| 深度学习入门 | 您所在的位置:网站首页 › 鸢尾花介绍的 › 深度学习入门 |
深度学习入门
|
基于TensorFlow的鸢尾花分类实现
0 引言1 基本介绍和环境搭建1.1关于TensorFlow-GPU环境搭建第一步:安装Anaconda:第二步:安装GPU版本需要,明确显卡型号第三步:打开conda终端建立Tensorflow环境第四步:激活虚拟环境:第五步:安装ensorflow gpu版本:第六步:安装keras:pip install keras -i 软件源第七步:进入IDE(Pycharm或者VScode)切换环境为tensorflow-gpu调试
1.2关于鸢尾花数据集介绍
2 实现过程及分析2.1 数据集可视化化以及PCA降维:2.2 实验结果如下:2.3 分析结论
附录(完整Python代码)
Author(作者): Nirvana Of Phoenixl Proverbs for you(送给你的哦):There is no doubt that good things will always come, and when it comes late, it can be a surprise. 文章可以作为深度学习或者TensorFlow入门的了解学习。使用PyChram和Python实现,安装过程中最容易出现的问题是GPU版本的与显卡的问题。如果需要对应版本的TensorFlow,可以私信一下,呜呜我懒的放上来,可以发一份给你们! 0 引言本文主要是基于TensorFlow和Keras框架实现的鸢尾花分类,主要包含关于深度学习TensorFlow-GPU环境的搭建,以及实现框架的实现,其实验目的是实现鸢尾花分类,本质是通过简单的实践理解深度学习基本流程,加深对于代码实现的理解,通过对框架中的参数修改和完善理解调参对于框架识别精度的影响。最终目标是熟悉包括软件安装在内的深度学习环境的搭建、框架的构建、参数的调整做一个系统的学习和理解。 1 基本介绍和环境搭建 1.1关于TensorFlow-GPU环境搭建 深度学习的核心概念就是以张量(矩阵)运算模拟神经网络的。TensorFlow主要的设计就是让矩阵运算达到最高性能,并且能够在各种不同的平台下运行。TensorFlow最初由谷歌开发,深度学习的发展是由前景的,谷歌希望建立一个开源的社区,强大TensorFlow使其更加完善,最后开源。TensorFlow架构主要由处理器(cpu/gpu/tpu)、平台(win/linux/android/ios/raspi)、tensoflow引擎、前端语言(python/c++)、高级api(keras/TF-learn/TF-slim/TF-layer)组成。如下图所示,TensorFlow架构组成。 TensorFlow是比较低级深度学习API,所以在程序设计模型时必须自行设计:张量乘积、卷积等底层操作,好处是我们可以自行设计各种深度学习模型,但缺点是开发时需要编写更多的程序代码,并且需要花费很长的时间。所以网上的开发社区以TensorFlow为底层开发很多高级的深度学习API,例如Keras、TF-Learn等。这样可以使得开发者使用更简洁、更具可读性的程序代码就可以构建出各种复杂的深度学习模型。本文主要采用Keras,因为Keras功能最为完整。 下面介绍如何在Windows上安装TensorFlow-GPU版本,因为其计算能力更强。因为之前本人已经安装过了TensorFlow-GPU版本,并搭建了环境,参考代码实现了一些经典数据集的学习训练,比如Keras MINIST、Keras-CIFAR-10等。下面将讲解如何安装和踩坑出现的问题。首先明确,对于GPU版本的TensorFlow主要通过NVIDIA提供的CUDA和cudnn存取GPU,CUDA是NVIDIA推出的整合技术,实质功能就是一种通过应用显卡处理数量较大的数据问题的架构,而cudnn是NVIDIA深度学习SDK的一部分,用于提供GPU深度学习库和加速深度学习的。 具体的安装步骤: 第一步:安装Anaconda:指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。(按步骤安装即可)
(目前绝大多数时NVIDIA的显卡),去官方的网址下载CUDA和cudnn(注意这里需要明确版本对应查找适合是显卡型号的CUDA然后根据CUDA确定cudnn)实际在我测试过程当中可以低版本安装,但是不能高于当前适用的版本安装。(实际显卡提示安装CUAD11.0,cudnn 8.0但是我安装的是CUDA10.0和cudnn7.4) conda create –name tensorflow-gpu python=3.7 建立名为tensorflow-gpu的python3.7的环境(或者在后面加上anaconda直接下载python所有包)如果需要单独安装缺少的包pip install 包名 -i 软件源 第四步:激活虚拟环境:activate tensorflow-gpu 创建的虚拟环境会在anaconda安装路径下envs中出现新建的虚拟环境。
中科大软件源https://pypi.mirrors.ustc.edu.cn/simple/,在安装tensorflow gpu版本的时候可以限制具体版本号即pip install tensorflow-gpu=1.14.0 -i 软件源 第六步:安装keras:pip install keras -i 软件源 第七步:进入IDE(Pycharm或者VScode)切换环境为tensorflow-gpu调试
Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类,共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度Sepal.Length、花萼宽度Sepal.Width、花瓣长度Petal.Length、花瓣宽度Petal.Width,可以通过这4个特征预测鸢尾花卉属于狗尾草iris-setosa、杂色鸢尾花 iris-versicolour、弗吉尼亚鸢尾花 iris-virginica是属于什么类别,在数据集中也包括花萼花瓣长度对应的鸢尾花种类Species数据。 本文主要通过Pycharm开发环境实现,基于tensorflow-gpu完成深度学习框架搭建。 2.1 数据集可视化化以及PCA降维:
(1)学习率0.1,循环次数为500,当次数为185时,测试准确率刚好为1 Epoch 185, loss: 0.05128058139234781,Test_acc: 1.0 (2)学习率为0.01,循环次数为500,当次数为500时,测试准确为0.66… Epoch 499, loss: 0.08802829124033451,Test_acc: 0.6666666666666666 (3)学习率为0.5,循环次数为500,当次数为500时,精度为1.0 Epoch 499, loss: 0.024999298620969057,Test_acc: 1.0 (4)学习率为0.1,循环次数为3000,当次数为185时,精度为1 Epoch 185, loss: 0.05128058139234781,Test_acc: 1.0 实际上我们可以对比发现,(1)(2)每轮循环次数一样学习率不同导致的情况不同,当学习率过小的时候会影响模型的收敛时间,直观来看明显使得过程缓慢;(1)(3)可以得到学习率过大,会导致梯度会在最小值附近可能来回震荡,严重的可能导致无法收敛。从一定程度上来看,(4)(5)学习率一定循环次数在达到一个固定的值后,再多次循环不影响精度值。 具体实现代码见附录。 附录(完整Python代码) ```python #导入所需模块: import tensorflow as tf # 导入模型框架 from sklearn import datasets # 从sklearn文件包中导入含有的数据集 from matplotlib import pyplot as plt # 从python中导入绘图库matplotlib import numpy as np # 导入开源计算包numpy from sklearn.decomposition import PCA from mpl_toolkits.mplot3d import Axes3D tf.enable_eager_execution( config=None, device_policy=None, execution_mode=None ) # 在即将到来的TensorFlow2.0中将对部分机制做出重大调整,其中之一就是将原有的静态图机制调整为动态图机制,这将使得TensorFlow更加灵活和易用,2.0版本之前,可以通过 tf.enable_eager_execution() 方法来启用动态图机制 #导入数据可视化数据集 #———————————————————————————————— iris = datasets.load_iris() X = iris.data[:, :2] # 列切片索引:只取前两个特征. y = iris.target x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 plt.figure(2, figsize=(8, 6)) plt.clf() 绘制训练数据点 plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1, edgecolor='k') plt.xlabel('Sepal length') plt.ylabel('Sepal width') plt.xlim(x_min, x_max) plt.ylim(y_min, y_max) plt.xticks(()) plt.yticks(()) 为了对数据的各个维度之间的相互作用有一个更好地理解, #绘制前三个 PCA dimensions。 fig = plt.figure(1, figsize=(8, 6)) ax = Axes3D(fig, elev=-150, azim=110) X_reduced = PCA(n_components=3).fit_transform(iris.data) ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=y, cmap=plt.cm.Set1, edgecolor='k', s=40) ax.set_title("First three PCA directions") ax.set_xlabel("1st eigenvector") ax.w_xaxis.set_ticklabels([]) ax.set_ylabel("2nd eigenvector") ax.w_yaxis.set_ticklabels([]) ax.set_zlabel("3rd eigenvector") ax.w_zaxis.set_ticklabels([]) plt.show() #———————————————————————————————————— #框架模型搭建以及实现 #导入数据:共计数据150组,分别为输入特征(x)和标签(y) x_data = datasets.load_iris().data y_data = datasets.load_iris().target 输入数据预处理:随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率) np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应(seed参数每一个数对应一个随机规则,数字一样随机规则一样产生的随机结果也一样) np.random.shuffle(x_data) # 重新排序返回一个随机序列,在原数组上进行,改变自身序列,无返回值 np.random.seed(116) np.random.shuffle(y_data) tf.compat.v1.random.set_random_seed(116) # 版本原因导致的一些写法错误,tf.random.set_seed(116)修改内容 #分割数据集:将打乱后的数据集(共有数据150行)分割为训练集和测试集,训练集为前120行,测试集为后30行 x_train = x_data[:-30] # x_data[:-30]=x_data[0:120] y_train = y_data[:-30] x_test = x_data[-30:] # x_data[-30:]=x_data[120:150] y_test = y_data[-30:] #数据处理:转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错 x_train = tf.cast(x_train, tf.float32) x_test = tf.cast(x_test, tf.float32) #数据切片: from_tensor_slices((数据特征,标签)),函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据) #batch(数据集大小/batch大小),两个数字可能不是整除,会导致一个batch大小可能小于等于batch size train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32) test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32) #生成神经网络的参数,4个输入特征,因此输入层为4个输入节点;因为3分类,所以输出层为3个神经元 #用tf.Variable()标记参数可训练 使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed) w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1)) b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1)) lr = 0.1 # 学习率为0.1 train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据 test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据 epoch = 186 # 循环500轮 loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和 #训练部分 for epoch in range(epoch): # 数据集级别的循环,每个epoch循环一次数据集 for step, (x_train, y_train) in enumerate(train_db): # batch级别的循环 ,每个step循环一个batch with tf.GradientTape() as tape: # with结构记录梯度信息 y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算 y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss) y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2) loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确 # 计算loss对各个参数的梯度 grads = tape.gradient(loss, [w1, b1]) # 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad w1.assign_sub(lr * grads[0]) # 参数w1自更新 b1.assign_sub(lr * grads[1]) # 参数b自更新 # 每个epoch,打印loss信息 print("Epoch {}, loss: {}".format(epoch, loss_all/4)) train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中 loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备 # 测试部分 # total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0 total_correct, total_number = 0, 0 for x_test, y_test in test_db: # 使用更新后的参数进行预测 y = tf.matmul(x_test, w1) + b1 y = tf.nn.softmax(y) pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类 # 将pred转换为y_test的数据类型 pred = tf.cast(pred, dtype=y_test.dtype) # 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型 correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) # 将每个batch的correct数加起来 correct = tf.reduce_sum(correct) # 将所有batch中的correct数加起来 total_correct += int(correct) # total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数 total_number += x_test.shape[0] # 总的准确率等于total_correct/total_number total_number= int(total_number) #错误的原因在,一个是numpy对象,一个是Dimension对象,无法相除, #用int函数,将Dimension对象对象转换为int acc = total_correct / total_number test_# 导入所需模块: import tensorflow as tf # 导入模型框架 from sklearn import datasets # 从sklearn文件包中导入含有的数据集 from matplotlib import pyplot as plt # 从python中导入绘图库matplotlib import numpy as np # 导入开源计算包numpy tf.enable_eager_execution( config=None, device_policy=None, execution_mode=None ) # 在即将到来的TensorFlow2.0中将对部分机制做出重大调整,其中之一就是将原有的静态图机制调整为动态图机制,# # 这将使得TensorFlow更加灵活和易用,2.0版本之前,可以通过 tf.enable_eager_execution() 方法来启用动态图机制 导入数据:共计数据150组,分别为输入特征(x)和标签(y) x_data = datasets.load_iris().data y_data = datasets.load_iris().target 输入数据预处理:随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率) np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应(seed参数每一个数对应一个随机规则,数字一样随机规则一样产生的随机结果也一样) np.random.shuffle(x_data) # 重新排序返回一个随机序列,在原数组上进行,改变自身序列,无返回值 np.random.seed(116) np.random.shuffle(y_data) tf.compat.v1.random.set_random_seed(116) # 版本原因导致的一些写法错误,tf.random.set_seed(116)修改内容 #分割数据集:将打乱后的数据集(共有数据150行)分割为训练集和测试集,训练集为前120行,测试集为后30行 x_train = x_data[:-30] # x_data[:-30]=x_data[0:120] y_train = y_data[:-30] x_test = x_data[-30:] # x_data[-30:]=x_data[120:150] y_test = y_data[-30:] #数据处理:转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错 x_train = tf.cast(x_train, tf.float32) x_test = tf.cast(x_test, tf.float32) 数据切片: from_tensor_slices((数据特征,标签)),函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据) batch(数据集大小/batch大小),两个数字可能不是整除,会导致一个batch大小可能小于等于batch size train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32) test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32) #生成神经网络的参数,4个输入特征,因此输入层为4个输入节点;因为3分类,所以输出层为3个神经元 #用tf.Variable()标记参数可训练 #使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed) w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1)) b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1)) lr = 0.1 # 学习率为0.1 train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据 test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据 epoch = 186 # 循环500轮 loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和 训练部分 for epoch in range(epoch): # 数据集级别的循环,每个epoch循环一次数据集 for step, (x_train, y_train) in enumerate(train_db): # batch级别的循环 ,每个step循环一个batch with tf.GradientTape() as tape: # with结构记录梯度信息 y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算 y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss) y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2) loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确 # 计算loss对各个参数的梯度 grads = tape.gradient(loss, [w1, b1]) # 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad w1.assign_sub(lr * grads[0]) # 参数w1自更新 b1.assign_sub(lr * grads[1]) # 参数b自更新 # 每个epoch,打印loss信息 print("Epoch {}, loss: {}".format(epoch, loss_all/4)) train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中 loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备 # 测试部分 # total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0 total_correct, total_number = 0, 0 for x_test, y_test in test_db: # 使用更新后的参数进行预测 y = tf.matmul(x_test, w1) + b1 y = tf.nn.softmax(y) pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类 # 将pred转换为y_test的数据类型 pred = tf.cast(pred, dtype=y_test.dtype) # 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型 correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) # 将每个batch的correct数加起来 correct = tf.reduce_sum(correct) # 将所有batch中的correct数加起来 total_correct += int(correct) # total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数 total_number += x_test.shape[0] # 总的准确率等于total_correct/total_number total_number= int(total_number) #错误的原因在,一个是numpy对象,一个是Dimension对象,无法相除, #用int函数,将Dimension对象对象转换为int acc = total_correct / total_number test_acc.append(acc) print("Test_acc:", acc) print("--------------------------") #绘制 loss 曲线 plt.title('Loss Function Curve') # 图片标题 plt.xlabel('Epoch') # x轴变量名称 plt.ylabel('Loss') # y轴变量名称 plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss plt.legend() # 画出曲线图标 plt.show() # 画出图像 绘制 Accuracy 曲线 plt.title('Acc Curve') # 图片标题 plt.xlabel('Epoch') # x轴变量名称 plt.ylabel('Acc') # y轴变量名称 plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy plt.legend() plt.show() #导入所需模块: import tensorflow as tf # 导入模型框架 from sklearn import datasets # 从sklearn文件包中导入含有的数据集 from matplotlib import pyplot as plt # 从python中导入绘图库matplotlib import numpy as np # 导入开源计算包numpy tf.enable_eager_execution( config=None, device_policy=None, execution_mode=None ) # 在即将到来的TensorFlow2.0中将对部分机制做出重大调整,其中之一就是将原有的静态图机制调整为动态图机制,# # 这将使得TensorFlow更加灵活和易用,2.0版本之前,可以通过 tf.enable_eager_execution() 方法来启用动态图机制 #导入数据:共计数据150组,分别为输入特征(x)和标签(y) x_data = datasets.load_iris().data y_data = datasets.load_iris().target #输入数据预处理:随机打乱数据(因为原始数据是顺序的,顺序不打乱会影响准确率) np.random.seed(116) # 使用相同的seed,保证输入特征和标签一一对应(seed参数每一个数对应一个随机规则,数字一样随机规则一样产生的随机结果也一样) np.random.shuffle(x_data) # 重新排序返回一个随机序列,在原数组上进行,改变自身序列,无返回值 np.random.seed(116) np.random.shuffle(y_data) tf.compat.v1.random.set_random_seed(116) # 版本原因导致的一些写法错误,tf.random.set_seed(116)修改内容 #分割数据集:将打乱后的数据集(共有数据150行)分割为训练集和测试集,训练集为前120行,测试集为后30行 x_train = x_data[:-30] # x_data[:-30]=x_data[0:120] y_train = y_data[:-30] x_test = x_data[-30:] # x_data[-30:]=x_data[120:150] y_test = y_data[-30:] 数据处理:转换x的数据类型,否则后面矩阵相乘时会因数据类型不一致报错 x_train = tf.cast(x_train, tf.float32) x_test = tf.cast(x_test, tf.float32) #数据切片: from_tensor_slices((数据特征,标签)),函数使输入特征和标签值一一对应。(把数据集分批次,每个批次batch组数据) #batch(数据集大小/batch大小),两个数字可能不是整除,会导致一个batch大小可能小于等于batch size train_db = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(32) test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(32) #生成神经网络的参数,4个输入特征,因此输入层为4个输入节点;因为3分类,所以输出层为3个神经元 #用tf.Variable()标记参数可训练 #使用seed使每次生成的随机数相同(方便教学,使大家结果都一致,在现实使用时不写seed) w1 = tf.Variable(tf.random.truncated_normal([4, 3], stddev=0.1, seed=1)) b1 = tf.Variable(tf.random.truncated_normal([3], stddev=0.1, seed=1)) lr = 0.1 # 学习率为0.1 train_loss_results = [] # 将每轮的loss记录在此列表中,为后续画loss曲线提供数据 test_acc = [] # 将每轮的acc记录在此列表中,为后续画acc曲线提供数据 epoch = 186 # 循环500轮 loss_all = 0 # 每轮分4个step,loss_all记录四个step生成的4个loss的和 #训练部分 for epoch in range(epoch): # 数据集级别的循环,每个epoch循环一次数据集 for step, (x_train, y_train) in enumerate(train_db): # batch级别的循环 ,每个step循环一个batch with tf.GradientTape() as tape: # with结构记录梯度信息 y = tf.matmul(x_train, w1) + b1 # 神经网络乘加运算 y = tf.nn.softmax(y) # 使输出y符合概率分布(此操作后与独热码同量级,可相减求loss) y_ = tf.one_hot(y_train, depth=3) # 将标签值转换为独热码格式,方便计算loss和accuracy loss = tf.reduce_mean(tf.square(y_ - y)) # 采用均方误差损失函数mse = mean(sum(y-out)^2) loss_all += loss.numpy() # 将每个step计算出的loss累加,为后续求loss平均值提供数据,这样计算的loss更准确 # 计算loss对各个参数的梯度 grads = tape.gradient(loss, [w1, b1]) # 实现梯度更新 w1 = w1 - lr * w1_grad b = b - lr * b_grad w1.assign_sub(lr * grads[0]) # 参数w1自更新 b1.assign_sub(lr * grads[1]) # 参数b自更新 # 每个epoch,打印loss信息 