国产大模型进步有多快?我们用Z |
您所在的位置:网站首页 › 10马力有多快 › 国产大模型进步有多快?我们用Z |
国产大模型进步有多快?我们用Z
|
- 横轴是模型名称,以基础能力得分为序进行排列; - 纵轴是回答正确率,其中橙色表示基础能力,黄色表示涌现能力,绿色代表垂直领域能力。 在测评的过程中, 我们明显感受到了「国产」大模型能力在基础、涌现、垂直能力方面的全面进步,其中 商汤、ChatGLM 130B v0.8 以及讯飞星火的基础能力部分回答正确率都已经到了 70%,虽然对比 GPT-4 的 95% 和 GPT-3.5 的 92% 尚有差距,但对比两个月前的结果,已经让我们对「国产」模型的未来有了更强的信心。 那么, 「国产」大模型到底在哪些方面有了进步,又有哪些需要改进的地方呢?我们可以从两个角度进行分析: 第一,从单模型变化角度分析。正如上文所提到的,这次的测评中,有两位「老选手」 —— 百度文心一言与智谱 AI 的 ChatGLM,他们都在最初发布版本上进行了更新,就最终得分来看:
- 文心一言的进步则主要体现在基础能力部分。其中事实问答(5/19 VS 9/19)能力的提升最为明显,代码能力与垂直领域知识问答也有部分提升,其他方面的能力进步并不明显。
第二,从新发布模型的能力进行分析。我们以表现最突出的四个模型,商汤 SenseChat、讯飞星火、Minimax 应事 AI 与阿里通义千问为例: - 先说优点,几个模型的 事实问答能力都已经到了不错的水平。在 19 个问题的测评中,阿里通义千与讯飞星火都得到了 12 分,商汤 SenseChat 11 分,Minimax 10 分。 - 但其他能力方面, 几个模型都存在「偏科」现象: ✔ 商汤 SenseChat 全部回答错误的类别更少,能力更为全面,尤其值得一提的是,SenseChat 在对话与文本处理的多个细分类别中得到了满分; ✔ 阿里通义千问的常识与基础编程能力相较其他模型更好,但涉及数据、编码、符号相关的处理能力较差,对语言逻辑的判断能力还需进一步提升; ✔ 讯飞星火的基础数学能力(17/44)在其中是最为优秀的,但几何能力却是这四个模型中最差的,无论空间几何还是坐标几何,均全部回答错误; ✔ Minimax 的对话与文本处理能力已经很不错了,在分类、语法修正、情绪感知这三类中得到了满分,在语义识别与语言逻辑判断中的得分也较为优秀,但其文本处理能力也不是全面的,其中要点总结能力显然还需要提高。 - 最后说说缺点,国产中文模型的 编程可用性还相对较低,数据与符号处理能力还有所欠缺,多语言处理能力较差,老生常谈的 逻辑推理与数学能力也还有很大提升空间。
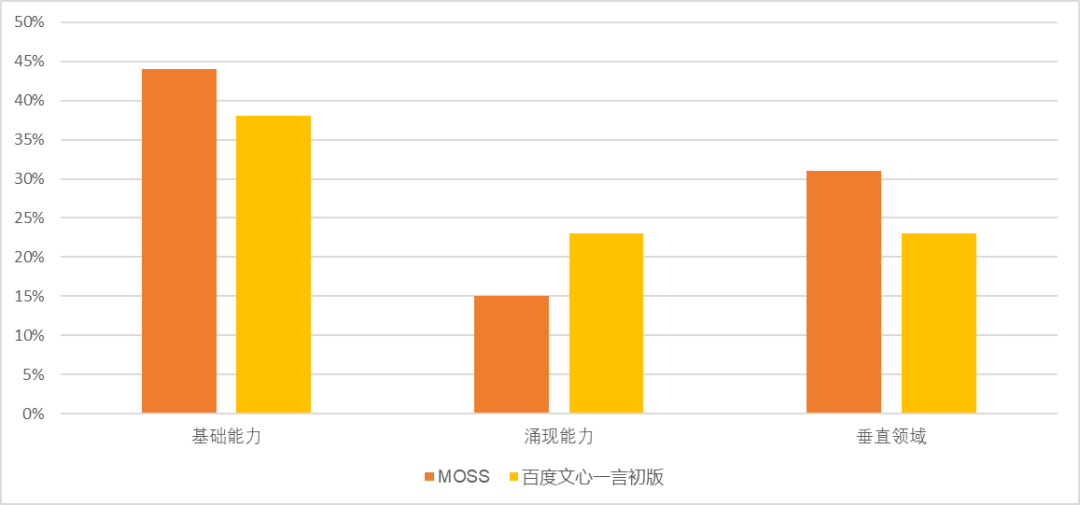
在本次测评中, 有一个特殊的模型 MOSS —— 由复旦大学开发并完全开源的大语言模型。在这次的测评中, 虽然 MOSS 的表现并不突出,但其综合能力已经超过了 3 月发布的百度文心一言(基础能力 44%:38%,涌现能力 15%:23%;垂直能力 31%:23%)。
另外,值得一提的是,ChatGLM 不仅在我们的测评中排名靠前,在前不久 UC Berkeley 团队领衔的 LMSYS 组织的 Chatbot Arena 测评中, 开源的 ChatGLM-6B 英文表现也很优秀(测评结果链接我们也附在了文末)。海外开源模型蔚然成风的当下,我们希望听到更多来自中文开源社区的好消息! 最后, 我们也真诚地期待,未来可以看到中国及更广泛的华人企业、研究机构与学者为我们在大模型领域带来更多惊喜。 🔗 LMSYS Chatbot Arena - https://lmsys.org/blog/2023-05-03-arena/ 更多被投新闻 依图科技 | Momenta | Nuro | 云天励飞 禾赛科技 | 晶泰科技 | 地平线 | 燧原科技 亿航智能 | 思谋科技 | 青藤云安全 | 爱笔智能 沐曦 | 驭势科技 | 芯耀辉 | 森亿智能 | AutoX 格灵深瞳 | 曦智科技 | 来也科技 | 星亢原 黑湖智造 | 领创集团 | 非夕机器人 芯行纪 | 灵明光子 | 优艾智合 | 炬星科技 东方空间 | 循环智能 | 诗云科技 | 赛舵智能 潞晨科技 | 芯控智能 | 氦星光联 | 悠跑科技 返回搜狐,查看更多 |



【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |