mysql详解常用命令操作,利用SQL语句创建数据表 |
您所在的位置:网站首页 › MySQL常用命令增删改查举例 › mysql详解常用命令操作,利用SQL语句创建数据表 |
mysql详解常用命令操作,利用SQL语句创建数据表
SQL高级查询 1 总结 3 select ... 聚合函数 from 表名 1 where ... 2 group by ... 4 having ... 5 order by ... 6 limit ... 2 order by... 给查询结果排序 1 order by 字段名 ASC(默认升序) / DESC(降序) 2 按防御值从高到低排序 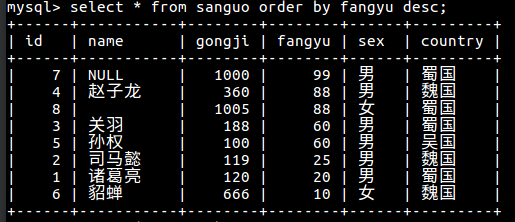 3 将蜀国英雄按攻击值从高到低排序 4 将魏蜀两国英雄中名字为3个字符的,按防御值升序排序 3 limit (永远放在SQL命令的的最后写) 1 显示查询记录的条数 2 用法 limit n;--->显示n条记录 limit m,n; -->从第m+1条记录开始,显示 n 条 3 分页 每页显示5条记录,显示第4页的内容 每页显示n条记录,显示第M页的内容 第M页,limit(m-1)*m,n 4 聚合函数 1 分类 avg(字段名):求该字段的平均值 sum(字段名):求和 max(字段名):最大值 min(字段名): 最小值 count(字段名):统计该字段记录的个数 select max(gongji) from sanguo; select name,max(gongji) as max from sanguo; 引入别名函数 别名[max] 5 group by : 给查询的结果进行分组 1 查询表中都有哪些国家 select country from sanguo group by country; 2 计算每个国家的平均攻击力 先分组,再聚合, 再去重 select country,avg(gongji) from sanguo group by country; 3 select 之后的字段名如果没有在group by 之后出现,则必须要对该字段进行聚合处理(聚合函数) 4 查找所有国家中英雄数量最多的前2名的国家名称和英雄数量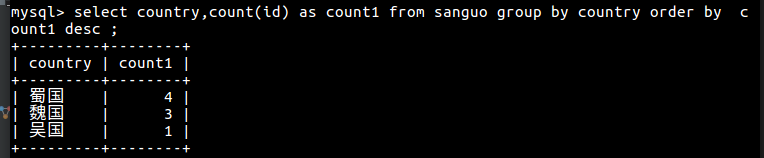
5 having 语句 1 作用 :对查询结果进行进一步的筛选 2 找出平均攻击力大于105的国家的前2名, 显示国家名称和平均攻击力
3 1 having 语句通常和group by 语句联合使用,过滤由 group by 语句返回的记录集 2 where 只能操作表中实际存在字段,having语句可操作由聚合函数生成的显示列 4 查询记录时做数学运算 1 运算符 + - * / % 2 查询时显示所有英雄攻击力翻倍 select id,name,gongji*2 as newgj from sanguo; 2 嵌套查询(子查询) 1 定义: 把内层的查询结果作为外层的查询条件 2 语法 select ... from 表名 where 字段名 运算符 (select ... from 表名 where 条件); 练习 找出每个国家攻击力最高的英雄的名字和攻击值 
上面的查询可能会出现一些人BUG,所以为了防止BUG的发生,作出一点修改 多表查询。连表查询 1 SELECT * FROM list_char LEFT JOIN list_name on list_char.pid=list_name.pid 1 两种方式 1 笛卡尔积 : 不加where条件 使用一条记录跟后面的每个表的记录逐一匹配 2 加where 条件 select .. from 表1,表2 where 条件; 4 连接查询 1 内连接(inner join) 1 语法格式 select 字段名列表 from 表1 inner join 表2 on 条件;【可以加个 】
inner join(等值连接) 只返回两个表中联结字段相等的行 2 外连接 1 左连接(left join) 1 以左表为主 显示查询结果 2 select 字段名列表 from 表1 left join 表2 on 条件 left join 表2 on 条件 3 练习 , 显示省,市详细信息,要求省全部显示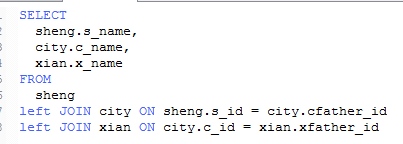 2 右连接(right join) 以右表为主显示查询结果,用法同左连接一模一样
2 右连接(right join) 以右表为主显示查询结果,用法同左连接一模一样left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录inner join(等值连接) 只返回两个表中联结字段相等的行 锁 读锁(共享锁) 写锁(互斥锁,排他锁) 2 锁粒度 1 行级锁:Innodb select : 加读锁,锁1行 update : 加写锁,锁1行 2 表级锁 : MyISAM select : 加读锁,锁当前整张表 update : 加写锁,锁1张表 6 存储引擎(Engine) 1 查看所有存储引擎 show engines; 2 查看已有表的存储引擎; show create table 表名; 3 创建表指定存储引擎 新表 create table 表名(...) engine=myisam; 已有表 alter tbale 表名 engine=myisam;常用存储引擎的特点 1 InnoDB 特点 1,支持事务,外键,行级锁 2 共享表空间 表名.frm : 表结构和索引信息 表名.ibd : 表记录 2 MyISAM特点 1 支持表级锁 2 独享表空间 表名.frm 表结构 表名.myd 表记录 mydata 表名.myi 表索引 myindex 3 MEMORY存储引擎 1 数据存储在内存中,速度快 2 服务器重启,MYSQL服务重启后表记录消失 4 如何决定使用哪个存储引擎 1 执行查询操作多的表使用 MyISAM引擎 【使用 InnoDB节省资源,表加锁比行加锁节省资源】 2 执行写操作多的表使用 InnoDB 约束 1 作用 : 保证数据的一致性,有效性 2 约束分类 1 默认约束 (default) 插入记录时,不给该字段赋值,则使用默认值 sex enum('H','F') default 'S', 2 非空约束(not null) 不允许该字段的值为null id int not null, id int not null default 0 create table t1( id int not null, name varchar(15) not null, sex enum('m','f','s') default 's', course varchar(20) not null default 'python' )character set utf8;索引 1 定义 : 对数据库中表的一列或多列的值进行排序的一种结构(bTree) 2 优点 加快数据的检索速度 3 缺点 1 当对表中数据更新时,索引需要动态维护,降低数据的维护速度 2 索引需要占用物理存储空间 4 索引示例 使用 show variables like 'profiling' 查看当前状态 1 开启运行时间检测 : mysql> set profiling=1 2 执行查询语句 select name fromm t1 where name='lucy99999'; 3 查看执行时间 show profiles; 4 在name 字段创建索引 create index name on t1(name); 5 再次执行查询语句 select name fromm t1 where name='lucy99999'; 5 索引 排序都是bTree,,区别只是约束不一样 1 普通索引(index) 1 使用规则 1,可设置多个字段 ,字段值无约束 2 把经常用来查询的字段设置为索引字段 3 KEY标志 : MUL 2 创建 1 创建表时创建 【create table t1 (id int ,name varchar(15) ,index(name),index(id));】 【创建两个索引】 2 在已有表中创建索引 【create index 索引名 on 表名(字段名);】-->索引名一般写字段名 3 查看索引 1 desc表名;--->KEY标志为 MUL 2 show index from 表名; 4 删除index drop index 索引名 on 表名; 2 唯一索引(unique) 1 使用规则: 1 可设置多个字段 2 约束:字段的值不允许重复,但可以为NULL 3 KEY标志 : UNI 2 创建 1 创建表时 unique(phnumber), unique(cardnumber) 2 已有表 create unique index 索引名 on 表名(字段名); 3 查看,删除同普通索引 删除:drop index 索引名 on 表名; 3 主键索引(primary key)&&自增长属性(auto_increment) 1 使用规则 1 只能有一个字段为主键字段 2 约束:字段值不允许重复,也不能为NULL 3 KEY标志:PRI 4 通常设置记录编号字段id,能够唯一锁定一条记录 2 创建 1 创建表时 1 id int primary key auto_increment, 2 id int auto_increment, name varchar(20) not null primary key(id,name)) 复合主键 auto_increment=10000,... 【ID从10000开始】 2 已有表 alter table 表名 add primary key(id); alter table 表名 auto_increment=10000; 【补充】 3 删除主键 1,先删除自增长属性(modify更改数据类型) alter table 表名 modify id int; 2 删除主键 alter table 表名 drop primary key; 4 外键(foreign key) ***明天讲*** 数据导入 1 作用: 把文件系统中的内容导入到数据库中 出现乱码情况往下看 2 语法格式 load data infile '文件名' into table 表名 fields terminated by '分隔符' lines terminated by '\n' 3 导入数据库中 1 在数据库中创建对应的表 2 执行数据导入 1 查看搜索路径 show variables like 'secure_file_priv';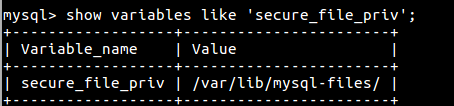
2 拷贝文件到上图路径 3 注意路径和分隔符 乱码情况下,,更改字符编码
4 导出数据 语法格式 select ... from 表名 into outfile '文件名' fields terminated by '分隔符' lines terminated by '\n';
导入导出时,特别需要注意文件路径,单词的正确程度 5 查看,更改文件权限 1 【ls -l score.txt】 r : 读 w : 写 x :可执行 表的复制 1 语法 create table 表名 select ... from 表名 where 条件; 2 示例
3 复制下表,且若每页显示2条记录,复制第3页的内容
4 复制表结构 create table 表名 select ... from 表名 where false;
1 外键 1 定义: 让当前表的字段值在另一张表的范围内去选择 2 语法格式 foreign key (参考字段名) regerances 主表(被参考字段名) on delete 级联动作 on update 级联动作; 3 使用规则 1 主表,从表字段数据类型要一致 2 主表 : 被参考字段是主键 3 创建主键 
4 删除外键 alter table 表名 drop foreign key 外键名; 外键名查看 : show create table 表名; -- >CONSTRAINT `bjtab_ibfk_1` FOREIGN KEY (`stu_id`) REFERENCES `jftab` (`id`)【红字为外键名】 5 已有表创建主键 alter table bjtab add foreign key(stu_id) references jftab(id); 6 级联动作: 1 cascade 数据级联删除,级联更新(参考字段) 2 restrict(默认) 如果从表中有相关联记录,不允许主表操作 3 set null 主表删除,更新,从表相关联记录字段值为null, MYSQL 用户账户管理 1 开启mysql远程连接(获取root权限 改配置文件) bind-address 2 用root 用户添加授权用户 1 用root 用户登录mysql 2 授权 mysql> grant 权限列表 on 库名.表名 to "用户名"@"%" identified by "密码" with grant option; 权限列表 : all privileges | select | update 库名.表名 : db4.* | *.*(所有库的所有表) 3 示例 1 添加授权用户tiger,密码123,对所有库的所有表有所有的权限,可从任何IP去连接 数据备份(mysqldump,在linux终端操作) 1 命令格式 msyqldump -u用户名 -p 源库名 > ***.sql 回车输入数据库密码 2 源库名的表示方式 --all-databases 备份所有库 库名 备份一个库 -B 库1 库2 库3 备份备份多个库 库名 表1 表2 表3 备份多张表 数据恢复 1 命令格式(linux终端) mysql -u用户名 -p 目标库名 < ***.sql 2 从所有库备份all.sql中恢复某一个库 mysql -u 用户名 -p --one-database < all.sql 注意: 1,恢复库时,如果恢复到原库会将表中的数据覆盖,,新增表不会删除 2 恢复库时,如果库不存在,则必须先创建空库 MYSQL 调优 1 创建索引 在select .where .order by常涉及到的字段建立索引 2 选择合适的存储引擎 读操作多 : MyISAM 写操作多 : InnoDB 3 SQL语句优化(避免全表扫描) 1 where 子句尽量不使用 != ,否则放弃索引 2 尽量避免 NULL判断,否则全表扫描 优化前 : select number from t1 where number is null; 优化后 : 在number 字段设置默认值0,确保number 字段无NULL select number from t1 where number=0 3 尽量避免用or 连接条件,否则全表扫描 优化前: select id from t1 where id=10 or id=20 优化后: select id from t1 where id=10 union all select id fromm t1 where id=20 4 模糊查询尽量避免使用前置 % ,否则全表扫描 select variable from t1 where name="%secure%"; 5 尽量避免使用 in 和 not in,否则全表扫描 优化前 select id from t1 where id in (1,2,3,4); 优化后 select id from t1 where id between 1 and 4; 6 不能使用select * ... 用具体字段代替*,不要返回用不到的任何字段 |








【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |