| 完美搭建Hadoop HA高可用集群(亲测五台有效) | 您所在的位置:网站首页 › 高配虚拟机 › 完美搭建Hadoop HA高可用集群(亲测五台有效) |
完美搭建Hadoop HA高可用集群(亲测五台有效)
|
Hadoop HA高可用集群
一、虚拟机基础配置1、配置五台机器的防火墙、network、hostname、hosts以及免密登录1.1 修改hostname1.2 关闭防火墙1.3 配置network1.4 编辑hosts主机名映射1.5 设置.ssh免密登录
2、时间同步3、 `以上五步每台机器都要操作一遍`4、编写shell脚本4.1在`/root/bin`目录下创建xcall脚本文件4.2在`/root/bin`目录下创建xrsync脚本文件4.3在`/root/bin`目录下创建zk脚本文件
二、安装软件1、安装jdk2、安装zookeeper3、安装Hadoop
一、虚拟机基础配置
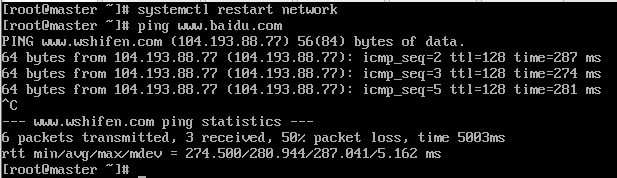
编辑好后保存退出,然后重新启动network,检查是否能正常上网。 systemctl restart network //测试上网功能 ping www.baidu.com
输入以下命令然后一直按回车,即可生成本机密钥。 ssh-keygen -t rsa
首先用yum命令下载ntp [root@master ~]# yum -y install ntp执行同步命令: root@master ~]# ntpdate time1.aliyun.com查看当前系统时间: root@master ~]# date同步系统时间到硬件时钟(防止重启系统再次同步系统时间): root@master ~]# hwclock -w 3、 以上五步每台机器都要操作一遍 4、编写shell脚本 4.1在/root/bin目录下创建xcall脚本文件 [root@master ~]# mkdir bin [root@master ~]# cd bin/ [root@master bin]# touch xcall [root@master bin]# chmod 777 xcall [root@master bin]# vi xcallxcall脚本用来集群共同执行同一命令,脚本如下: #!/bin/bash for host in master master2 slave1 slave2 slave3 do echo ------------- $host ------------- ssh $host "$*" done 4.2在/root/bin目录下创建xrsync脚本文件首先使用刚才写好的xcall脚本给集群安装rsync [root@master ~]# xcall yum -y install rsync [root@master bin]# touch xrsync [root@master bin]# chmod 777 xrsync [root@master bin]# vi xrsyncxrsync脚本用来给集群分发/同步文件,脚本如下: #!/bin/bash # 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0));then echo no args; exit; fi # 获取文件名 p1=$1 fname=`basename $p1` echo fname=$fname # 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1);pwd` echo pdir=$pdir # 获取当前用户名字 user=`whoami` # 将文件拷贝到目标机器 for host in master master2 slave1 slave2 slave3 do echo -----------$host -------------- rsync -av $pdir/$fname $user@$host:$pdir done 4.3在/root/bin目录下创建zk脚本文件 [root@master bin]# touch zk [root@master bin]# chmod 777 zk [root@master bin]# vi zkzk脚本用启动停止zookeeper服务,脚本如下: #!/bin/bash case $1 in "start"){ for i in slave1 slave2 slave3 do echo ------------ $i ------------- ssh $i "/opt/bigdata/zk345/bin/zkServer.sh start" done };; "restart"){ for i in slave1 slave2 slave3 do echo ------------ $i ------------- ssh $i "/opt/bigdata/zk345/bin/zkServer.sh restart" done };; "stop"){ for i in slave1 slave2 slave3 do echo ------------ $i ------------- ssh $i "/opt/bigdata/zk345/bin/zkServer.sh stop" done };; "status"){ for i in slave1 slave2 slave3 do echo ------------ $i ------------- ssh $i "/opt/bigdata/zk345/bin/zkServer.sh status" done };; esac 二、安装软件安装包链接: https://pan.baidu.com/s/1vt9iVA3mOEfXpUCuWPZ36Q 提取码: s6r3 首先将安装包放到/opt/install目录下,该目录需要自行创建 1、安装jdk1.1 首先创建文件夹 [root@master ~]# mkdir /opt/install [root@master ~]# mkdir /opt/bigdata1.2 使用xftp将安装包拖入install文件夹下
1.8 检查jdk是否安装成功 [root@master profile.d]# java -version java version "1.8.0_111" Java(TM) SE Runtime Environment (build 1.8.0_111-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)1.9 分发jdk文件和环境变量 [root@master ~]# xrsync /opt/bigdata/jdk180/ [root@master ~]# xrsync /etc/profile.d/env.sh //使每台机器上的环境变量生效 [root@master ~]# xcall source /etc/profile.d/env.sh //测试jdk安装成功 [root@master ~]# xcall jps ------------- master ------------- 1732 Jps ------------- master2 ------------- 1677 Jps ------------- slave1 ------------- 1658 Jps ------------- slave2 ------------- 1649 Jps ------------- slave3 ------------- 1682 Jps 2、安装zookeeper2.1 首先到zk345目录下创建zkData文件夹并在zkData目录下创建myid文件,后面在该文件中用来编辑安装zookeeper的虚拟机编号。 [root@master ~]# cd /opt/bigdata/zk345/ [root@master zk345]# mkdir zkData [root@master zk345]# cd zkData/ [root@master zkData]# touch myid [root@master zkData]# ll total 0 -rw-r--r--. 1 root root 0 Jun 9 22:15 myid
2.4 配置zookeeper环境变量 [root@master conf]# vi /etc/profile.d/env.sh //配置如下: export ZOOKEEPER_HOME=/opt/bigdata/zk345 export PATH=$PATH:$ZOOKEEPER_HOME/bin
2.6 修改salve1~3三台机器的myid [root@master ~]# ssh slave1 Last login: Tue Jun 9 20:57:10 2020 from 192.168.29.1 [root@slave1 ~]# vi /opt/bigdata/zk345/zkData/myid //在slave1的myid中只编辑一个数字1保存退出即可 [root@master ~]# ssh slave2 Last login: Tue Jun 9 20:57:11 2020 from 192.168.29.1 [root@slave2 ~]# vi /opt/bigdata/zk345/zkData/myid //在slave1的myid中只编辑一个数字2保存退出即可 [root@master ~]# ssh slave3 Last login: Tue Jun 9 20:57:33 2020 from 192.168.29.1 [root@slave3 ~]# vi /opt/bigdata/zk345/zkData/myid //在slave1的myid中只编辑一个数字3保存退出即可2.7 检查zookeeper是否配置成功 如下即zookeeper配置成功。 [root@master ~]# zk start ------------ slave1 ------------- JMX enabled by default Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ------------ slave2 ------------- JMX enabled by default Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg Starting zookeeper ... STARTED ------------ slave3 ------------- JMX enabled by default Using config: /opt/bigdata/zk345/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [root@master ~]# xcall jps ------------- master ------------- 1852 Jps ------------- master2 ------------- 1726 Jps ------------- slave1 ------------- 1748 QuorumPeerMain 1783 Jps ------------- slave2 ------------- 1776 Jps 1735 QuorumPeerMain ------------- slave3 ------------- 1765 QuorumPeerMain 1800 Jps [root@master ~]# 3、安装Hadoop3.1 启动服务配置 3.2 配置hadoop-env.sh文件 [root@master ~]# cd /opt/bigdata/hadoop260/etc/hadoop [root@master hadoop]# vi hadoop-env.sh配置如下: export JAVA_HOME=/opt/bigdata/jdk180
3.3 配置mapred-env.sh文件 [root@master hadoop]# vi mapred-env.sh配置如下: export JAVA_HOME=/opt/bigdata/jdk180
配置如下: export JAVA_HOME=/opt/bigdata/jdk180
3.5 配置slaves文件(该文件下用来配置要启动NameNode的机器的localhost) [root@master hadoop]# vi slaves配置如下: slave1 slave2 slave3
配置如下: fs.defaultFS hdfs://cluster1 hadoop.tmp.dir /opt/bigdata/hadoop260/hadoopdata hadoop.proxyuser.root.hosts * hadoop.proxyuser.root.groups * ha.zookeeper.quorum slave1:2181,slave2:2181,slave3:2181 |




