| NVIDIA新作解读:用GAN生成前所未有的高清图像(附PyTorch复现) | 您所在的位置:网站首页 › 高分辨率gan › NVIDIA新作解读:用GAN生成前所未有的高清图像(附PyTorch复现) |
NVIDIA新作解读:用GAN生成前所未有的高清图像(附PyTorch复现)
|
在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。 这是 PaperDaily 的第 15 篇文章本期推荐的是 NVIDIA 投稿 ICLR 2018 的新作 Progressive Growing GANs,论文提出了一种以渐进增大的方式更稳定地训练 GAN,实现了前所未有的高分辨率图像生成。 PaperWeekly 社区用户 @Gapeng 不仅结合 NVIDIA 官方放出的 Lasagna 代码对论文进行了详细解读,还将基于 PyTorch 对论文进行复现。 如果你对本文工作感兴趣,点击底部的阅读原文即可查看原论文。 关于作者:洪佳鹏,北京大学硕士生,研究方向为生成式对抗网络。■ 论文 | Progressive Growing of GANs for Improved Quality, Stability, and Variation ■ 链接 | http://www.paperweekly.site/papers/1008 ■ 作者 | Gapeng 今天要介绍的文章是 NVIDIA 投稿 ICLR 2018 的一篇文章,Progressive Growing of GANs for Improved Quality, Stability, and Variation[1],姑且称它为 PG-GAN。 从行文可以看出文章是临时赶出来的,毕竟这么大的实验,用 P100 都要跑 20 天,更不用说调参时间了,不过人家在 NVIDIA,不缺卡。作者放出了基于 Lasagna 的代码,今天我也会简单解读一下代码。另外,我也在用 PyTorch 做复现。 在 PG-GAN 出来以前,训练高分辨率图像生成的 GAN 方法主要就是 LAPGAN[2] 和 BEGAN[6]。后者主要是针对人脸的,生成的人脸逼真而不会是鬼脸。 这里也提一下,生成鬼脸的原因是 Discriminator 不再更新,它不能再给予 Generator 其他指导,Generator 找到了一种骗过 Discriminator 的方法,也就是生成鬼脸,而且很大可能会 mode collapse。 下图是我用 PyTorch 做的 BEGAN 复现,当时没有跑很高的分辨率,但是效果确实比其他 GAN 好基本没有鬼脸。
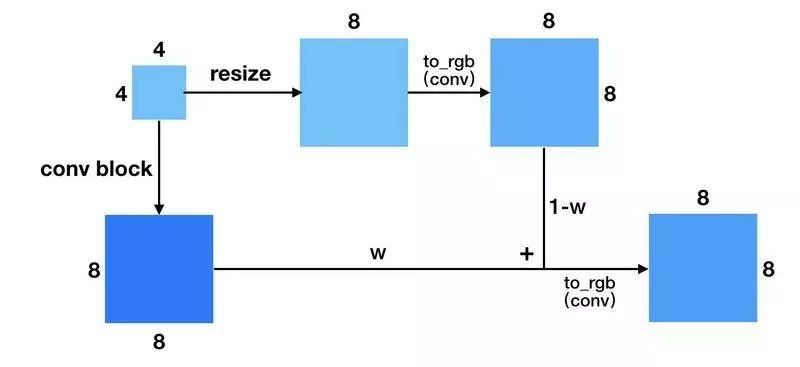
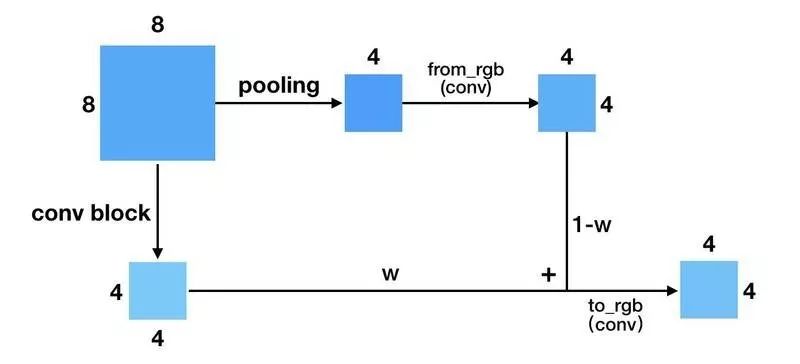
PG-GAN 能够稳定地训练生成高分辨率的 GAN。我们来看一下 PG-GAN 跟别的 GAN 不同在哪里。 1. 训练方式 作者采用 progressive growing 的训练方式,先训一个小分辨率的图像生成,训好了之后再逐步过渡到更高分辨率的图像。然后稳定训练当前分辨率,再逐步过渡到下一个更高的分辨率。 如上图所示。更具体点来说,当处于 fade in(或者说 progressive growing)阶段的时候,上一分辨率(4x4)会通过 resize+conv 操作得到跟下一分辨率(8x8)同样大小的输出,然后两部分做加权,再通过 to_rgb 操作得到最终的输出。 这样做的一个好处是它可以充分利用上个分辨率训练的结果,通过缓慢的过渡(w 逐渐增大),使得训练生成下一分辨率的网络更加稳定。 上面展示的是 Generator 的 growing 阶段。下图是 Discriminator 的 growing,它跟 Generator 的类似,差别在于一个是上采样,一个是下采样。这里就不再赘述。
不难想象,网络在 growing 的时候,如果不引入 progressive (fade in),那么有可能因为比较差的初始化,导致原来训练的进度功亏一篑,模型不得不从新开始学习,如此一来就没有充分利用以前学习的成果,甚至还可能误导。我们知道 GAN的训练不稳定,这样的突变有时候是致命的。所以 fade in 对训练的稳定性来说至关重要。 说到 growing 的训练方式,我们很容易想到 autoencoder 也有一种类似的训练方式:先训各一层的 encoder 和 decoder,训好了以后再过渡到训练各两层的 encoder 和 decoder,这样的好处是避免梯度消失,导致离 loss 太远的层更新不够充分。PG-GAN 的做法可以说是这种 autoencoder 训练方式在 GAN 训练上的应用。 此外,训练 GAN 生成高分辨率图像,还有一种方法,叫 LAPGAN[2]。LAPGAN 借助 CGAN,高分辨率图像的生成是以低分辨率图像作为条件去生成残差,然后低分辨率图上采样跟残差求和得到高分辨率图,通过不断堆叠 CGAN 得到我们想要的分辨率。
LAPGAN 是多个 CGAN 堆叠一起训练,当然可以拆分成分阶段训练,但是它们本质上是不同的,LAPGAN 学的是残差,而 PG-GAN 存在 stabilize 训练阶段,学的不是残差,而直接是图像。 作者在代码中设计了一个 LODSelectLayer 来实现 progressive growing。对于 Generator,每一层插入一个 LODSelectLayer,它实际上就是一个输出分支,实现在特定层的输出。 从代码来看,作者应该是这样训练的(参见这里的 train_gan 函数),先构建 4x4 分辨率的网络,训练,然后把网络存出去。再构建 8x8 分辨率的网络,导入原来 4x4 的参数,然后训 fade in,再训 stabilize,再存出去。我在复现的时候,根据文章的意思,修改了 LODSelectLayer 层,因为 PyTorch 是动态图,能够很方便地写 if-else 逻辑语句。 借助这种 growing 的方式,PG-GAN 的效果超级好。另外,我认为这种 progressive growing 的方法比较适合 GAN 的训练,GAN 训练不稳定可以通过 growing 的方式可以缓解。 不只是在噪声生成图像的任务中可以这么做,在其他用到 GAN 的任务中都可以引入这种训练方式。我打算将 progressive growing 引入到 CycleGAN 中,希望能够得到更好的结果。 2. 增加生成多样性 增加生成样本的多样性有两种可行的方法:通过 loss 让网络自己调整、通过设计判别多样性的特征人为引导。 WGAN 属于前者,它采用更好的分布距离的估计(Wasserstein distance)。模型收敛意味着生成的分布和真实分布一致,能够有多样性的保证。PG-GAN 则属于后者。 作者沿用 improved GAN 的思路,通过人为地给 Discriminator 构造判别多样性的特征来引导 Generator 生成更多样的样本。Discriminator 能探测到 mode collapse 是否产生了,一旦产生,Generator 的 loss 就会增大,通过优化 Generator 就会往远离 mode collapse 的方向走,而不是一头栽进坑里。 Improved GAN 引入了 minibatch discrimination 层,构造一个 minibatch 内的多样性衡量指标。它引入了新的参数。
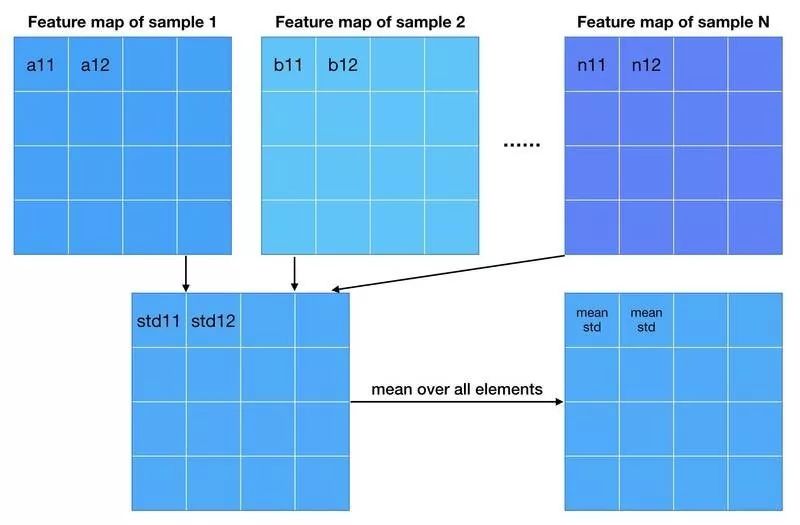
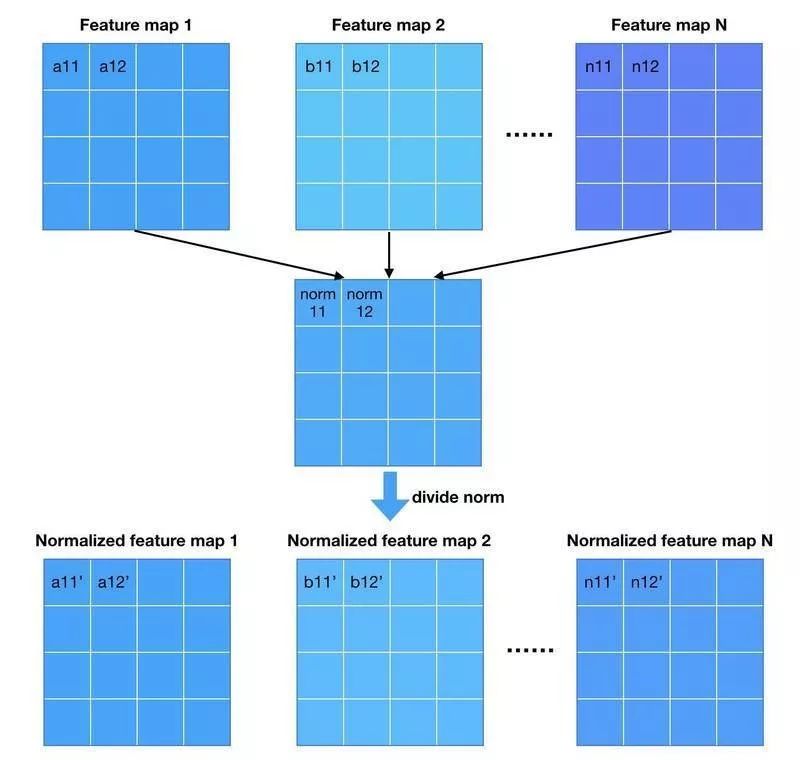
而 PG-GAN 不引入新的参数,利用特征的标准差作为衡量标准。
这里啰嗦地说明上面那张图做了什么。我们有 N 个样本的 feature maps(为了画图方便,不妨假设每个样本只有一个 feature map),我们对每个空间位置求标准差,用 numpy 的 std 函数来说就是沿着样本的维度求 std。这样就得到一张新的 feature map(如果样本的 feature map 不止一个,那么这样构造得到的 feature map 数量应该是一致的),接着 feature map 求平均得到一个数。 这个过程简单来说就是求 mean std,作者把这个数复制成一张 feature map 的大小,跟原来的 feature map 拼在一起送给 Discriminator。 从作者放出来的代码来看,这对应 averaging=“all”的情况。作者还尝试了其他的统计量:“spatial”,“gpool”,“flat”等。它们的主要差别在于沿着哪些维度求标准差。至于它们的作用,等我的代码复现完成了会做一个测试。估计作者调参发现“all”的效果最好。 3. Normalization 从 DCGAN[3]开始,GAN 的网络使用 batch (or instance) normalization 几乎成为惯例。使用 batch norm 可以增加训练的稳定性,大大减少了中途崩掉的情况。作者采用了两种新的 normalization 方法,不引入新的参数(不引入新的参数似乎是 PG-GAN 各种 tricks 的一个卖点)。 第一种 normalization 方法叫 pixel norm,它是 local response normalization 的变种。Pixel norm 沿着 channel 维度做归一化,这样归一化的一个好处在于,feature map 的每个位置都具有单位长度。这个归一化策略与作者设计的 Generator 输出有较大关系,注意到 Generator 的输出层并没有 Tanh 或者 Sigmoid 激活函数,后面我们针对这个问题进行探讨。
第二种 normalization 方法跟凯明大神的初始化方法[4]挂钩。He 的初始化方法能够确保网络初始化的时候,随机初始化的参数不会大幅度地改变输入信号的强度。
根据这个式子,我们可以推导出网络每一层的参数应该怎样初始化。可以参考 PyTorch 提供的接口。 作者走得比这个要远一点,他不只是初始化的时候对参数做了调整,而是动态调整。初始化采用标准高斯分布,但是每次迭代都会对 weights 按照上面的式子做归一化。作者 argue 这样的归一化的好处在于它不用再担心参数的 scale 问题,起到均衡学习率的作用(euqalized learning rate)。 4. 有针对性地给样本加噪声 通过给真实样本加噪声能够起到均衡 Generator 和 Discriminator 的作用,起到缓解 mode collapse 的作用,这一点在 WGAN 的前传中就已经提到[5]。尽管使用 LSGAN 会比原始的 GAN 更容易训练,然而它在 Discriminator 的输出接近 1 的适合,梯度就消失,不能给 Generator 起到引导作用。 针对 D 趋近 1 的这种特性,作者提出了下面这种添加噪声的方式:
其中, 从式子可以看出,当真样本的判别器输出越接近 1 的时候,噪声强度就越大,而输出太小( |




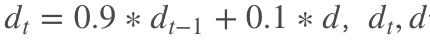 分别为第 t 次迭代判别器输出的修正值、第 t-1 次迭代真样本的判别器输出。
分别为第 t 次迭代判别器输出的修正值、第 t-1 次迭代真样本的判别器输出。 【本文地址】