 如果不存在,使用 '未知' location = location.replace('IP属地:', '') if location else location # 将提取的信息追加到列表中 current_level = comment['member']['level_info']['current_level'] mid = str(comment['member']['mid']) all_comments.append([name, sex, formatted_time, like, message, location,count,current_level,mid,rpid]) comments_current.append([name, sex, formatted_time, like, message, location, count, current_level,mid,rpid]) with open(file_path_1, mode='a', newline='', encoding='utf-8-sig') as file: writer = csv.writer(file) writer.writerows(all_comments) all_comments.clear() #每次结束,重置计数器 if(count != 0): print(f"在第{page}页中含有二级评论,该条回复下面总共含有{count}个二级评论") total_pages = ((count // 20 ) +2) if count > 0 else 0 for page_pn in range(total_pages): data_2 = { # 二级评论的data 'type': type, # 类型 'oid': oid, # id 'ps': ps, # 每页含有条数,不能大于20 'pn': str(page_pn), # 二级评论页数,需要转换为字符串 'root': rpid # 一级评论的rpid } if page_pn == 0: continue response = session.get(url_reply, params=data_2, headers=headers, proxies=proxies) prep = session.prepare_request(requests.Request('GET', url_reply, params=data_2, headers=headers)) print(prep.url) if response.status_code == 200: json_data = response.json() # 获得json数据 if 'data' in json_data and 'replies' in json_data['data']: if not json_data['data']['replies']: # 检查replies是否为空,如果为空,跳过这一页 print(f"该页replies为空,没有评论") continue for comment in json_data['data']['replies']: rpid = str(comment['rpid']) name = comment['member']['uname'] sex = comment['member']['sex'] ctime = comment['ctime'] dt_object = datetime.datetime.fromtimestamp(ctime,datetime.timezone.utc) formatted_time = dt_object.strftime('%Y-%m-%d %H:%M:%S') + ' 北京时间' # 可以加上时区信息,但通常不需要 like = comment['like'] message = comment['content']['message'].replace('\n', ',') # 检查是否存在 location 字段 location = comment['reply_control'].get('location','未知') # 如果不存在,使用 '未知' location = location.replace('IP属地:', '') if location else location current_level = comment['member']['level_info']['current_level'] mid = str(comment['member']['mid']) all_2_comments.append([name, sex, formatted_time, like, message, location, count,current_level,mid,rpid]) comments_current_2.append([name, sex, formatted_time, like, message, location, count,current_level,mid,rpid]) with open(file_path_2, mode='a', newline='',encoding='utf-8-sig') as file: # 二级评论条数 writer = csv.writer(file) writer.writerows(all_2_comments) all_2_comments.clear() else: #print(f"在第{page_pn + 1}页的JSON响应中缺少 'data' 或 'replies' 键。