 DNS1默认8.8.8.8、子网掩码、IP以及网关相关配置方法如下图:
DNS1默认8.8.8.8、子网掩码、IP以及网关相关配置方法如下图: 

 配置如下:
配置如下:
 将本机密钥拷贝到集群所有虚拟机中,这样就可以免密登录所有虚拟机。
将本机密钥拷贝到集群所有虚拟机中,这样就可以免密登录所有虚拟机。 1.3 将这三个安装包都解压到/opt/bigdata文件夹下
1.3 将这三个安装包都解压到/opt/bigdata文件夹下 1.4 将三个文件改一下名字
1.4 将三个文件改一下名字 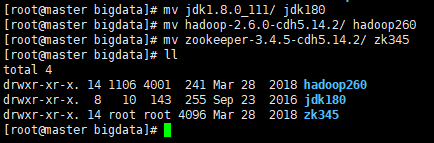 1.5 创建env.sh文件用来配置环境变量
1.5 创建env.sh文件用来配置环境变量 1.6 配置java jdk环境变量
1.6 配置java jdk环境变量 1.7 使环境变量立即生效
1.7 使环境变量立即生效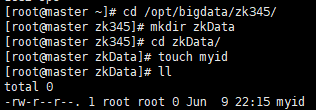 2.2 到conf目录下,拷贝一份 zoo.cfg 文件
2.2 到conf目录下,拷贝一份 zoo.cfg 文件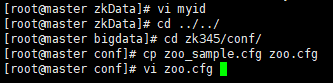 2.3 配置zoo.cfg 文件
2.3 配置zoo.cfg 文件
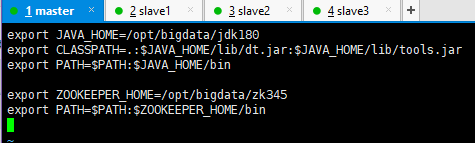 2.5 分发zookeeper和环境变量
2.5 分发zookeeper和环境变量

 3.4 配置yarn-env.sh文件
3.4 配置yarn-env.sh文件
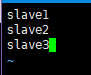 3.6 配置core-site.xml文件
3.6 配置core-site.xml文件【本文地址】