| 2023年目标检测研究进展 | 您所在的位置:网站首页 › 近两年的时事新闻有哪些 › 2023年目标检测研究进展 |
2023年目标检测研究进展
|
综述
首先关于写这个笔记,我个人思考了很久关于以下几点。1:18年开始从做OCR用到图像和文本这种多模态联合处理的后,也就有意识的开始关注自然语言处理,这样的结果导致可能停留在前期图像上的学习和实践,停滞的研究如果在观点理解上有误希望大家给出可落地的建议,在此感谢。 2:我是14年从数学建模应用实践开始入手在遥感,医学,自动驾驶,文字图像的底层原理研究及系统方向性探索。 3:离散信息和连续信息处理目前这种编解码思路效果挺好,但是时效成本导致对普通人意义不大,只是谈资并非重大工程进展,科学对普通人影响需要很多年,工程就很直接了。 4:我个人理解计算机视觉理论从成像原理,信号处理,数字图像处理,深度学习图像处理,通用人工智能图像处理,以后可能会在认知智能和具身智能上的突破需要的其实是一套软硬件联合发展系统认识方法论,工程化建模方法,生产力工具。所以该领域探索空间还是很大。 5:近期看到未来科技大奖非常激动,这是对在人工智能领域探索的人一个高度肯定。只不过这在深度学习领域目前从全球来看,做出重大贡献的是华人“孙剑,何凯明,贾杨清,韩松,陈天奇”都算而不是一篇论文署名。有一个细节点很多外界资料忽视了,该奖成果都是在微软亚洲研究院工作和实习期间完成了并非大学,所以说大学就…,。同时韩松老师其实非常强只是外行根本看不懂,他至今成功的将研究成果转为为公司卖掉两次了,同时目前在MIT。当然何凯明从去年听说要加入MIT,今年看已经落实了,纵观科学和产业界你可以不信大佬人品但永远不要怀疑大佬认知,MIT和Stanford及UCB还是现代科学巅峰殿堂。 6:个人总结了下计算机视觉深度学习领域相关贡献内容是Alexnet(首次实现训练),VGGNet(首次实现并行),ResNet(首次实现了恒等映射),MoblieNet(首次实现了depthwise和pointwise研究),SENet(首次实现注意力),ViT(首次实现可训练编解码器)的backbone;FasterRCNN,YOLO,SSD,CornerNet,CenterNet,CascadeRCNN,DERT,QueryDet,DiffusionDet。 7:未来探索应该还是图像和文本甚至语音之间方法互相借用,从而在多模态上表达更好的实验效果和科学理论体系探索。 8:由于算法规模指数增长,芯片和操作系统在没有重大进步之前人工智能系统性理论性的革命工作暂时不会有更好的成就,这也应该是目前很多领域一流学者重回学术界的本质,其实曾经贝尔实验室的肖克利和他七个学生也是这样,才有了今天的英特尔,AMD,NVIDIA。 摘要1:本文主要总结近两年的部分目标检测成果。2:本文通过这些研究给出学派发展方向参考。3:本文针对理论基础研究进行探索性的分析。4:个人目前相关工作内容的一些基本的介绍(命名实体识别,文献情报分析,摘要内容生成,亚像素图像处理,超分辨图像处理,编码器,解码器,生成器,判别器,基于加瓦罗定理及海涅定理的认知计算理论研究,基于多模态可编程异构的下一代芯片设计,互联实时芯片操作系统) Glod-YOLO(NIPS2023)
论文地址:https://arxiv.org/abs/2307.12612 代码地址:https://github.com/huawei-noah/noah-research/tree/master/Focus-DETR
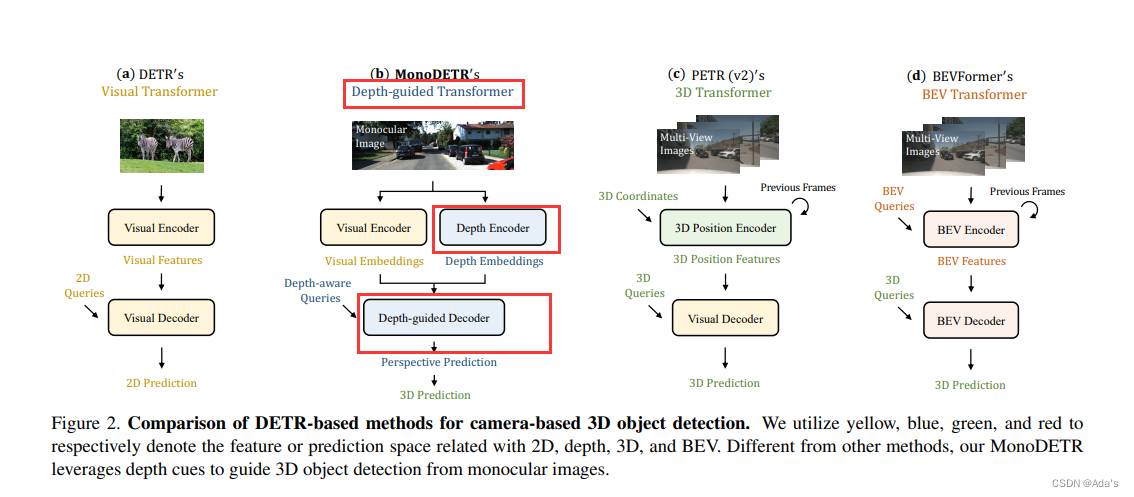
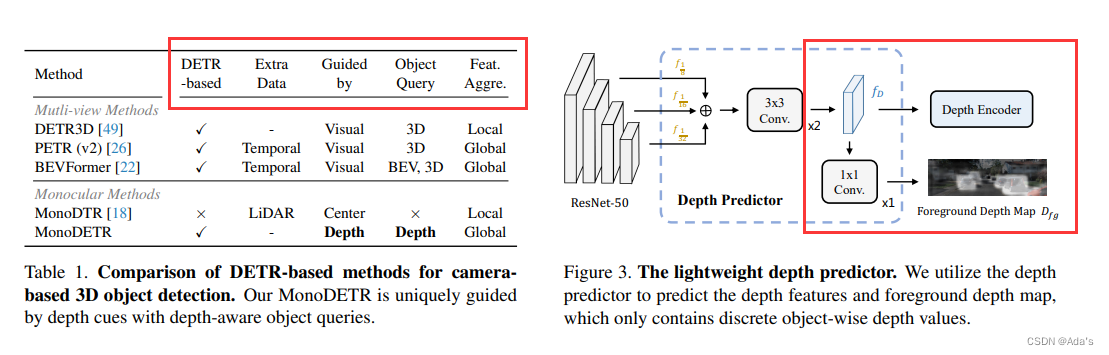
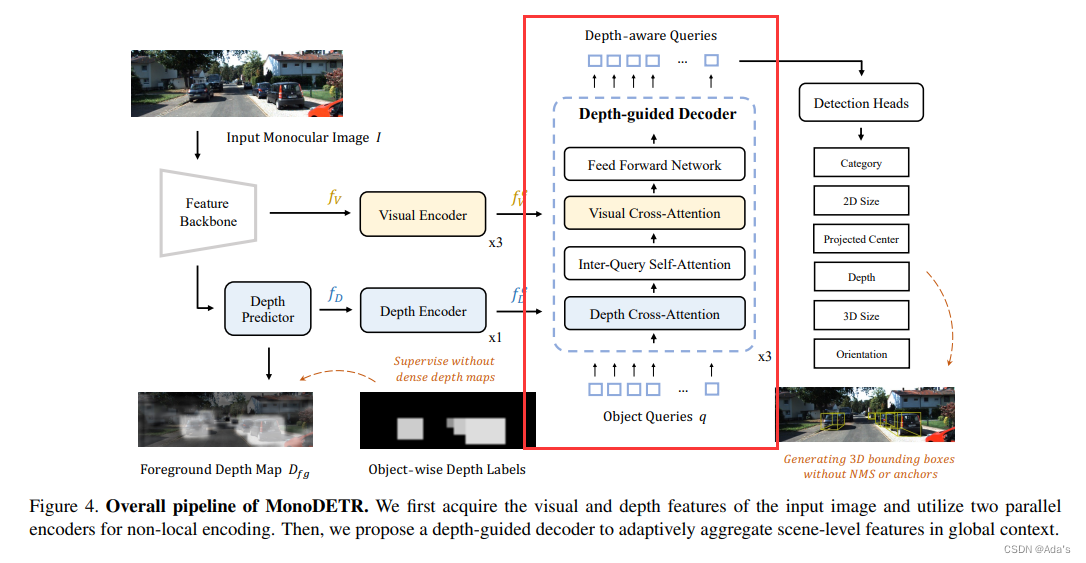
文章地址:https://arxiv.org/abs/2203.13310 代码地址:https://github.com/ZrrSkywalker/MonoDETR (1)提出了MonoDETR[1],第一个基于端到端DETR的检测器,用于没有额外输入的单目3D检测,它使object queries能够自适应地探索深度引导下的信息图像特征。 (2)MonoDETR引入了最小的手工制作设计,但通过具有复杂几何先验的最先进的基于中心的方法实现了具有竞争力的性能。 (3)MonoDETR是未来研究的一个简单但有效的Transformer baseline,进行了充分的消融研究以证明其有效性。
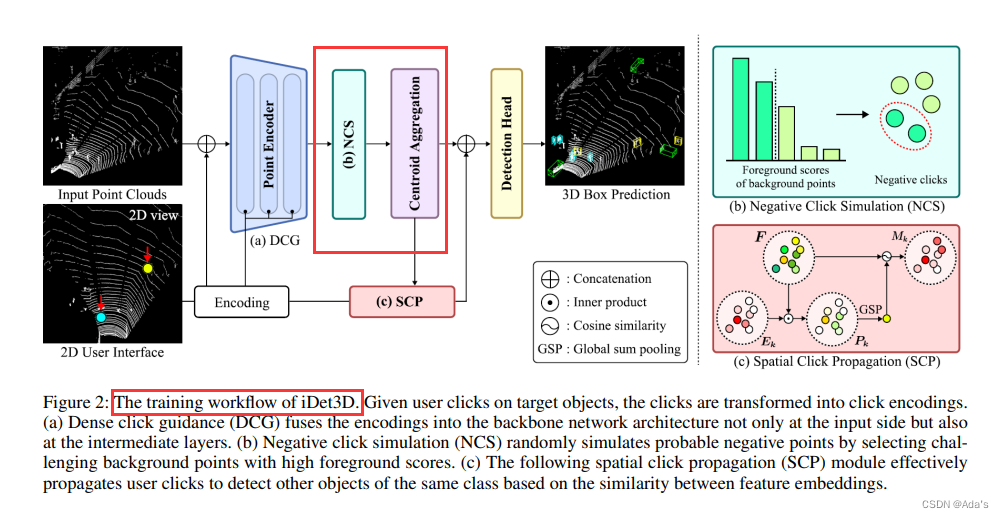
交互式3D目标检测器,Det3D支持用户友好的2D界面,可以减轻探索3D空间提供点击交互的认知负担,使用户能够以最少的交互来标注每个场景中的整个物体。考虑到三维点云的稀疏性,我们设计了负点击模拟( negative click simulation,NCS ),通过减少假阳性预测来提高精度。此外,iDet3D结合了两种点击传播技术,以充分利用用户交互:( 1 )密集点击引导( DCG ),用于在整个网络中保存用户提供的信息;( 2 )空间点击传播( SCP ),用于根据用户指定的对象检测同一类的其他实例。通过我们的大量实验,我们发现我们的方法可以在少量的点击中构建精确的注释,这表明了我们的方法作为三维物体检测的有效注释工具的实用性。
|

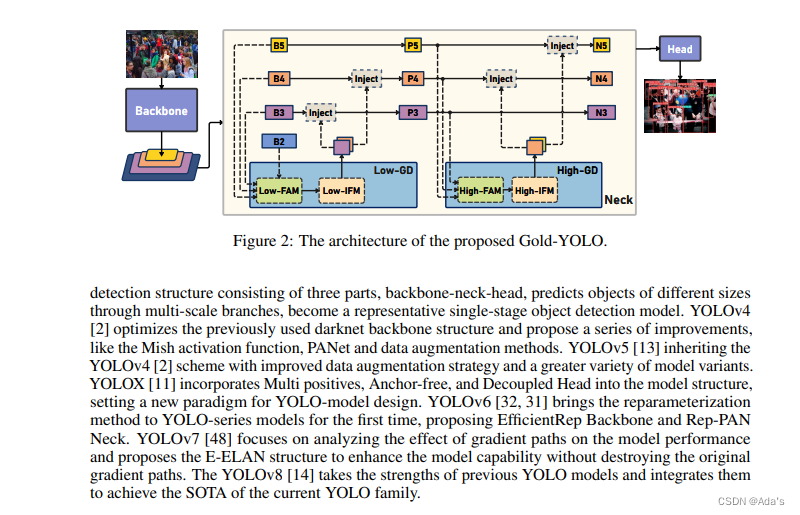
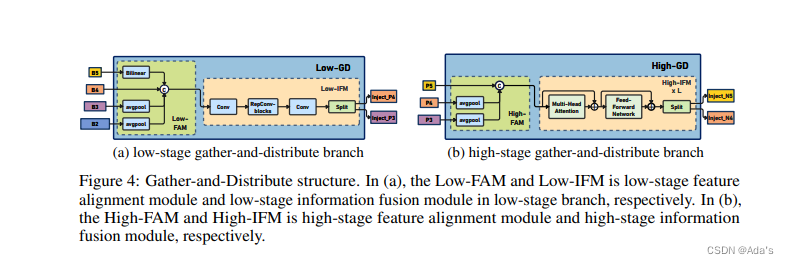
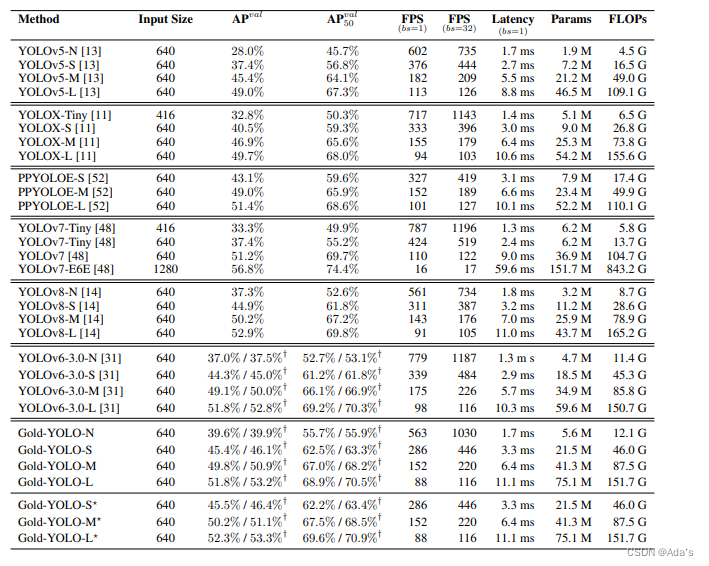

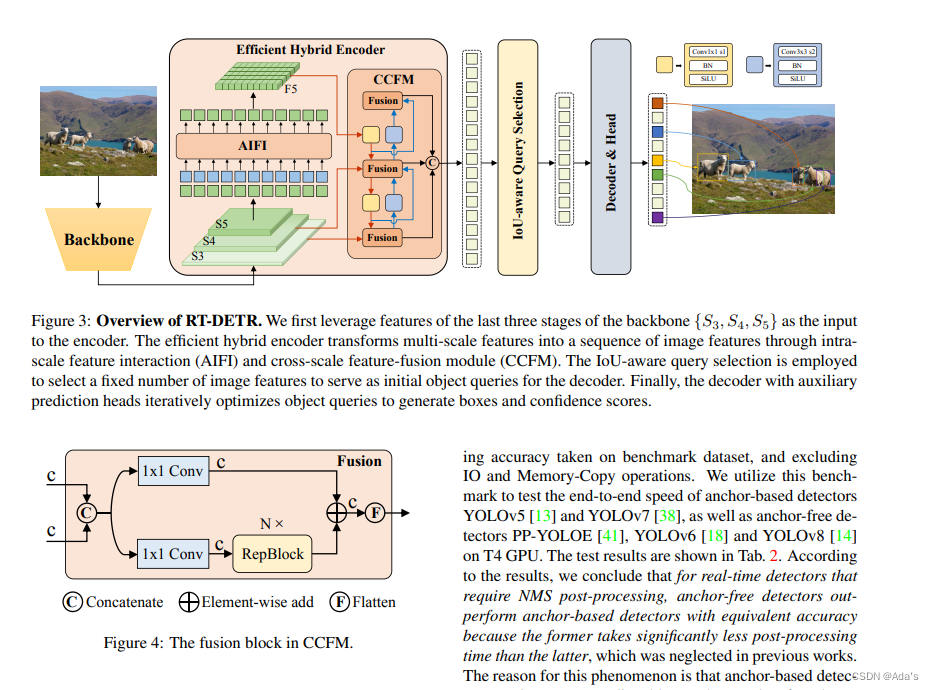
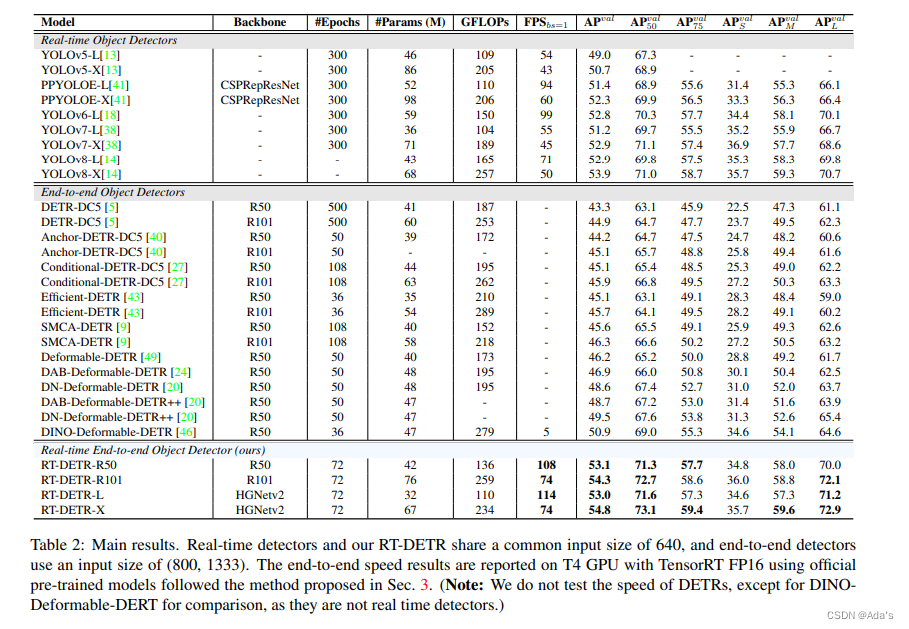
 1:阐明目前虽然取得很好效果但是存在的问题是编码器的计算负担太重 2:本文基于问题给出的解决方案和及参考的方法论文和工程化建模方法 3:基于方法本文相对稀疏编码取得更好效果的结论证明该方法有效性
1:阐明目前虽然取得很好效果但是存在的问题是编码器的计算负担太重 2:本文基于问题给出的解决方案和及参考的方法论文和工程化建模方法 3:基于方法本文相对稀疏编码取得更好效果的结论证明该方法有效性 
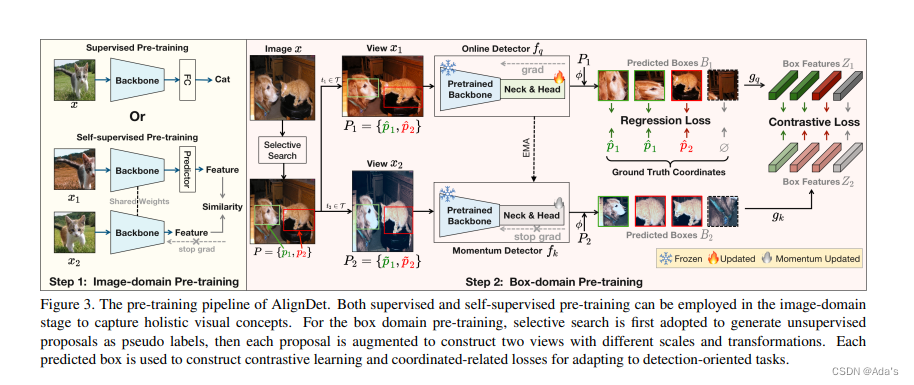
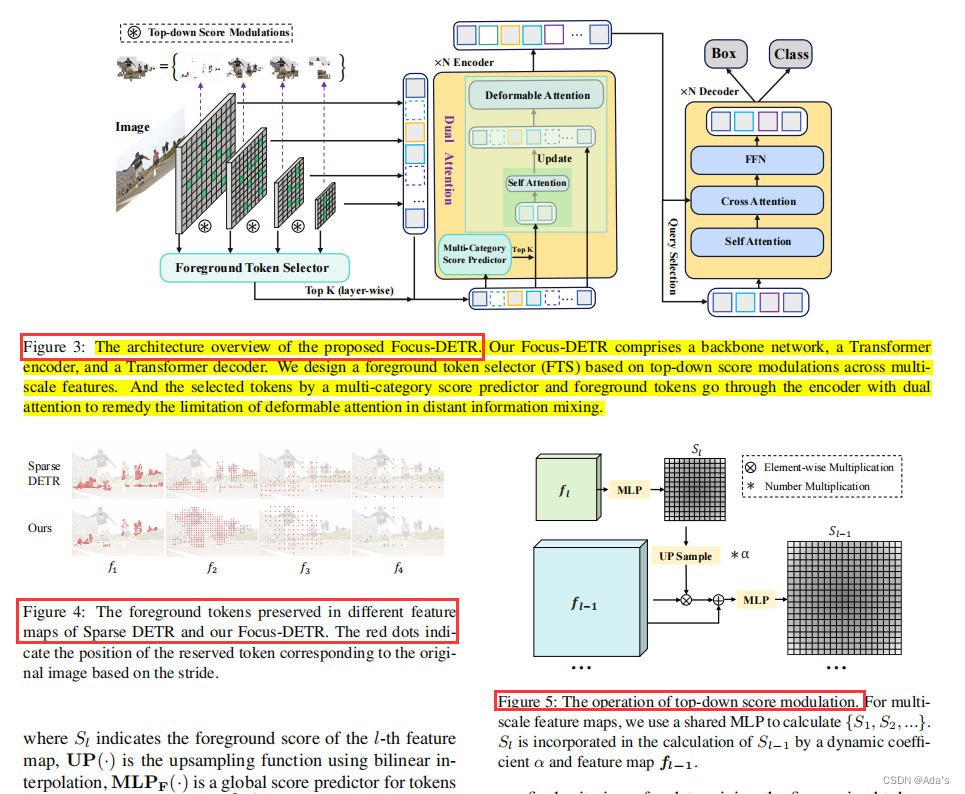 1:介绍了本文的核心贡献,2:实现细节的工程化方法,3:该方法的核心理论效果,4:证明了这种设计结果优势
1:介绍了本文的核心贡献,2:实现细节的工程化方法,3:该方法的核心理论效果,4:证明了这种设计结果优势 
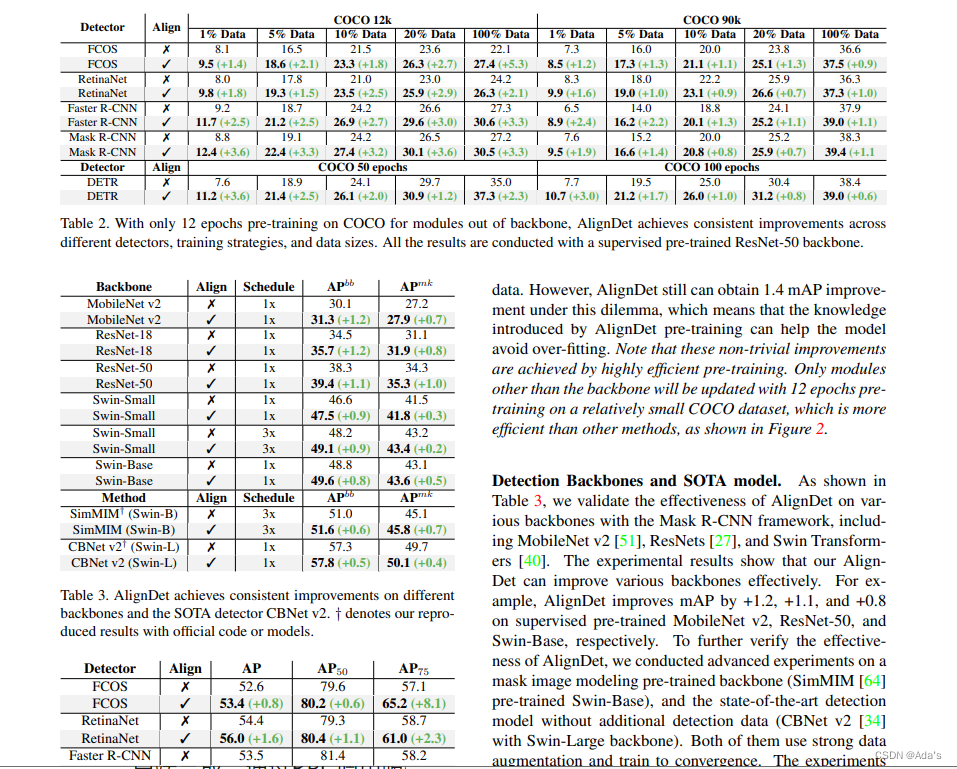
 1:对取得的结果进行定性分析和定理分析
1:对取得的结果进行定性分析和定理分析 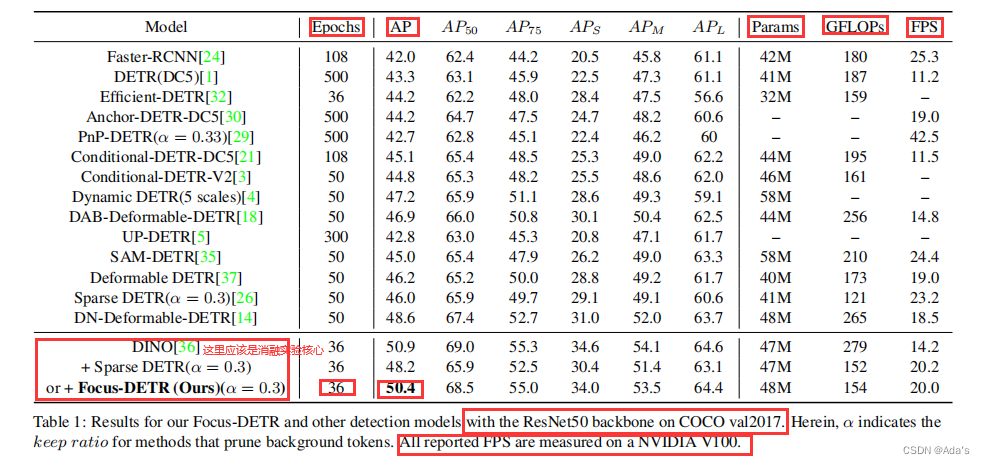
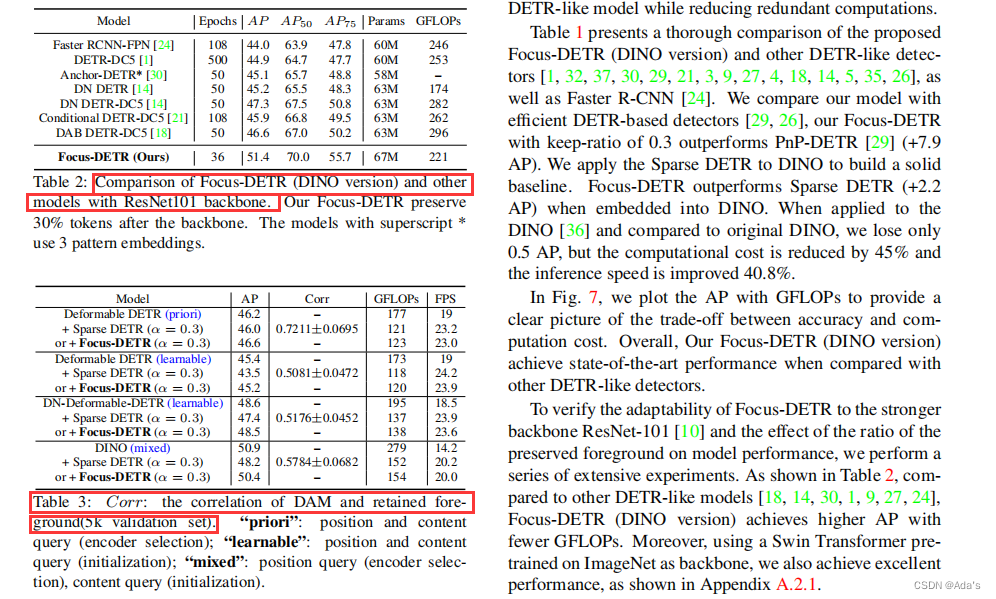

 前后景的可视化效果
前后景的可视化效果  总结: 1:该论文结果非常严密,说明作者学术功底不错,写作规范和用语标准说明语言表达能力卓越 2:dual attention能给出非常详尽的算法理论实现逻辑基础,说明该作者数理逻辑和论文建模水平很高 3:一篇论文一般从摘要,结论,方法,实验过程看系统性,完整性,有效性,这篇论文具体的代码工程我没复现过效果,但是有一点个人认为不足的就是文献引用部分,这部分看了下,如果从论文方法注意力部分,模型结构,这种结构特点看结合文献,文献引用较差。说明作者在该领域时间并不久,系统性构建研究方法论的水平还有提提升空间 4:以上内容是针对本文阅读理解初步认识,不代表任何论文本身价值,仅此致敬相关研究领域的研究人员。
总结: 1:该论文结果非常严密,说明作者学术功底不错,写作规范和用语标准说明语言表达能力卓越 2:dual attention能给出非常详尽的算法理论实现逻辑基础,说明该作者数理逻辑和论文建模水平很高 3:一篇论文一般从摘要,结论,方法,实验过程看系统性,完整性,有效性,这篇论文具体的代码工程我没复现过效果,但是有一点个人认为不足的就是文献引用部分,这部分看了下,如果从论文方法注意力部分,模型结构,这种结构特点看结合文献,文献引用较差。说明作者在该领域时间并不久,系统性构建研究方法论的水平还有提提升空间 4:以上内容是针对本文阅读理解初步认识,不代表任何论文本身价值,仅此致敬相关研究领域的研究人员。




【本文地址】