跳过此页。") print(f"在页面{page}下第{page_pn + 1}条评论没有子评论。") else: print(f"获取第{page_pn + 1}页失败。状态码: {response.status_code}") random_number = random.uniform(0.2, 0.3) time.sleep(random_number) print(f"已经爬取第{page}页. 状态码: {response.status_code} ") else: print(f"在页面 {page} 的JSON响应中缺少 'data' 或 'replies' 键。跳过此页。") else: print(f"获取页面 {page} 失败。状态码: {response.status_code} 即为失败,请分析原因并尝试重试") random_number = random.uniform(0.2, 0.3) print(random_number) time.sleep(random_number) break except requests.exceptions.RequestException as e: print(f"连接失败: {e}") if retry < MAX_RETRIES - 1: print(f"正在重试(剩余尝试次数:{MAX_RETRIES - retry - 1})...") time.sleep(RETRY_INTERVAL) # 等待一段时间后重试 else: raise # 如果达到最大重试次数,则抛出原始异常 |
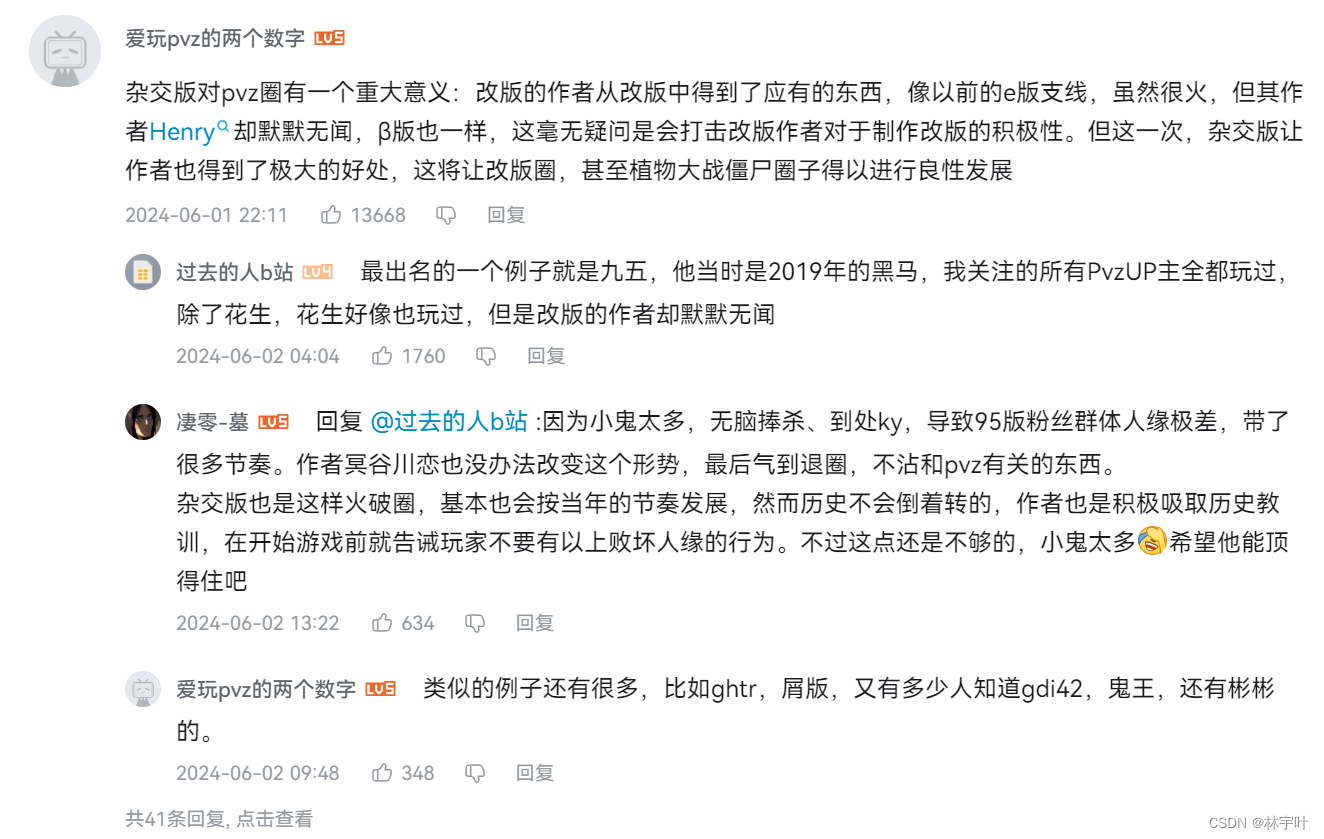
 在网页源代码中不存在,所以数据是从后端/数据库返回的,那么我们就可以通过查看网络请求。发现数据在main?oid这里面返回得到,至此,我们知道了评论是从哪里返回的。
在网页源代码中不存在,所以数据是从后端/数据库返回的,那么我们就可以通过查看网络请求。发现数据在main?oid这里面返回得到,至此,我们知道了评论是从哪里返回的。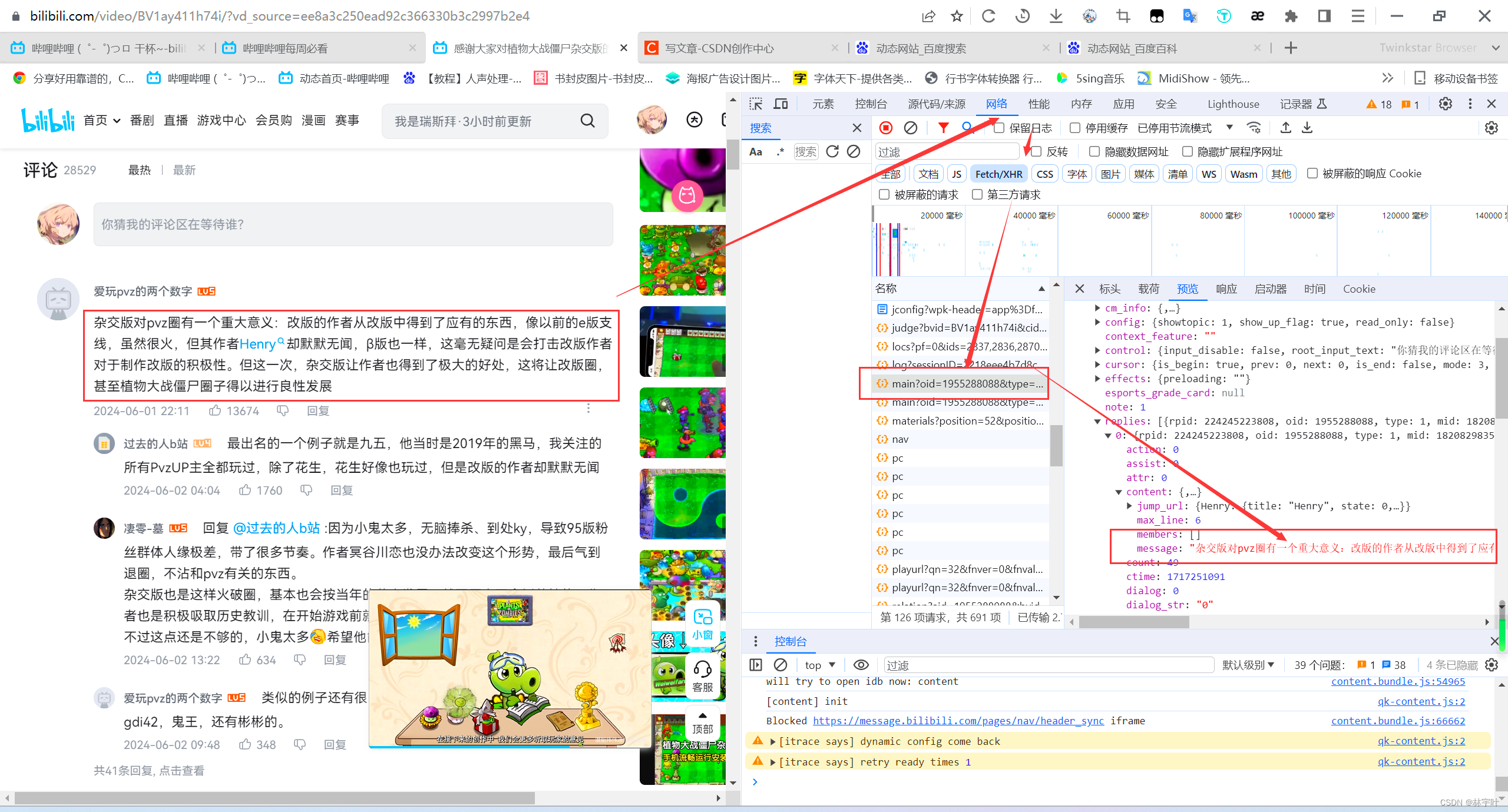

【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |