Meta系列 (一):效应值选取 |
您所在的位置:网站首页 › ar值是效应量吗 › Meta系列 (一):效应值选取 |
Meta系列 (一):效应值选取
|
Meta系列 |(一)效应值选取
简介
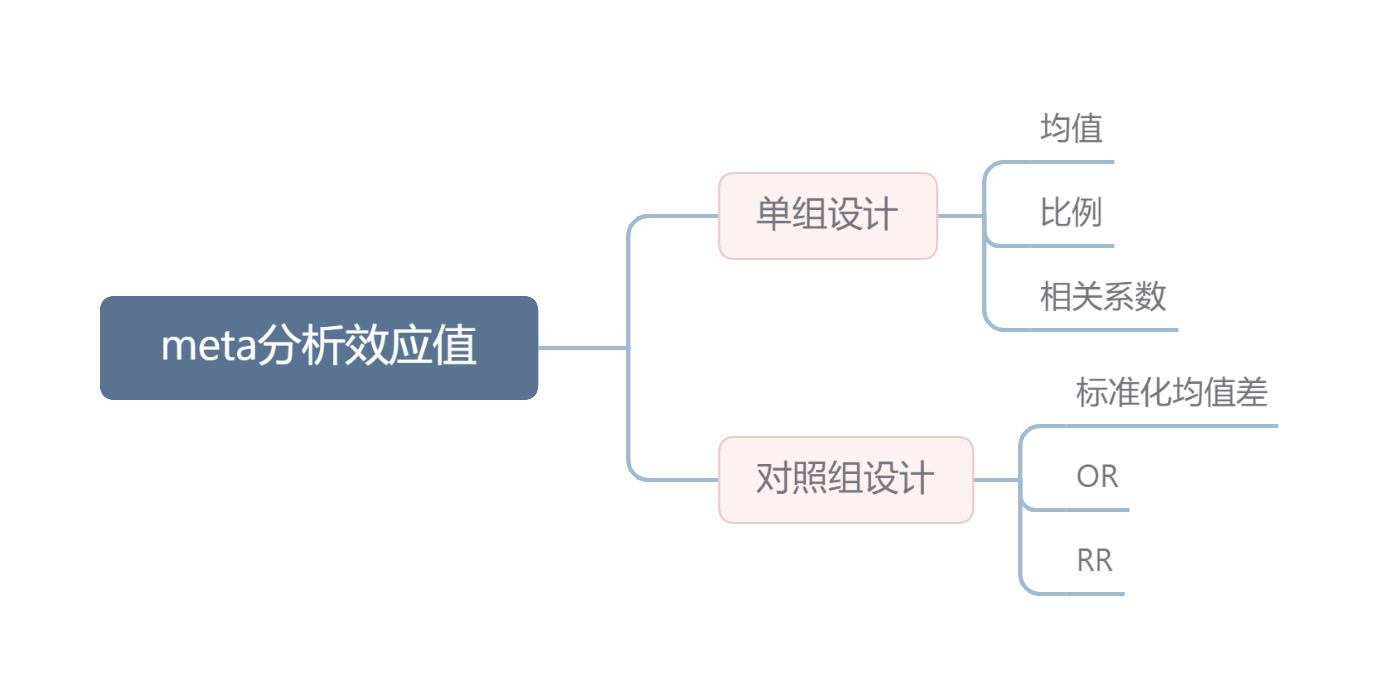
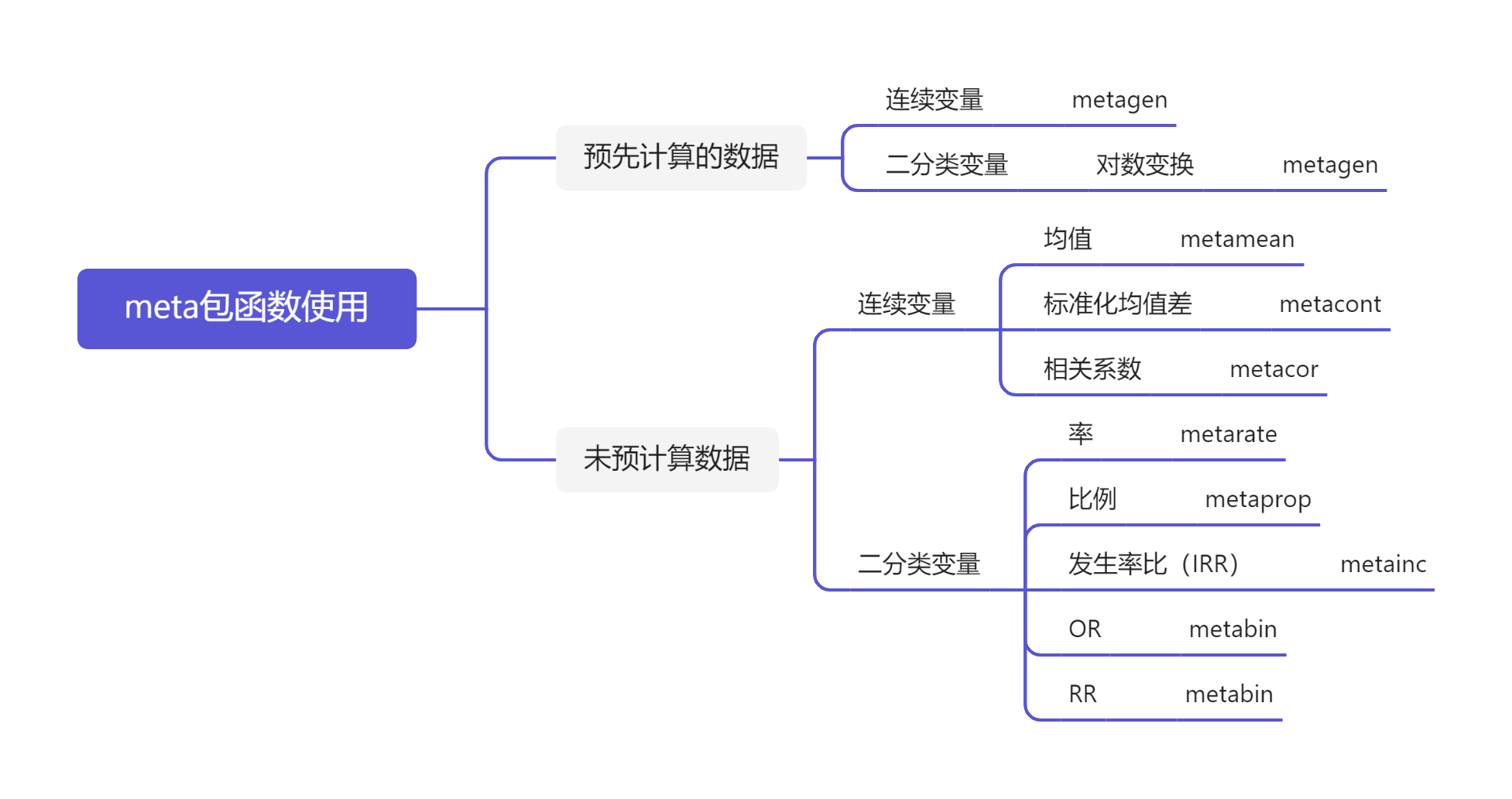
在meta分析过程中,第一步就是了解我们自己的效应值是什么,理解随机效应模型和固定效应模型的基本概念,以及如何选择。明白之后就是利用具体的统计工具计算效应值的大小。 1 Meta分析效应值在meta分析过程中,选取meta的效应值是第一步。效应大小被定义为是量化两实体之间关系的指标,包含方向和大小。如果这些关系表示为相同的效应值,则可以比较他们。不同的研究者可能对其有不同的定义。效应值有时会让人误解,对于干预性研究而言,效应大小通常是指治疗效果以及效果有多大。但是一些集中趋势,如均值,尽管没有’效应‘的概念,但我们仍然称之为效应值。 具体的效应值如下: meta分析的关键点是必须找到一个可以在所有研究中总结的效应量。效应值的选择对meta分析的结果和可解释性会产生重要影响。因此,效应值的选择必须遵循一些准则: 1 可比。对于meta分析而言,效应值测量在所有研究中具有相同的含义。以数学测试为例,当研究使用不同的测试时,将实验组和对照组的数学等分差异汇总起来毫无意义。 2 可计算。 3 可靠。即使所有的效应值都可计算,我们也使其可以汇总统计,也就是至少需要知道效应值的标准误差。 4 可解释。我们选择的效应值类型能够回答我们关注的研究问题。例如,如果我们对两个连续变量之间的关联强度感兴趣,通常使用相关性来表示效应的大小。解释相关性的大小相对简单,许多研究者可以理解它们。在后续的分析中,我们有时面临一种情况:无法使用既易于解释又非常适合我们统计计算的结果度量。在这种情况下,有必要在汇总效应值之前将其转换为易于分析的数学格式。 3 固定效应模型和随机效应模型在统计学中有各种各样的模型,统计模型试图解释数据产生的机制,特别是这种机制无法直接观察时,统计模型模拟数据的产生,并且使用数学公式以理想化的方式描述周围的世界。而Meta分析就是找到一种模型,可以评估研究背后真实效应的大小。因此,Meta分析必须解释观察到的研究结果差异的原因和程度。固定效应模型和随机效应模型基于不同的假设,试图回答效应的大小的差异。 3.1 固定效应模型固定效应模型假设:所有研究都来自于同质总体,效应大小的差异是由于抽样误差导致的,即我们估计的效应大小实际上是一个固定值。 基于此假设,效应大小的差别是由于抽样误差。我们知道,样本量越大,标准误越小,意味着抽样误差较小,因此,相比于标准误差大的研究,标准误差小的研究能更好估计真实的总体效应值。这也意味着,在固定效应模型中,样本量越大,标准误越小的研究会赋予越大的权重(逆方差加权)。 3.2 随机效应模型固定效应模型常常会使研究者产生疑惑:所有的研究都是同质的吗?这显然不可能。不同的研究,尽管研究主题相同,也可能存在一些差异,如治疗方式不同,或者治疗的强度和时间长度不同。可以预见的,研究间存在很大的异质性。 因此,随机效应模型假设不仅存在效应的真实值,更存在一个效应值大小的分布。即效应值大小的误差不仅来源于抽样误差,也来源于效应值本身的变异(方差)。因此,随机效应模型不是估计所有研究的真实效应量,而是估计真实效应分布的平均值。 3.3 我该选择哪种模型在许多研究领域中,选用随机效应模型是约定俗成的。由于研究间总是可以预见的存在不同的程度的异质性。而固定效应模型只有在无法检测到研究之间的异质性,并有充分的理由假设真实效应固定时才使用。 尽管使用随机效应模型是惯例,但并非无可争议。随机效应模型更关注小型研究,而小型研究往往是充满偏倚,这也是为何有时固定效应模型更加可取的原因。 3.4 异质性评估在随机效应模型中,我们必须估计真实效应大小的方差: τ 2 \tau^2 τ2 tau方的估计方式有许多种,在R中的‘meta’包可以选择不同的估计方法: 'DL' #DerSimonian-Laird () estimator "REML""ML" #Restricted Maximum Likelihood () or Maximum Likelihood () 'PM'#Paule-Mandel () procedure 'EB' #Empirical Bayes () 'SJ' #Sidik-Jonkman ()不同的估计方法依研究数量和研究中的样本量而异。DL法是常用的方法,也是meta包默认的方法。对于大部分研究者而言,并不需要知道每种估计方法的具体原理,只需要了解方法选择即可。 估计方法的选择: 1 对于连续的效应量可以选用’REML’或’ML’作为开始时使用的估计方法 2 对于二元效应大小,PM法是首选,前提是样本量没有极端变化 3 如果有足够的的理由人为样本中效应的异质性十分大,且避免误报具有十分高的优先级,则使用SJ 4 如果您希望有别的研究者在其他软件上也能精确复制你的结果则使用DL 4 Meta分析效应值计算了解了效应量和统计模型的基本区别之后,就可以上手操作了。在meta包中,我们用思维导图概括了不同的效应值使用不同的计算函数。 在前文中,我们看到,meta分析假设效应值产生差异主要源于抽样误差。但是,这种假设往往过于简单。在前文的假设中,随着抽样误差的减小,效应值的估计量是收敛于真实效应值的。但是,当存在系统误差时,结果往往与预想不同。这些偏倚有不同的产生原因:如计算指标本身的一些数学特性,或研究方式等。一种方法是评估研究的偏倚风险,然后判断偏倚风险是否与效应值相关(如亚组分析)。而另一种方式是处理由于计算指标的统计特性而引起的偏倚,我们需要采用统计学校正其带来的偏倚。下面介绍三种效应值的校正过程。 5.1 小样本偏差我们知道有个效应值是标准化均差(standardized mean differences, SMDs):当两组的结果数据是连续变量时,计算的效应值。当研究样本量较小时(尤其是n |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |