P |
您所在的位置:网站首页 › and是什么意思呀 › P |
P
|
生物信息学习的正确姿势 NGS系列文章包括NGS基础、在线绘图、转录组分析 (Nature重磅综述|关于RNA-seq你想知道的全在这)、ChIP-seq分析 (ChIP-seq基本分析流程)、单细胞测序分析 (重磅综述:三万字长文读懂单细胞RNA测序分析的最佳实践教程)、DNA甲基化分析、重测序分析、GEO数据挖掘(典型医学设计实验GEO数据分析 (step-by-step))、批次效应处理等内容。 单次检验的I类错误假设检验是用于检验统计假设的一种方法,其基本思想是“小概率事件”原理,即小概率事件在一次试验中基本上不会发生。 假设检验的基本方法是提出一个空假设(null hypothesis),也叫做原假设或无效假设,符号是H0。一次检验有四种可能的结果,用下面的表格表示:
Type I error,I类错误,也叫做α错误,假阳性。 Type II error,II类错误,也叫做β错误,假阴性。 可以通过下面这张图形象的看到差异。
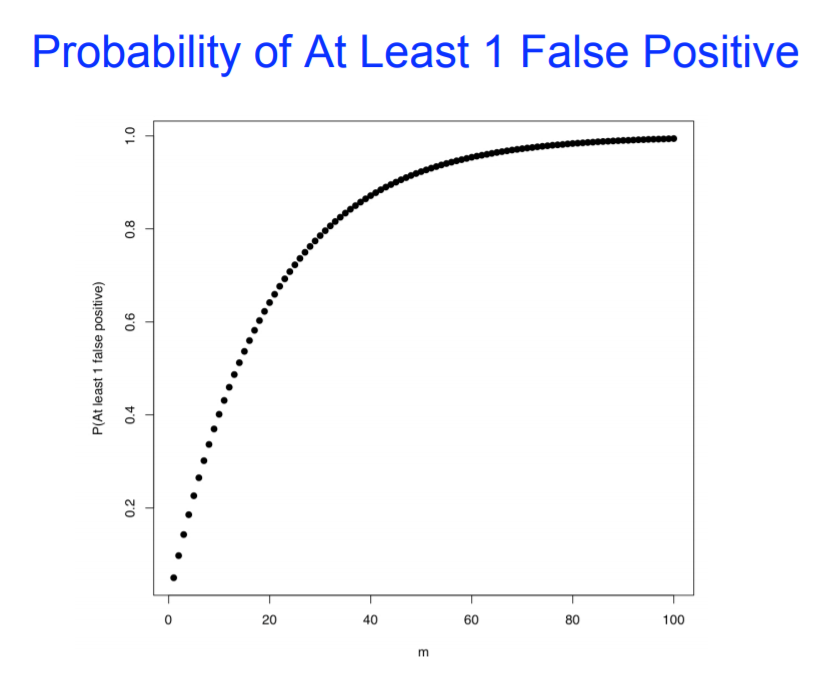
在传统的假设检验中,单个检验的显著性水平或I型错误率 (错误拒绝原假设的概率)为计算出的P-value。但随着检验次数的增加,错误拒绝原假设的概率即I型错误率大大增加。 例如:如果我们进行了m次假设检验,至少有1个假阳性的概率是多少? 错误拒绝原假设的概率 P(Reject H0|H0=True) = α 决策正确的概率 P(No Reject H0|H0=True) = 1-α P(在m次检验全部决策正确)=(1-α)^m P(在m次检验中至少一次决策错误) = 1-(1-α)^m
随着检验次数的增多,出现至少一次决策错误的概率快速提高。当说起“根据假设检验的次数校正p值”时,意思是控制整体的I型错误率。 例如:当做差异基因检测时,每个基因分别进行检测生成一个p值。如果p值设置为0.05,每个差异基因识别出错的概率为5%。如果同时分析100个基因,按照p |


【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |