| 遗传算法解决TSP问题(完整报告,含全部代码) | 您所在的位置:网站首页 › 遗传算法是什么算法 › 遗传算法解决TSP问题(完整报告,含全部代码) |
遗传算法解决TSP问题(完整报告,含全部代码)
|
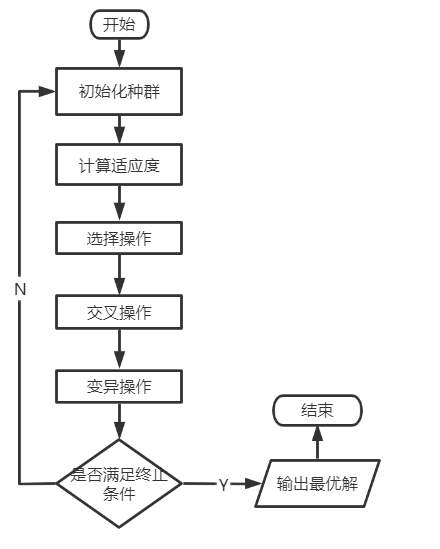
一. 了解TPS问题 旅行商问题TSP问题(Travelling Salesman Problem)即旅行商问题,又译为旅行推销员问题、货郎担问题,是数学领域中著名问题之一。假设有一个旅行商人要拜访n个城市,他必须选择所要走的路径,路径的限制是每个城市只能拜访一次,而且最后要回到原来出发的城市。路径的选择目标是要求得的路径路程为所有路径之中的最小值。 TSP 问题是一个组合优化问题,在上个学期学过的算法课中学习到旅行商问题也是一个 NP 完全问题,使用通常的解法往往需要耗费大量的时间,使用遗传算法,在较短的时间里找到一个可接受的解,但是不一定是最优的解。 遗传算法通过书本以及老师在课堂上对进化算法与遗传算法这一章节的讲解,可以对遗传算法有一个初步的了解。 遗传算法(Genetic Algorithm, GA)起源于对生物系统所进行的计算机模拟研究。它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。 受达尔文进化论“物竞天择,适者生存”思想的启发,遗传算法模拟物竞天择的生物进化过程,通过维护一个潜在解的群体执行了多方向的搜索,并支持这些方向上的信息构成和交换。是以面为单位的搜索,比以点为单位的搜索,更能发现全局最优解。遗传算法是模仿生物遗传学和自然选择机理,通过人工方式结构的一类优化搜索算法,是对生物进化过程进行的一种数学仿真,是进化计算的一种最重要形式。 二. 算法实现 在本课程时学习到了遗传算法的基本流程,如下图:
图 1遗传算法的流程图 1. 初始化种群 初始化初始化并种群的基本参数
图 2 初始化并种群的基本参数 其中包括设定了种群的数目大小,citynum=20,也就是说这个旅行商TSP问题需要走过20个城市,坐标的大小范围在0-100之间也是规定了种群的空间范围,迭代次数为100,交叉概率pc以及变异概率pm。 随机产生初始化群体的坐标位置以及计算城市之间的距离
图 3 随机产生初始化群体的坐标位置以及计算城市之间的距离 在已经定义的城市坐标的范围下,通过random随机函数,依次为0-20个城市定义坐标,再通过已有的坐标的x,y计算城市之间的距离。 2.计算适应度 从第一个城市开始对进行解码,通过calFitness函数得到计算路径距离矩阵
图 4 计算线路距离矩阵 在主函数中再进行适应度的计算,通过贪婪策略,逐次的遍历,从0到popsize也就是100,输入pops[i]以及dis_matrix得到100次每个城市的fits。 在其中找到最小的解,保留最优的解,也就是最好的适应度,并输出初代最优值。
图 5 计算适应度 3. 选择操作 选择算子可视为模拟自然选择的一个自然界选择的一个人工版,体现了进化论中的“优胜劣汰”的思想,其执行主要依赖于个体的适应度。在遗传算法在这里的选择中有轮盘赌选择,随机遍历抽样,局部选择,截断选择以及锦标赛选择。其中最常用的是轮盘赌选择,以及锦标赛选择这两种选择操作。在这里使用的是锦标赛选择算法。 参考课本以及代码,可以总结出,锦标赛方法选择策略每次从种群中取出一定数量个体,然后选择其中最好的一个进入子代种群。重复该操作,直到新的种群规模达到原来的种群规模。联赛选择的执行过程如下: 步骤1从群体中随机选择M个个体,计算每个个体的目标函数值; 步骤2根据每个个体的目标函数值,计算其适应度; 步骤3选择适应度最大的个体。 类似于赌轮选择,联赛选择每执行一次仅选择-一个个体。联赛选择的执行过程相对比较简单,但是需要定义一个额外的参数M。实际上,M决定了群体的选择压。 在这里M就是之前定义过的锦标赛小组大小tournament_size = 5。
图 6锦标赛选择算子 4. 交叉操作 通过交叉算子来维持种群的多样性,应该说交叉算子是遗传算法中最重要的操作,也是遗传算法区别于其他算法之。所在针对不同的优化问题,有多种不同的交叉算子,例如,单点交叉,两点交叉,顺序交叉等。在这里使用的是顺序交叉的算法。 顺序交叉: 在两个父代染色体中随机选择起始和结束位置,将父代染色体1该区域内的基因复制到子代1相同位置上,再在父代染色体2上将子代1中缺少的基因按照顺序填入。另一个子代以类似方式得到。 假设两个父代:A=764235801,B=073684152 查找交换基因,(交叉位同样选第四位和第七位)比如A当中235要用684去换,B中的684要用235换,那么将A中的684和B中的235都换成,得到A’=7HH235H01,B’=07H6841HH,然后将H都移到交叉位里面,将原来交叉位里面的数字都左移到最左边。再将H替换,上面的H用684换,下面的H用235换。最后顺序交叉的结果为A’’’=135|684|017,B’’’=684|235|107
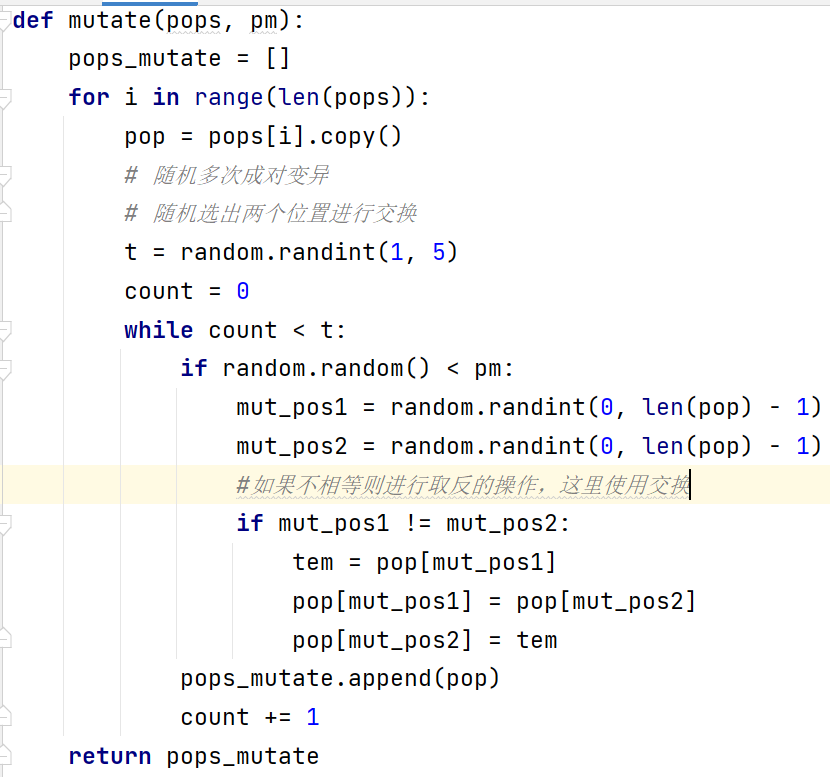
图 7 顺序交叉算子 在这里先初始化孩子,父母两个。 随机在[0,1]之间生成一个均匀分布的随机数rand。如果rand>=设定的交叉概率pc,则孩子保留父代中的一个。否则先使child复制parent1,再通过顺序交叉与parent2不断交叉并更新自己。 5. 变异操作 遗传算法的变异算子旨在模仿生物界的基因突变过程。变异算子对执行完交叉操作后的群体中的每个个体以概率pm执行变异操作。在这里的变异操作使用的是,基本位变异算子。 基本位变异算子是最简单和最基本的变异操作算子。对于基本遗传算法中用二进制编码符号串所表示的个体,若需要进行变异操作的某一基因座上的原有基因值为0,则变异操作将该基因值变为1;反之,若原有基因值为1,则变异操作将其变为0。 基本位变异算子的具体执行过程如下: (1)对个体的每一个基因座,依变异概率Pm指定其为变异点; (2)对每一个指定的变异点,对其基因值做取反运算或用其他等位基因值来代替,从而产生出一个新的个体;
图 8 变异操作 首先对每一个个体的i个二进制位,在[0,1]之间随机产生l个均匀分布的随机数,记为rand…,randi。 如果randi; end_pos: tem_pop = start_pos start_pos = end_pos end_pos = tem_pop child[start_pos:end_pos + 1] = parent1[start_pos:end_pos + 1].copy() # parent2 -> child list1 = list(range(end_pos + 1, len(parent2))) list2 = list(range(0, start_pos)) list_index = list1 + list2 j = -1 for i in list_index: for j in range(j + 1, len(parent2)): if parent2[j] not in child: child[i] = parent2[j] break child_pops.append(child) return child_pops # 变异操作 def mutate(pops, pm): pops_mutate = [] for i in range(len(pops)): pop = pops[i].copy() # 随机多次成对变异 # 随机选出两个位置进行交换 t = random.randint(1, 5) count = 0 while count < t: if random.random() < pm: mut_pos1 = random.randint(0, len(pop) - 1) mut_pos2 = random.randint(0, len(pop) - 1) #如果不相等则进行取反的操作,这里使用交换 if mut_pos1 != mut_pos2: tem = pop[mut_pos1] pop[mut_pos1] = pop[mut_pos2] pop[mut_pos2] = tem pops_mutate.append(pop) count += 1 return pops_mutate # 画路径图 def draw_path(line, CityCoordinates): x, y = [], [] for i in line: Coordinate = CityCoordinates[i] x.append(Coordinate[0]) y.append(Coordinate[1]) x.append(x[0]) y.append(y[0]) plt.plot(x, y, 'r-', color='#FF3030', alpha=0.8, linewidth=2.2) plt.xlabel('x') plt.ylabel('y') plt.show() if __name__ == '__main__': # 参数 CityNum = 20 # 城市数量 MinCoordinate = 0 # 二维坐标最小值 MaxCoordinate = 101 # 二维坐标最大值 # GA参数 generation = 100 # 迭代次数 popsize = 100 # 种群大小 tournament_size = 5 # 锦标赛小组大小 pc = 0.95 # 交叉概率 pm = 0.1 # 变异概率 # 随机生成城市的坐标,城市序号为0,1,2,3...直到CityNum的数目20 CityCoordinates = \ [(random.randint(MinCoordinate, MaxCoordinate), random.randint(MinCoordinate, MaxCoordinate)) for i in range(CityNum)] # 计算城市之间的距离 dis_matrix = \ pd.DataFrame(data=None, columns=range(len(CityCoordinates)), index=range(len(CityCoordinates))) for i in range(len(CityCoordinates)): xi, yi = CityCoordinates[i][0], CityCoordinates[i][1] for j in range(len(CityCoordinates)): xj, yj = CityCoordinates[j][0], CityCoordinates[j][1] dis_matrix.iloc[i, j] = round(math.sqrt((xi - xj) ** 2 + (yi - yj) ** 2), 2) iteration = 0 # 初始化,随机构造 pops = \ [random.sample([i for i in list(range(len(CityCoordinates)))], len(CityCoordinates)) for j in range(popsize)] #画出随机得到的城市连接图 draw_path(pops[i], CityCoordinates) # 计算适应度 fits = [None] * popsize for i in range(popsize): fits[i] = calFitness(pops[i], dis_matrix) # 保留当前最优,最小的fits为最优解 best_fit = min(fits) best_pop = pops[fits.index(best_fit)] print('初代最优值 %.1f' % (best_fit)) best_fit_list = [] best_fit_list.append(best_fit) while iteration child_fits[i]: fits[i] = child_fits[i] pops[i] = child_pops[i] if best_fit > min(fits): best_fit = min(fits) best_pop = pops[fits.index(best_fit)] best_fit_list.append(best_fit) print('第%d代最优值 %.1f' % (iteration, best_fit)) iteration += 1 # 路径顺序 print(best_pop) draw_path(best_pop, CityCoordinates) |








【本文地址】