|
文章目录
万恶之源浏览器此路不通API柳暗花明端口号
去年的第一场雪下过几天之后,我的jupyterhub网页突然无法使用了,打开是能打开,但是一片空白,没办法做交互,也没有明显的报错。在历经了一番折磨之后,总算是让那熟悉的黑色界面重见天日,现记录一下这段蹉跎光阴的日子。
万恶之源浏览器
首先,我需要排查一下到底出了什么问题,浏览器右键进入调试模式  字面上来看,是这个js的文件可以获取,但由于长度不匹配不能完全获取,干脆不获取了,也就是俗话说的“如获”,导致浏览器无法渲染。 字面上来看,是这个js的文件可以获取,但由于长度不匹配不能完全获取,干脆不获取了,也就是俗话说的“如获”,导致浏览器无法渲染。  查了一下,这个原因可能是服务器那边的缓存不够了,导致了js文件的传输问题。但我又没有服务器的权限,该怎么绕开呢? 查了一下,这个原因可能是服务器那边的缓存不够了,导致了js文件的传输问题。但我又没有服务器的权限,该怎么绕开呢?
思来想去,我决定尝试强行获取非完整文件,看看能不能让网页勉强渲染出来。调试窗口进入网络连接界面,可以看到Content_Length为7037758,这应该是服务器里记录的js文件的真实大小,但由于缓存问题,浏览器无法获取到完整文件,检测到文件长度对不上。 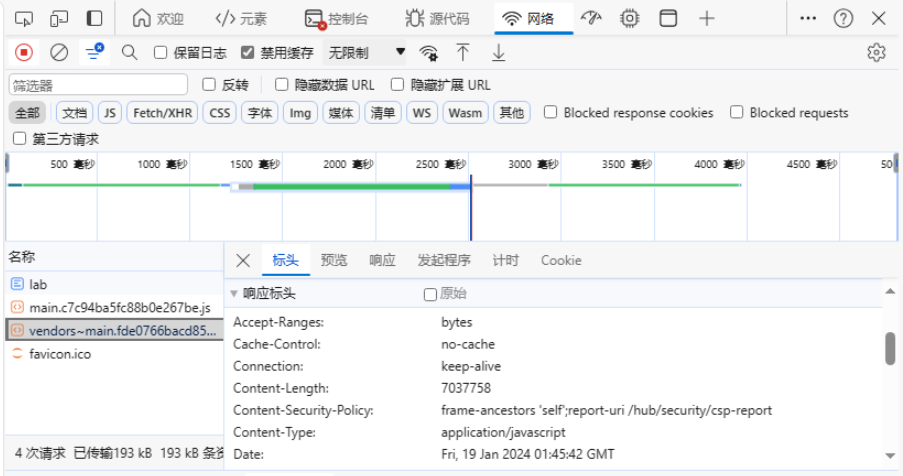 选中该js文件,右键选择Edit and Resend 选中该js文件,右键选择Edit and Resend 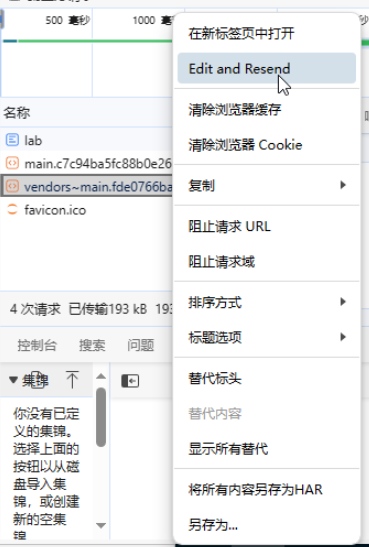 在下面的请求头中设置Range: bytes=0-160000,把获取的范围设为可实际获得的文件大小: 在下面的请求头中设置Range: bytes=0-160000,把获取的范围设为可实际获得的文件大小:  点击send,这次可以获取到文件了 点击send,这次可以获取到文件了  对应的响应头为: 对应的响应头为: 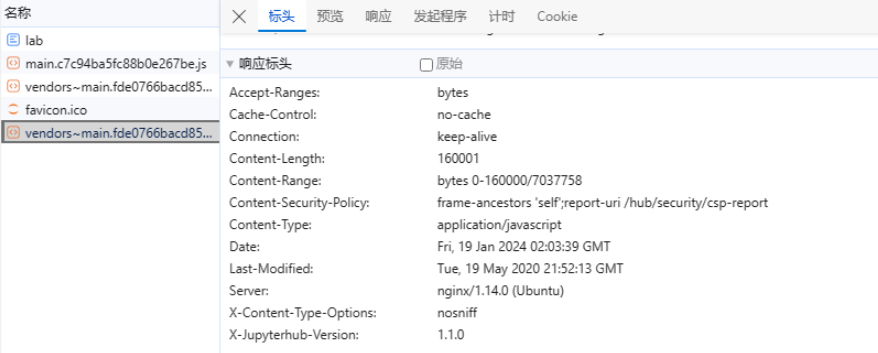 但很遗憾,此时界面依然是一片空白,浏览器并不能让我蒙混过关,第一条路尝试失败。 但很遗憾,此时界面依然是一片空白,浏览器并不能让我蒙混过关,第一条路尝试失败。
此路不通API
jupyterhub这个网页打不开,我就开始尝试别的网址,试了一通,发现jupyterhome可以打开  这里有个Token,点开看看 这里有个Token,点开看看  看到这句话没,“Anything you can do”,那我只要调一下api,不就等于可以访问了吗。于是我赶紧找了些api文档试了试【Using JupyterHub’s REST API、API List 、Interact with Jupyter Notebooks via API】,发现能用是能用,但也就止步于获取一些简单信息,没办法完成复杂的操作,下面是我写的一个简单demo,没啥意思。 看到这句话没,“Anything you can do”,那我只要调一下api,不就等于可以访问了吗。于是我赶紧找了些api文档试了试【Using JupyterHub’s REST API、API List 、Interact with Jupyter Notebooks via API】,发现能用是能用,但也就止步于获取一些简单信息,没办法完成复杂的操作,下面是我写的一个简单demo,没啥意思。
import requests
from jupyter_client import KernelManager
import socket
import jupyterhub_client
token = "985df0568b124e7ca7851ccf6cb59a20"
headers = {"Authorization": "token {token}"}
def get_kernel():
url = "http://jupyterhub.cn/user/xxx/api/kernels"
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("您有权访问kernel列表")
return response.json()
else:
print("您没有权限访问kernel列表")
def create_kernel():
url = "http://jupyterhub.cn/user/xxx/api/kernels"
response = requests.post(url, headers=headers)
return response
def get_kernel_by_id(id):
url = "http://jupyterhub.cn/user/xxx/api/kernels/"+id
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("您有权访问kernel #"+id)
return response.json()
else:
print("您没有权限访问kernel #"+id)
def get_terminal():
url = "http://jupyterhub.cn/user/xxx/api/terminals"
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("您有权访问terminal列表")
return response.json()
else:
print("您没有权限访问terminal列表")
def create_terminal():
url = "http://jupyterhub.cn/user/xxx/api/terminals"
response = requests.post(url, headers=headers)
def get_terminal_by_name(name):
url = "http://jupyterhub.cn/user/xxx/api/terminals/"+name
response = requests.get(url, headers=headers)
if response.status_code == 200:
print("您有权访问terminal #"+name)
return response.json()
else:
print("您没有权限访问terminal #"+name)
if __name__ == "__main__":
kernel_list = get_kernel()
if kernel_list is not None:
if len(kernel_list) == 0:
create_kernel()
kernel_list = get_kernel()
cur_kernel = get_kernel_by_id(kernel_list[0]['id'])
print(cur_kernel)
terminal_list = get_terminal()
if terminal_list is not None:
if len(terminal_list) == 0:
create_terminal()
terminal_list = get_terminal()
cur_terminal = get_terminal_by_name(terminal_list[0]['name'])
print(cur_terminal)
柳暗花明端口号
两条路都被堵死之后,我好像陷入了无路可走的境地。如果仅从这个网址来看的确如此,但是这个网址后面还藏着一个庞大的服务器,它只是若干服务中的一个,如果我把整个服务器探测一遍,会不会找到绕过的途径呢。
于是我ping了一下网址的前缀获取到它的IP,然后使用nmap工具扫描了所有可用端口号:
nmap -p 1-65535 -oA ./nmap/ 222.200.xxx.xxx
打开本地的nmap文件,里面是这样的 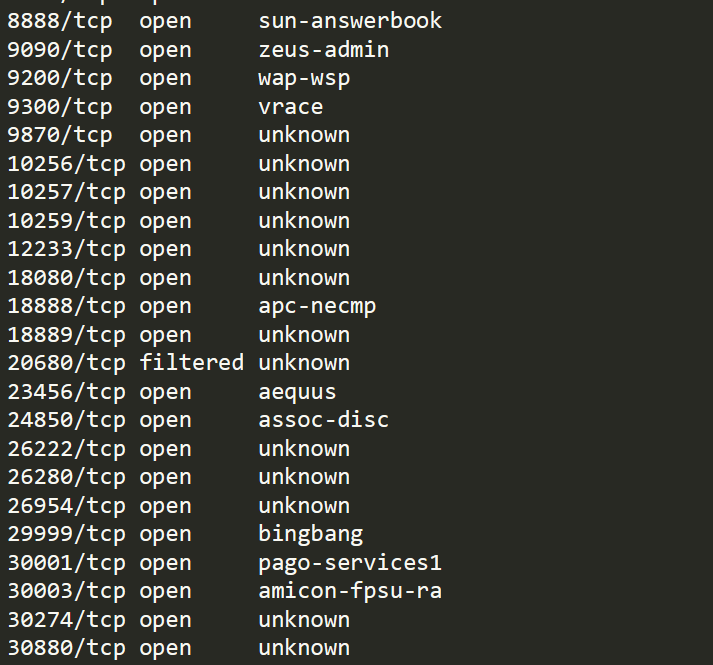 我把每个端口都在浏览器中输了一遍,有一些可以访问到本地的文件夹,拿到了一些关于连接和配置的文件,当我试到26280的时候,jupyterhub网页居然正常打开了!原来,这就是网址对应的端口号,当我以IP+端口号访问的时候,可以绕开网页方式访问导致的缓存错误,因为这样就相当于直接访问本机存放的js文件,不会有乱七八糟的中间过程。 我把每个端口都在浏览器中输了一遍,有一些可以访问到本地的文件夹,拿到了一些关于连接和配置的文件,当我试到26280的时候,jupyterhub网页居然正常打开了!原来,这就是网址对应的端口号,当我以IP+端口号访问的时候,可以绕开网页方式访问导致的缓存错误,因为这样就相当于直接访问本机存放的js文件,不会有乱七八糟的中间过程。
|