多模态逆天图片生成,OpenAI又一力作:DALL·E 2 |
您所在的位置:网站首页 › 10后逆天照片 › 多模态逆天图片生成,OpenAI又一力作:DALL·E 2 |
多模态逆天图片生成,OpenAI又一力作:DALL·E 2
|
文章目录
1.DALL . E 2:集艺术之大成2. 技术细节2.1 CLIP2.2 DALL.E 2具体方法
3.后续
1.DALL . E 2:集艺术之大成
还记得2021年刷爆AI圈的DALL·E,它是基于文本token来生成超现实主义的图像,比如下面的牛油果形状的椅子。 二次创作:编辑图像 例如在下面图中,旋转一个位置放置火烈鸟: 风格迁移 根据提供的一张图片,生成另一种风格 生成高像素的图片 对比于1.0版本,升级之后的DALL能够生成更高像素的图片: 一些网友已经纷纷开启试用: 文本内容:1980年代,泰迪熊在月球上进行人工智能研究 体验网址如下(不过需要加入waitlist):https://labs.openai.com/waitlist 2. 技术细节 2.1 CLIPCLIP是基于文本-图像对的预训练方法,它主要是通过对比学习思想,来匹配对应的图像和其文字描述。其中包含了text-encoder和image-encoder。对于一个包含
N
N
N个文本-图像对的数据集来说,对比学习就是将N个图像和N个文本进行两两匹对,然后预测出其相似概率。其中只有
N
N
N个是正样本(图中对角线元素),其余
N
2
−
N
N^2-N
N2−N为负样本。 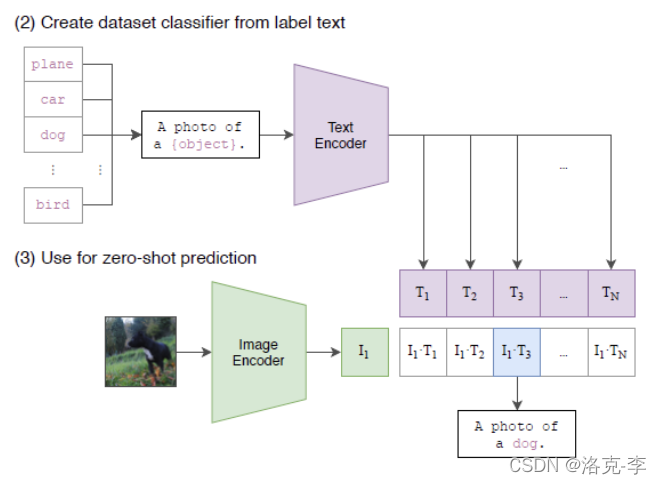 2.2 DALL.E 2具体方法
2.2 DALL.E 2具体方法
在训练集上构成
(
x
,
y
)
(x, y)
(x,y),其中
x
x
x为图片,
y
y
y为其说明文字。给定图片
x
x
x,
z
i
z_i
zi表示CLIP模型生成的图像特征,
z
t
z_t
zt表示CLIP生成的文本特征。 生成图片主要有两个步骤: 利用真实文本描述 y y y ,通过CLIP生成的图像特征 z i z_i zi利用真实文本描述 y y y和CLIP生成的图像特征 z i z_i zi,解码成图片 x x x 3.后续图像生成工具一直是黑产可利用的工具之一。在限制措施上,OpenAI限制了DALL·E 2生成暴力、仇恨或成人图像的能力。同时还使用了先进的技术来防止生成真实人物的脸,包括公众人物的脸照片生成。 如果过滤器识别出可能违规的文本提示和图像上传,将不会生成图像。这样将会有效的减少DALL.E 2工具的滥用。 目前DALL.E 2还处于测试阶段,OpenAI一直寻找外包专家合作,并将提供给一定量的可信任用户使用。官网中提到:随着时间的推移,将计划邀请更多的人来预览这项研究,以了解并不断改进我们的安全系统。 |
 最近,OpenAI基于其1.0版本进行了升级,发布了DALL·E 2。该版本除了可以像1.0版本一样,从自然语言的描述中创建逼真的图像和艺术,还可以:
最近,OpenAI基于其1.0版本进行了升级,发布了DALL·E 2。该版本除了可以像1.0版本一样,从自然语言的描述中创建逼真的图像和艺术,还可以:
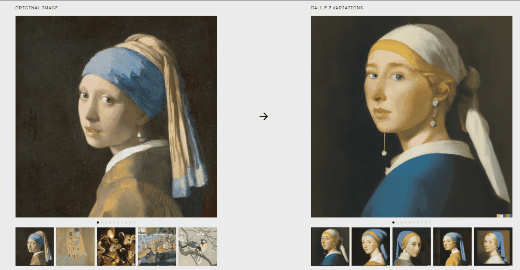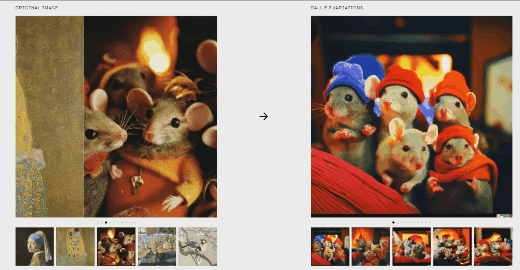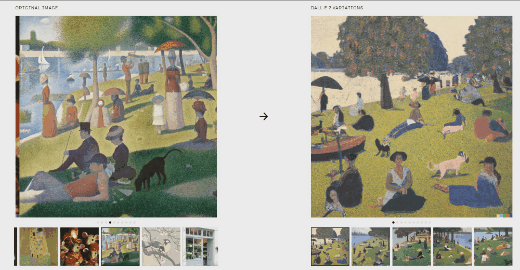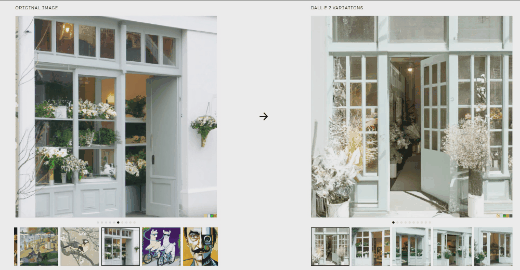

 文本内容:蒙娜丽莎在喝酒
文本内容:蒙娜丽莎在喝酒 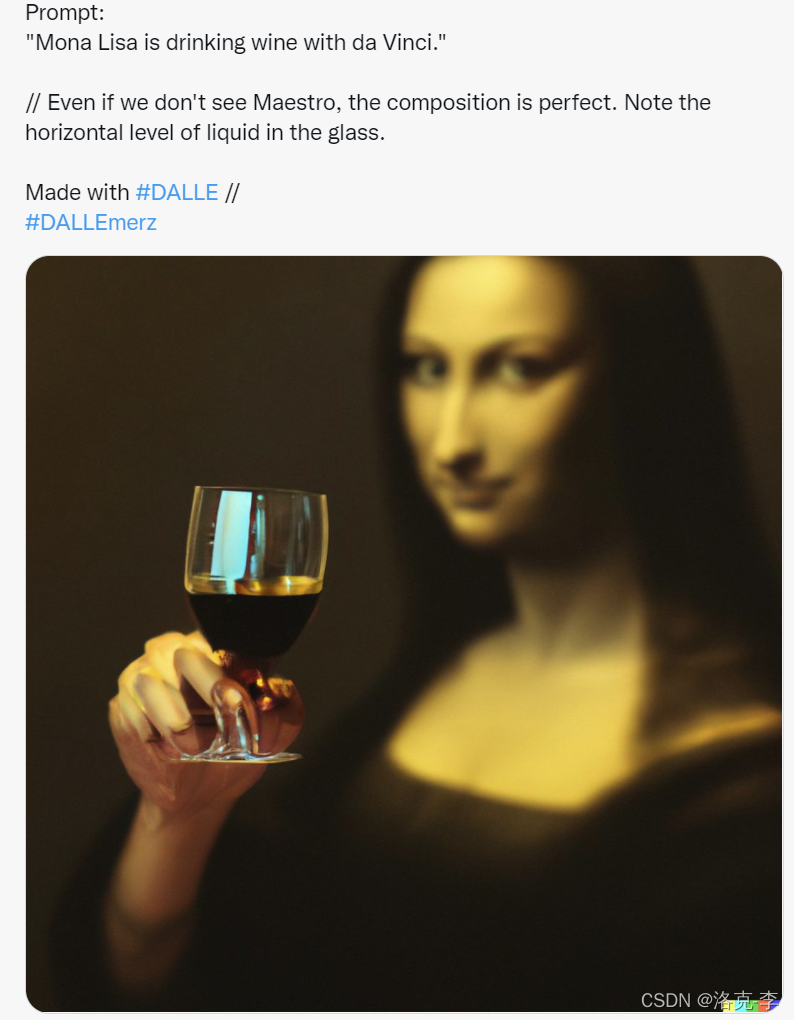 从上面可以看出,DALL.E 2生成的效果可以和画家画出的图片媲美。
从上面可以看出,DALL.E 2生成的效果可以和画家画出的图片媲美。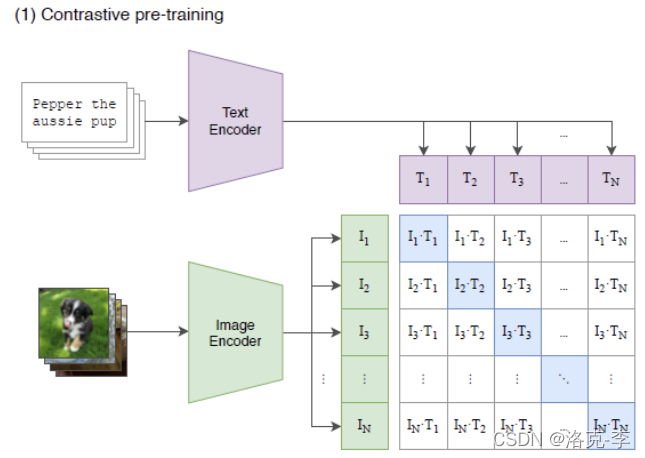 CLIP模型可以直接实现zero-shot分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
CLIP模型可以直接实现zero-shot分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。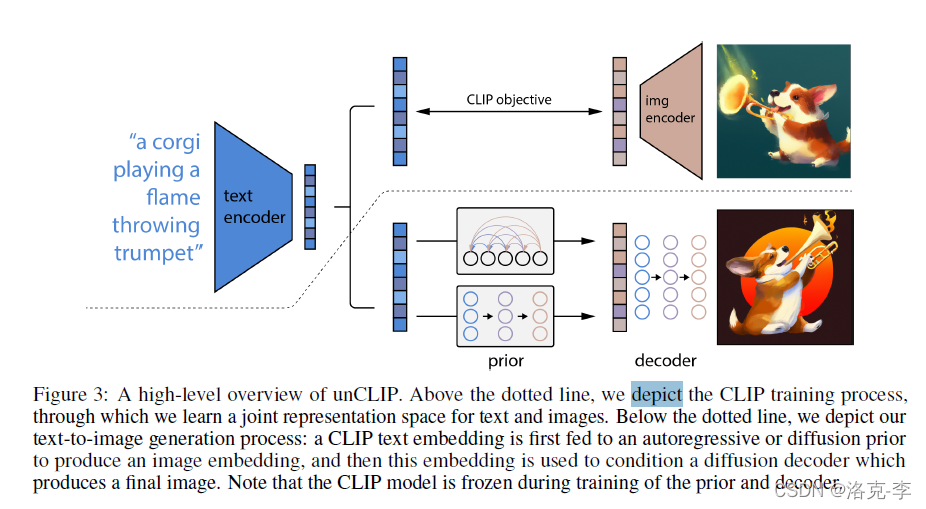
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |