| 基于DBNet和CRNN算法实现车牌识别 | 您所在的位置:网站首页 › 飞桨ocr车牌号识别 › 基于DBNet和CRNN算法实现车牌识别 |
基于DBNet和CRNN算法实现车牌识别
|
PaddleOCR: 车牌识别
1. 方案设计
车牌识别车牌识别就是使用OCR(Optical Character Recognition,光学字符识别)技术识别各类机动车车牌信息。目前,车牌识别已广泛应用在停车场、收费站、道路等交通设施中,提供高效便捷的车辆管理服务。OCR通常包含文本检测和文本识别两个子任务: 文字检测:检测图片中的文字位置; 文字识别:对文字区域中的文字进行识别。 使用OCR来识别车牌流程如 图1 所示,首先检测出车牌的位置(下图红色框区域)、然后对检测出来的车牌进行识别,即可得到右边的可编辑文本:  图1 车牌识别
图1 车牌识别
我们使用飞桨PaddleOCR实现车牌识别,接下来就一起来看看实现原理及具体实现步骤吧~ 如果您觉得本案例对您有帮助,欢迎Star收藏一下,不易走丢哦~,链接指路:https://github.com/PaddlePaddle/awesome-DeepLearning 2. 数据处理 2.1 数据集介绍CCPD车牌数据集是采集人员在合肥停车场采集、手工标注得来,采集时间在早7:30到晚10:00之间。且拍摄车牌照片的环境复杂多变,包括雨天、雪天、倾斜、模糊等。CCPD数据集包含将近30万张图片、图片尺寸为720x1160x3,共包含8种类型图片,每种类型、数量及类型说明如下表: 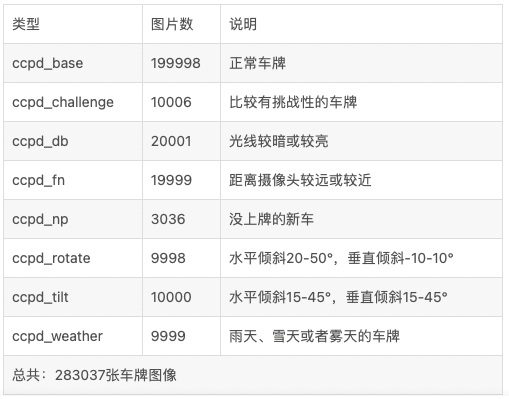 图2 CCPD数据集
注:图2来源于开源车牌数据集CCPD介绍
图2 CCPD数据集
注:图2来源于开源车牌数据集CCPD介绍
CCPD数据集中每张图像的名称包含了标注信息,例如图片名称为"025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg",每个名称可以通过分隔符’-'分为几部分,每部分解释: 025:车牌区域占整个画面的比例; 95_113: 车牌水平和垂直角度, 水平95°, 竖直113° 154&383_386&473:标注框左上、右下坐标,左上(154, 383), 右下(386, 473) 386&473_177&454_154&383_363&402:标注框四个角点坐标,顺序为右下、左下、左上、右上 0_0_22_27_27_33_16:车牌号码映射关系如下: 第一个0为省份 对应省份字典provinces中的’皖’,;第二个0是该车所在地的地市一级代码,对应地市一级代码字典alphabets的’A’;后5位为字母和文字, 查看车牌号ads字典,如22为Y,27为3,33为9,16为S,最终车牌号码为皖AY339S provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新"] alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W','X', 'Y', 'Z'] ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9']本实验我们只使用正常车牌即ccpd_base的数据进行训练。 2.2 数据预处理解压CCCP数据集: # 解压数据集 !mkdir dataset !unzip -q data/data17968/CCPD2019.zip -d dataset/CCPD %cd ~将CCPD的数据格式转换PaddleOCR检测所需格式,执行下面代码即可: import os import os.path as osp import cv2 ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X','Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] provinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新"] # 转换检测数据 train_det = open('dataset/train_det.txt', 'w', encoding='UTF-8') dev_det = open('dataset/dev_det.txt', 'w', encoding='UTF-8') # 转换识别数据 if not osp.exists('dataset/img'): os.mkdir('dataset/img') train_rec = open('dataset/train_rec.txt', 'w', encoding='UTF-8') dev_rec = open('dataset/dev_rec.txt', 'w', encoding='UTF-8') count = 0 # 总样本数 total_num = len(os.listdir('dataset/CCPD/ccpd_base')) # 训练样本数 train_num = int(total_num*0.8) for item in os.listdir('dataset/CCPD/ccpd_base'): path = 'dataset/CCPD/ccpd_base/'+item _, _, bboxs, points, labels, _, _ = item.split('-') bboxs = bboxs.split('_') x1, y1 = bboxs[0].split('&') x2, y2 = bboxs[1].split('&') bboxs = [int(coord) for coord in [x1, y1, x2, y2]] points = points.split('_') points = [point.split('&') for point in points] points_ = points[-2:]+points[:2] points = [] for point in points_: points.append([int(_) for _ in point]) labels = labels.split('_') prov = provinces[int(labels[0])] plate_number = [ads[int(label)] for label in labels[1:]] labels = prov+''.join(plate_number) # 获取检测训练检测框位置 line_det = path+'\t'+'[{"transcription": "%s", "points": %s}]' % (labels, str(points)) line_det = line_det[:]+'\n' # 获取识别训练图片及标签 img = cv2.imread(path) crop = img[bboxs[1]:bboxs[3], bboxs[0]:bboxs[2], :] cv2.imwrite('dataset/img/%06d.jpg' % count, crop) line_rec = 'dataset/img/%06d.jpg\t%s\n' % (count, labels) # 写入txt if count |
【本文地址】
公司简介
联系我们