|
今天爬取的是一个航空公司网站的航班信息–飞常准 我们需要遍历抓取每一个航班里的所有信息

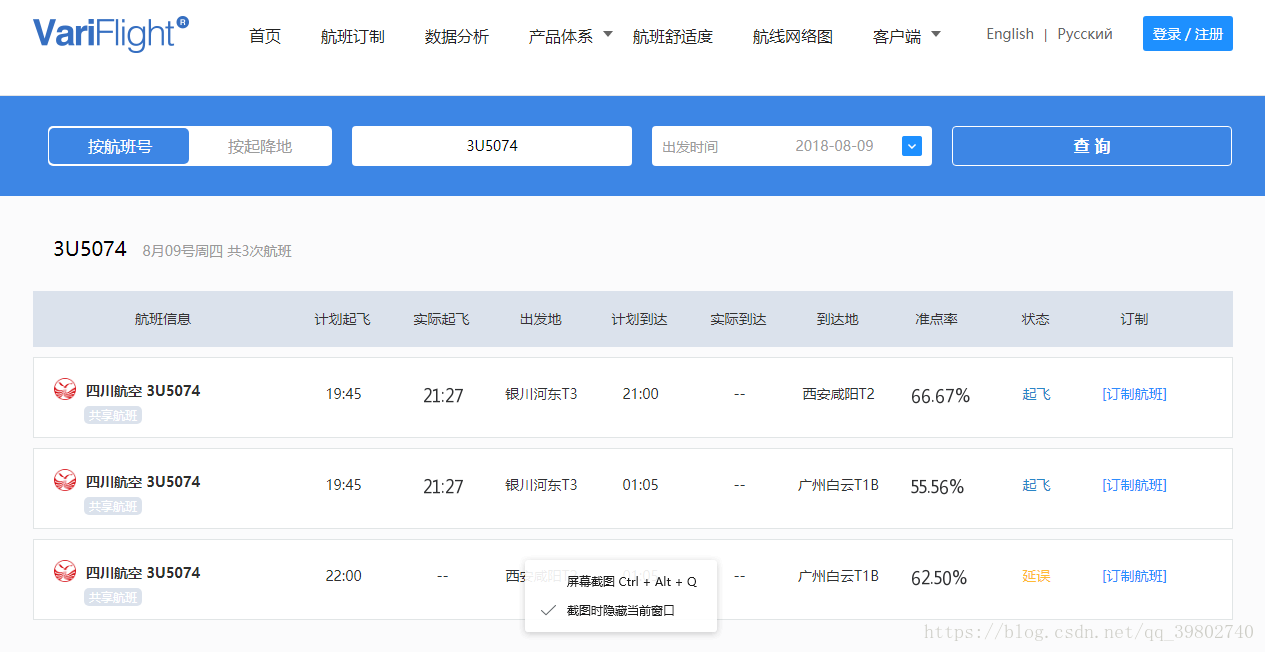 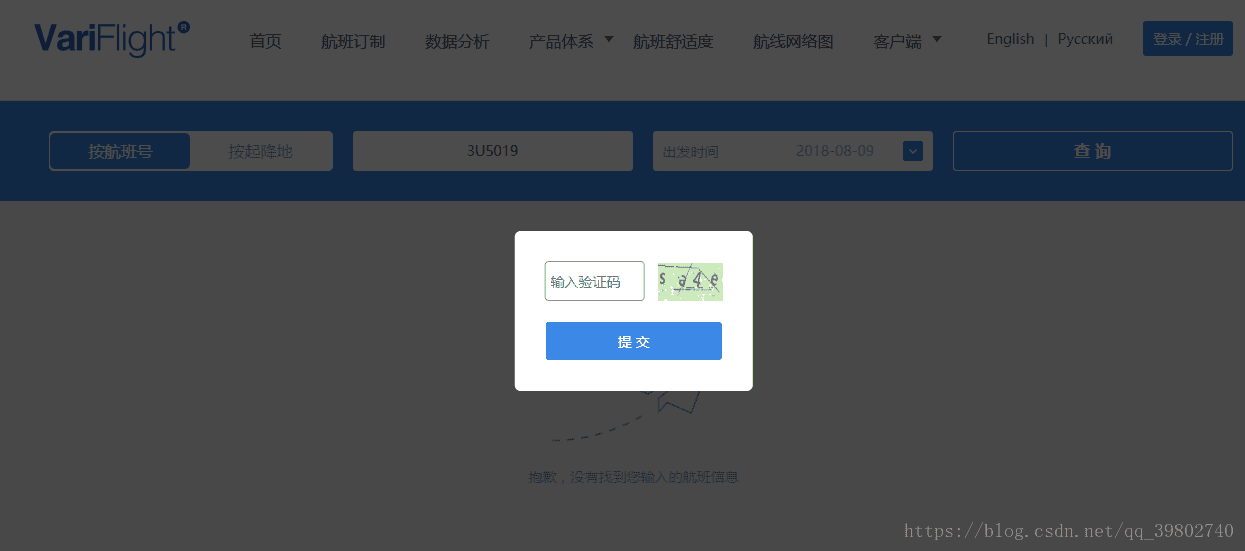 这里需要注意 有些列出来的航班可能不存在信息 需要进行一次判断 另外 访问过快会导致被该网站封号,解封会出现验证码,可以自己搭建免费ip代理池或使用收费代理 代码如下: 这里需要注意 有些列出来的航班可能不存在信息 需要进行一次判断 另外 访问过快会导致被该网站封号,解封会出现验证码,可以自己搭建免费ip代理池或使用收费代理 代码如下:
import requests
import json
import pytesseract
import re
import time
import random
from urllib.parse import urlencode
from lxml import etree
from PIL import Image
class FeiChangZhun(object):
def __init__(self):
self.base_url = 'http://www.variflight.com' # 飞常准官网
def get_list(self):
r = requests.get('http://www.variflight.com/sitemap.html?AE71649A58c77=') # 飞常准航班列表
selector = etree.HTML(r.text)
url_list = selector.xpath('//*[@class="list"]/a/@href')[1:]
# 解析出每一个航班下面的Url链接
new_list = []
for i in url_list:
new_list.append(self.base_url + i)
# 测试第一个航班数据
# mytest = new_list[9]
return new_list
def parse_html(self):
mytest = self.get_list()
proxy = self.get_ip()
for test in mytest:
try:
proxies = {"http": random.choice(proxy)}
r = requests.get(test, proxies=proxies)
selector = etree.HTML(r.text)
b = selector.xpath('//*[@class="searchlist_innerli"]')
if b:
name = selector.xpath('//*[@class="tit"]/h1/@title')[0]
log = "{0}航班存在信息:".format(name)
print(log)
# time.sleep(5)
r = requests.Session()
r.proxies = proxies
resp = r.get(test)
selector = etree.HTML(resp.text)
mylist = selector.xpath('//*[@id="list"]/li')
# print(mylist)
for selector in mylist:
a = selector.xpath('div[@class="li_com"]/span[1]/b/a//text()') # 航班信息
a = a[0] + '' + a[1]
b = selector.xpath('div[@class="li_com"]/span[2]/@dplan') # 计划起飞
c = selector.xpath('div[@class="li_com"]/span[3]/img/@src') # 实际起飞
if c:
url = self.base_url + c[0]
resp = r.get(url)
filename = './pictures' + re.search(r's=(.*?)==', url).group(0) + '.png'
with open(filename, 'wb') as f:
f.write(resp.content)
c = pytesseract.image_to_string(Image.open(filename))
if len(c) < 5: # 若识别不出‘:’或者‘.’ 进行拼接
c = c[:2] + ':' + c[2:]
else:
# c = selector.xpath('div[@class="li_com"]/span[3]/text()') # 实际起飞
# c = re.sub(r"[\s+\.\!\/_,$%^*(+\"\')]+|[+——?【】?~@#¥%……&*]+|\\n+|\\r+|(\\xa0)+|(\\u3000)+|\\t", "", str(c[0]))
c = '暂无信息'
d = selector.xpath('div[@class="li_com"]/span[4]/text()') # 出发地
e = selector.xpath('div[@class="li_com"]/span[5]/@aplan') # 计划到达
f = selector.xpath('div[@class="li_com"]/span[6]/text()') # 实际到达
f = re.sub(r"[\s+\.\!\/_,$%^*(+\"\')]+|[+?【】?~@#¥%……&*]+|\\n+|\\r+|(\\xa0)+|(\\u3000)+|\\t", "",
str(f[0]))
if f:
f = '暂无信息'
else:
f = selector.xpath('div[@class="li_com"]/span[6]/img/@src') # 实际到达
url = self.base_url + f[0]
resp = r.get(url)
filename = './pictures' + re.search(r's=(.*?)==', url).group(0) + '.png'
with open(filename, 'wb') as f:
f.write(resp.content)
f = pytesseract.image_to_string(Image.open(filename))
if len(f) < 5:
f = f[:2] + ':' + f[2:]
g = selector.xpath('div[@class="li_com"]/span[7]/text()') # 到达地
h = selector.xpath('div[@class="li_com"]/span[8]/img/@src') # 准点率
i = selector.xpath('div[@class="li_com"]/span[9]/text()') # 状态
j = selector.xpath('div[@class="li_com"]/span[10]/a[1]/text()') # 订制
h = self.base_url + h[0] # 准点率
filename = './pictures' + re.search(r's=(.*?)=', h).group(0) + '.png'
q = r.get(h)
with open(filename, 'wb') as t:
t.write(q.content)
q = pytesseract.image_to_string(Image.open(filename))
if len(q) < 5:
q = q[:2] + ':' + q[2:]
mydict = {
"title": a, # 航班信息
"start_time": b[0], # 计划起飞
"actual_start_time": c, # 实际起飞
"start_place": d[0], # 出发地
"arrive_time": e[0], # 计划到达
"actual_arrive_time": f, # 实际到达
"arrive_place": g[0], # 到达地
"on-time": q, # 准点率
"satus": i[0], # 状态
"order": j[0] # 定制
}
print(mydict)
else:
name = selector.xpath('//*[@id="byNumInput"]/@value')[0]
log = "{0}航班不存在信息".format(name)
print(log)
except:
continue
# ip代理池 根据自身情况选择免费或付费
def get_ip(self):
r = requests.get(
'http://piping.mogumiao.com/proxy/api/get_ip_bs?appKey=63a4113d5b2842869c9d2774b960cc3f&count=10&expiryDate=0&format=1&newLine=2')
mylist = r.text
myjson = json.loads(mylist)
mylist = myjson.get('msg')
pro = []
for i in mylist:
ip = "{0}:{1}".format(i.get("ip"), i.get("port"))
try:
a = requests.get('https://www.baidu.com/', proxies={'https': ip}, timeout=1)
if a.status_code == 200:
pro.append(ip)
except:
continue
return pro
def main():
Fei = FeiChangZhun()
Fei.parse_html()
if __name__ == '__main__':
main()
效果图如下: 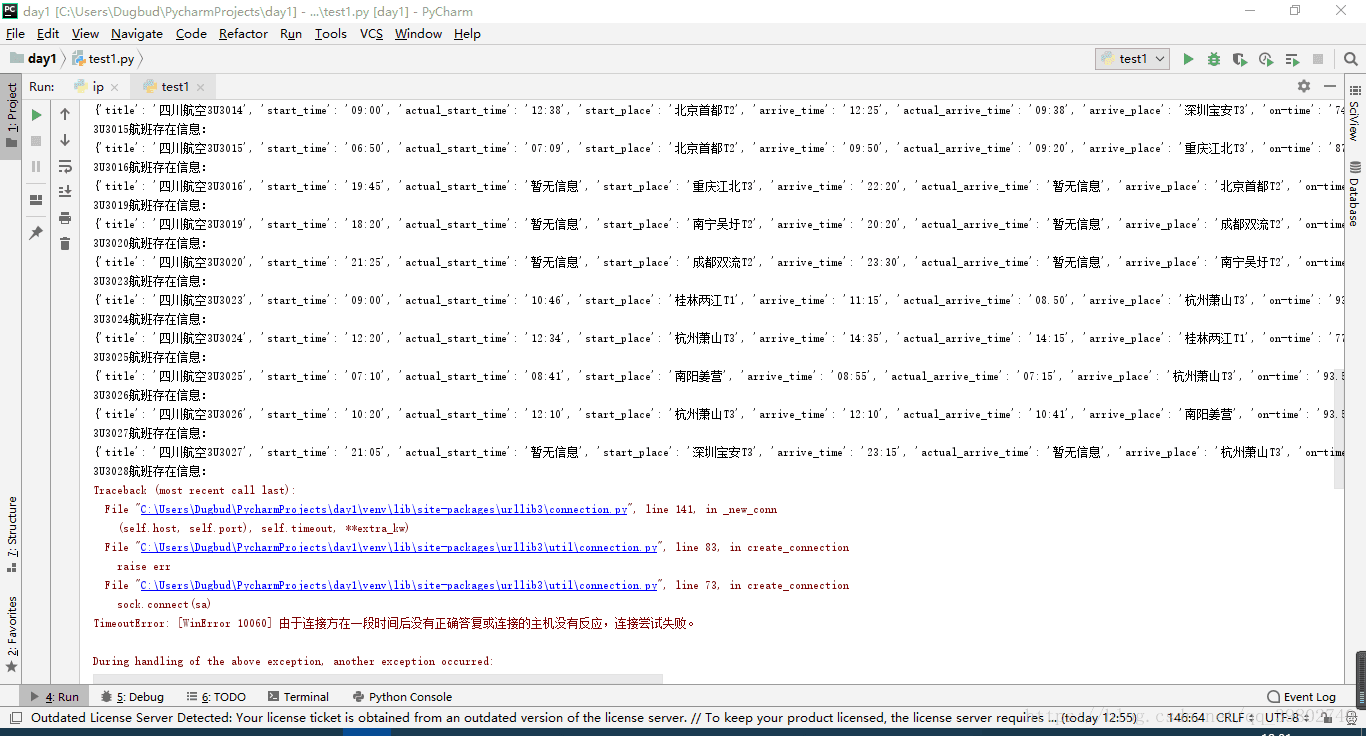
由于航班信息是实时性较强的,所以使用原生的requests来写爬虫会比使用框架更好更方便。
|