| 前端实训项目报告 | 您所在的位置:网站首页 › 购物网站实训报告 › 前端实训项目报告 |
前端实训项目报告
|
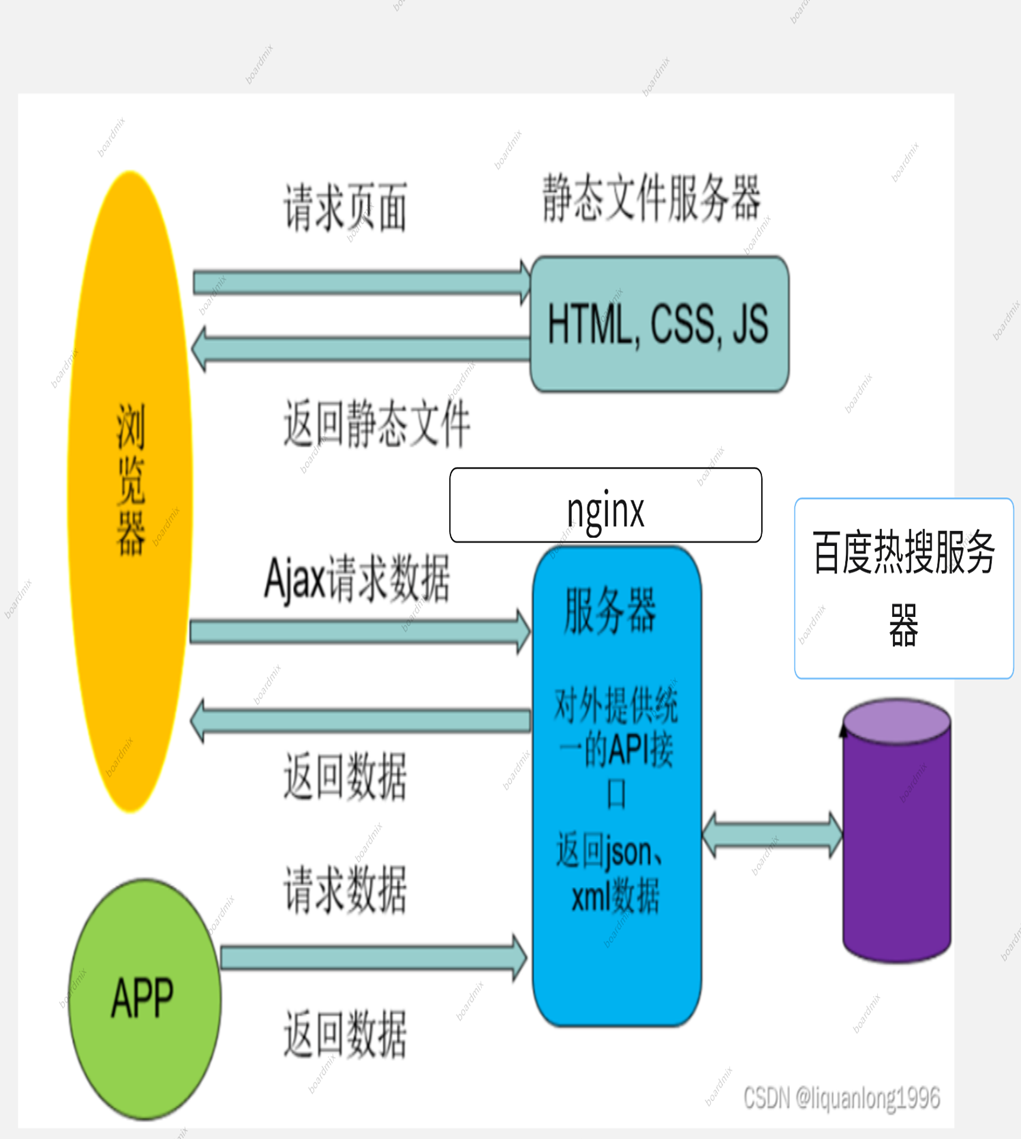
项目名称:Python爬虫课程实训 开发工具:pycharm,xbuilder,nginx 运行环境:python 3.11 所用技术:flask服务端,nginx反向代理, 项目分析 项目分析本项目为制作一个动态更新的网页,对于本任务来说,主要分为三个部分: 第一部分——架构搭建 首先使用xbuilder编译器制作我们所需的网页框架,根据项目需求,将页面分为七个部分,其中分为两大部分,分别是top,bottom。由于在html中元素只能以矩形的形式生成,因此将bottom部分再次分为三个子部分(left,center,right),其中对于left部分无需修改,但对于center部分,还需将其分为三个小份,对于right部分同理分为两份。 考虑到项目中对其中一部分需要有横向排列,由于横向排列处理交麻烦,这里采用弹性布局进行排布,但对于一下纵向排列的元素,其分布有较高的要求,一次,这里任采用弹性布局。 第二部分——数据获取与服务器搭建 本项目中最重要的是数据的获取,我们采用python爬虫获取百度热搜页面,在通过bs4的方法(它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为tiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码)找出树形结构中需要的数据,并且对数据进行处理,使其变为json数据的类型,以方便使用前端时的数据传输。 服务器可以很好的解决在前端数据传输中的问题,本项目采用python中的flask服务器。对于本项目,采用多端口传输的方式,可以有效避免单端口数据传输产生的问题。 第三部分——前后端交互 编写前端网页时,为实现动态更新的效果采用了加入JavaScript脚本语言的方式。本项目的动态内容大致可分为两大本部分:列表和图。对于列表,采用queryHotList()函数访问flask服务器,实现与服务器的通信,前端和服务器间采用的json格式传输。对于统计图,采用echarts的在线JavaScript图库,实现动态生成统计图的功能。 项目难点 使用bs4对爬取的内容筛选,定位,获取所需信息前后端的交互时,flask服务器和nginx的协调,flask服务器接口的搭建较为复杂。 项目完成情况 已完成部分 1.本项目使用了nginx服务器和flask服务器,使用时客户端先发送请求至nginx服务器,在通过flask向百度热搜的服务器发送数据请求,获得数据后通过其返回至nginx,再尤其反向代理将数据送至客户端。实现了数据的稳定链接,解决了直接访问跨域的问题。 2.客户端内使用了JavaScript脚本方式,保证了在不刷新页面下内容的即时更新,同时,可以使图表有动态的效果,可将鼠标移动至图表上,可显示出其值的大小。 3.在第五模块玫瑰图中,可通过鼠标点击图例的方式控制该项目是否展示。当鼠标放上时,该部分会略微变大。 4.此外,本项目中的所有图均可下载,重置,展示数据,也可直接切换图表种类。 未完成部分 本项目的第六模块中,可将其改为动态滚动的效果,但由于自身原因没有做到。本项目中使用的端口数过多(使用超过7个),但有些端口没有使用,造成了一定的资源浪费。 项目架构
(对每一个功能需明确给出相应的解决方案及运用技术点) 本项目共分为六个模块: 第一模块:当日的热搜内容,文字为超链接,点击可直接跳转,并且会随着百度热搜的更新而更新。 本部分先使用requests爬取百度热搜网页的html代码,再使用bs4中select的类选择器选择出热搜榜的内容和超链接,并使用flask接口为前端提供数据。 前端使用nginx反向代理获取后端提供的数据。 第二模块:当日小说榜前三名书名和热度(会随之更新) 本部分先使用requests爬取百度热搜网页的html代码,再使用bs4中select的类选择器选择出小说榜的内容和超链接以及热度,并使用flask接口“/getdata2”为前端提供数据。 前端使用nginx反向代理获取后端提供的数据,并使用JavaScript实现动态更新。 第三模块:当日小说榜的前五位的排名情况和形象展示 本部分在获取数据后,通过使用echarts的在线图库插入JavaScript柱状图图表,并实现了还原及下载。 第四模块:为本周一周的温度变化,包含最低温和最高温。 本部分在获取数据后,通过使用echarts的在线图库插入JavaScript折现图图表,并实现了与柱状图互相转化。 第五模块:为当日电影榜前6名的占比情况,可通过点击右侧的图例控制展示的项目数(控制是否展示) 本部分在获取数据后,通过使用echarts的在线图库插入JavaScript玫瑰图图表,可以通过点击图例控制项是否显示。 第六模块:当日最热电影宣传 问题及解决方案 1.本项目中使用的端口数过多(使用超过7个),但有些端口没有使用,造成了一定的资源浪费。解决方案:适当的减少端口,去除一些没有用到的接口 2.本项目的第六模块中,可将其改为动态滚动的效果,但由于自身原因没有做到。解决方案:获取多个数据,再使用延时更新位置的方法,可以实现动态效果 项目制作中出现了一些由于自身疏忽原因而出现的问题。解决方案:增强平时的练习,在练习中不断提升自己。 总结在本次爬虫实验中,我主要使用Python的第三方库requests来进行网页数据的爬取和处理。通过这次实验,我对爬虫的原理和应用有了更深刻的理解,并且学会了如何使用requests来构建一个简单的爬虫程序。 首先,我学习了爬虫的基本原理。爬虫是一种自动化程序,能够模拟浏览器行为,访问网页并提取所需的数据。它通过发送HTTP请求获取网页的HTML源代码,然后使用正则表达式或解析库来提取出需要的数据。爬虫可以帮助我们高效地从互联网上获取大量的数据,并进行进一步的分析和应用。 接着,我深入学习了requests框架的使用。 requests是一个功能强大的Python爬虫框架,其与flask提供了一套完整的爬取流程和多个扩展接口,方便我们开发和管理爬虫程序。我通过安装requests库,创建和配置了一个新的requests项目,并定义了爬取规则和数据处理方法。通过编写Spider类和Item类,我能够指定要爬取的网页链接和需要提取的数据字段,并使用beautifulsoup提供的bs4来进行数据的抓取和解析。 在实验过程中,我遇到了一些问题和挑战。例如,有些网页采取了反爬虫措施,如验证码、IP封禁等。为了解决这些问题,我学习了一些常用的反爬虫手段,如使用代理IP、设置请求头等。此外,我还学习了如何处理异步加载的数据,使用Scrapy的中间件来模拟Ajax请求,以及如何设置爬取速度和并发数,以避免对目标网站造成过大的负担。 通过这次实验,我不仅学会了如何使用requests框架进行网页数据的爬取和处理,还加深了对爬虫技术的理解。爬虫作为一种强大的数据采集工具,在各行业都有广泛的应用,能够帮助我们获取和分析大量的网络数据,从而为决策和应用提供有力支持。我相信在今后的学习和工作中,爬虫技术将会发挥越来越重要的作用。 |
【本文地址】