print("Epoch {}, loss: {}".format(epoch, loss_all/4)) train_loss_results.append(loss_all / 4) # 将4个step的loss求平均记录在此变量中 loss_all = 0 # loss_all归零,为记录下一个epoch的loss做准备 # 测试部分 # total_correct为预测对的样本个数, total_number为测试的总样本数,将这两个变量都初始化为0 total_correct, total_number = 0, 0 for x_test, y_test in test_db: # 使用更新后的参数进行预测 y = tf.matmul(x_test, w1) + b1 y = tf.nn.softmax(y) pred = tf.argmax(y, axis=1) # 返回y中最大值的索引,即预测的分类 # 将pred转换为y_test的数据类型 pred = tf.cast(pred, dtype=y_test.dtype) # 若分类正确,则correct=1,否则为0,将bool型的结果转换为int型 correct = tf.cast(tf.equal(pred, y_test), dtype=tf.int32) # 将每个batch的correct数加起来 correct = tf.reduce_sum(correct) # 将所有batch中的correct数加起来 total_correct += int(correct) # total_number为测试的总样本数,也就是x_test的行数,shape[0]返回变量的行数 total_number += x_test.shape[0] # 总的准确率等于total_correct/total_number total_number= int(total_number) #错误的原因在,一个是numpy对象,一个是Dimension对象,无法相除, #用int函数,将Dimension对象对象转换为int acc = total_correct / total_number test_acc.append(acc) print("Test_acc:", acc) print("--------------------------") #绘制 loss 曲线 plt.title('Loss Function Curve') # 图片标题 plt.xlabel('Epoch') # x轴变量名称 plt.ylabel('Loss') # y轴变量名称 plt.plot(train_loss_results, label="$Loss$") # 逐点画出trian_loss_results值并连线,连线图标是Loss plt.legend() # 画出曲线图标 plt.show() # 画出图像 #绘制 Accuracy 曲线 plt.title('Acc Curve') # 图片标题 plt.xlabel('Epoch') # x轴变量名称 plt.ylabel('Acc') # y轴变量名称 plt.plot(test_acc, label="$Accuracy$") # 逐点画出test_acc值并连线,连线图标是Accuracy plt.legend() plt.show() |
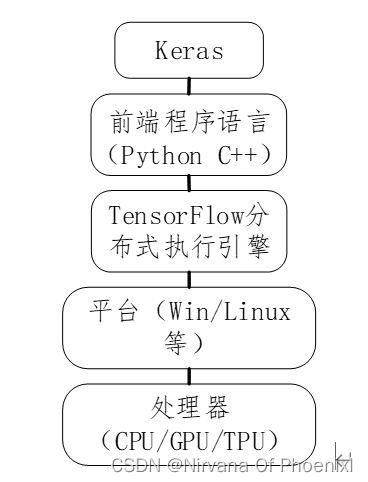 图1 TensorFlow架构组成
图1 TensorFlow架构组成 图示上下分别为基本环境和新建的虚拟的GPU环境。
图示上下分别为基本环境和新建的虚拟的GPU环境。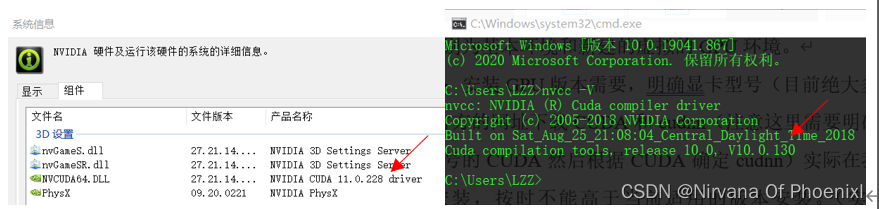 图示 为安装CUDA版本的版本,cudnn对应可以去配置文件里面查看。
图示 为安装CUDA版本的版本,cudnn对应可以去配置文件里面查看。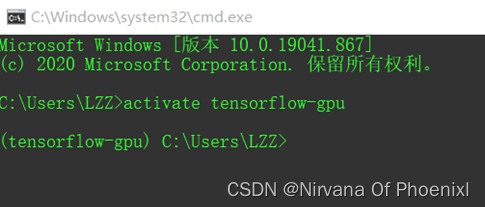
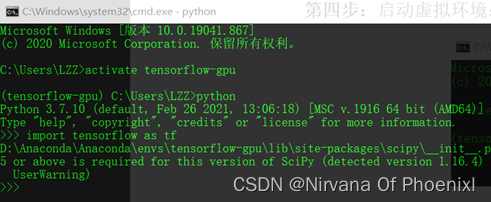 启用python环境导入tensorflow,显示安装成功。
启用python环境导入tensorflow,显示安装成功。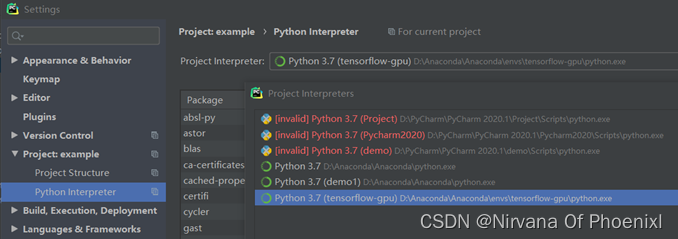 图示为Tensorflow-gpu虚拟环境。
图示为Tensorflow-gpu虚拟环境。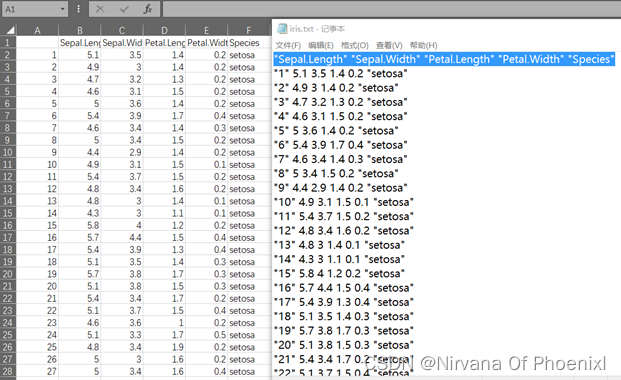 一般由两种格式.csv和.txt格式。
一般由两种格式.csv和.txt格式。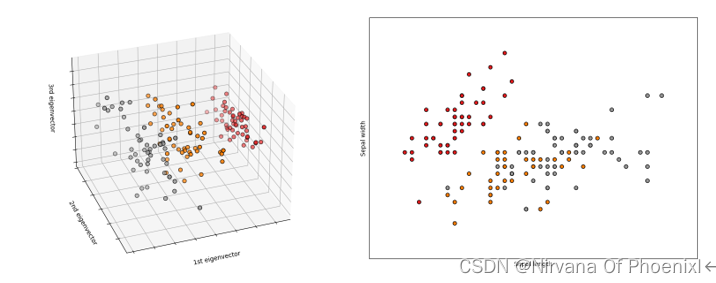
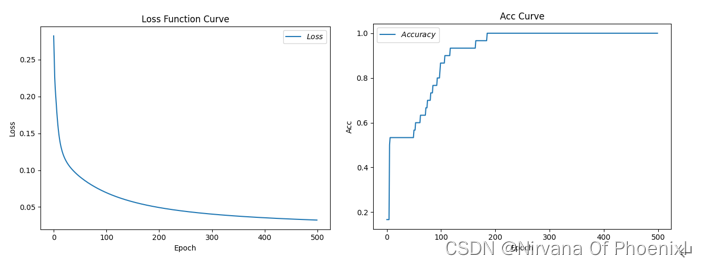
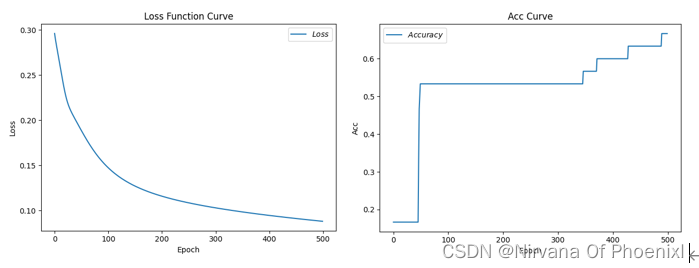
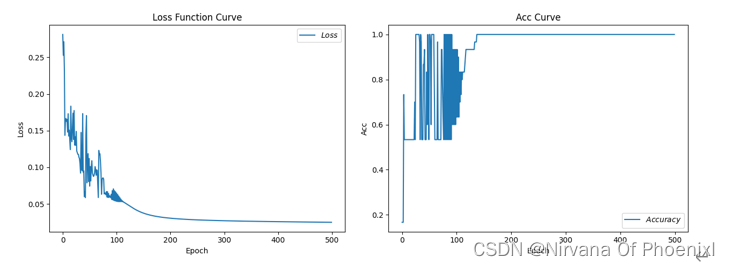
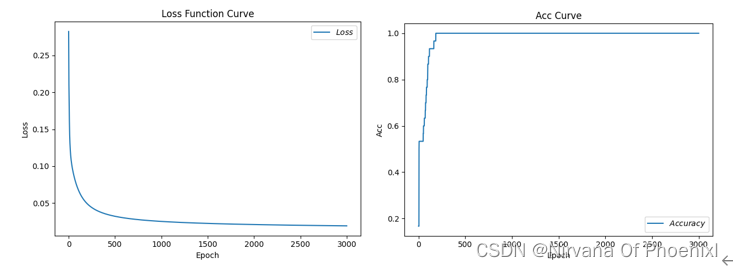 (5)学习率为0.1,循环次数186,当次数为185时,精度为1 Epoch 185, loss: 0.05128058139234781,Test_acc: 1.0
(5)学习率为0.1,循环次数186,当次数为185时,精度为1 Epoch 185, loss: 0.05128058139234781,Test_acc: 1.0 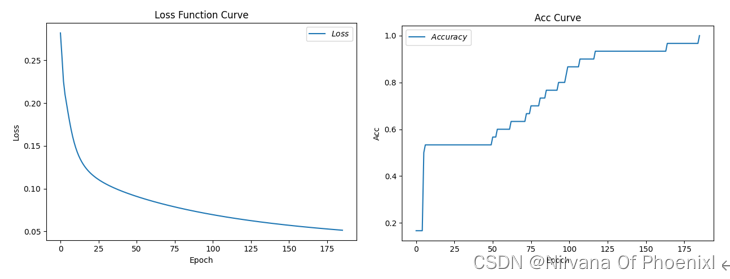
【本文地址】