| Dubbo负载均衡策略之 一致性哈希 | 您所在的位置:网站首页 › 负载地址 › Dubbo负载均衡策略之 一致性哈希 |
Dubbo负载均衡策略之 一致性哈希
|
对于这样的场景,我们可以引入哈希算法。
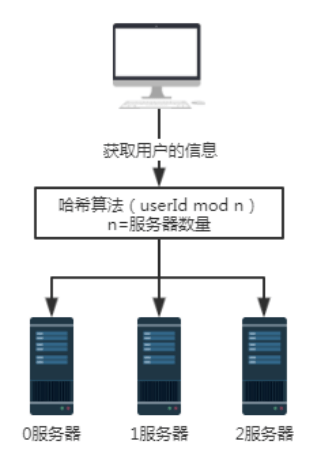
图2 引入哈希算法后的请求 还是上面的场景,但前提是每一台服务器存放用户信息时是根据某一种哈希算法存放的。所以取用户信息的时候,也按照同样的哈希算法取即可。 假设我们要查询用户号为100的用户信息,经过某个哈希算法,比如这里的userId mod n,即100 mod 3结果为1。所以用户号100的这个请求最终会被1号服务器接收并处理。 这样就解决了无效查询的问题。 但是这样的方案会带来什么问题呢? 扩容或者缩容时,会导致大量的数据迁移。最少也会影响50%的数据。
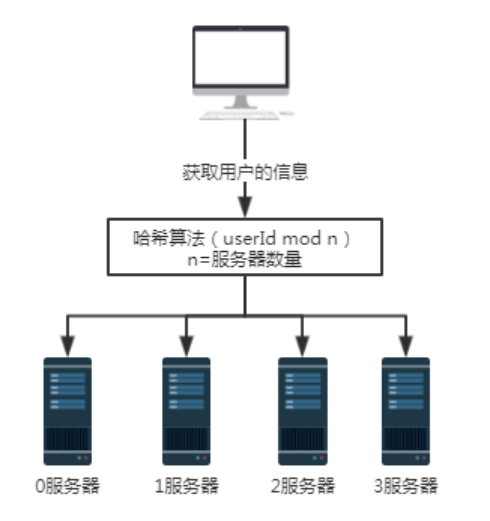
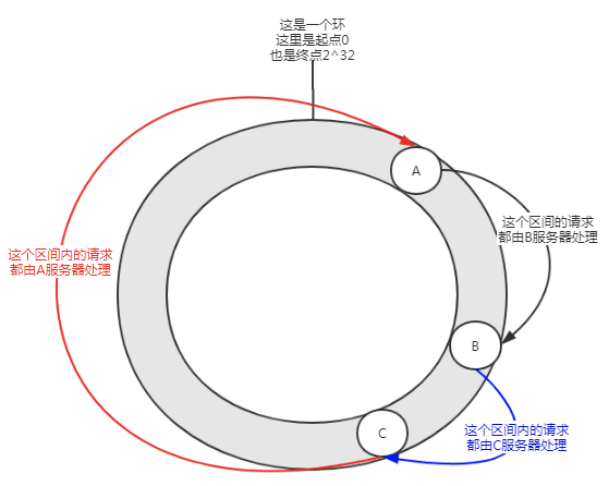
图3 增加一台服务器 为了说明问题,加入一台服务器3。服务器的数量n就从3变成了4。还是查询用户号为100的用户信息时,100 mod 4结果为0。这时,请求就被0号服务器接收了。 当服务器数量为3时,用户号为100的请求会被1号服务器处理。 当服务器数量为 4时,用户号为100的请求会被0号服务器处理。所以,当服务器数量增加或者减少时,一定会涉及到大量数据迁移的问题。 对于上述哈希算法其优点是简单易用,大多数分库分表规则就采取的这种方式。一般是提前根据数据量,预先估算好分区数。 其缺点是由于扩容或收缩节点导致节点数量变化时,节点的映射关系需要重新计算,会导致数据进行迁移。所以扩容时通常采用翻倍扩容,避免数据映射全部被打乱,导致全量迁移的情况,这样只会发生50%的数据迁移。 03 一致性哈希算法 一致性hash 算法由麻省理工学院的 Karger 及其合作者于1997年提出的,算法提出之初是用于大规模缓存系统的负载均衡。 它的工作过程是这样的,首先根据 ip 或者其他的信息为缓存节点生成一个 hash,并将这个 hash 投射到 [0, 232 - 1] 的圆环上。当有查询或写入请求时,则为缓存项的 key 生成一个 hash 值。然后查找第一个大于或等于该 hash 值的缓存节点,并到这个节点中查询或写入缓存项。如果当前节点挂了,则在下一次查询或写入缓存时,为缓存项查找另一个大于其 hash 值的缓存节点即可。大致效果如下图所示,每个缓存节点在圆环上占据一个位置。如果缓存项的 key 的 hash 值小于缓存节点 hash 值,则到该缓存节点中存储或读取缓存项。比如下面绿色点对应的缓存项将会被存储到 cache-2 节点中。由于 cache-3 挂了,原本应该存到该节点中的缓存项最终会存储到cache-4节点中。
图4一致性哈希算法 在一致性哈希算法中,不管是增加节点,还是宕机节点,受影响的区间仅仅是增加或者宕机服务器在哈希环空间中,逆时针方向遇到的第一台服务器之间的区间,其它区间不会受到影响。 但是一致性哈希也是存在问题的:
图5 数据倾斜 当节点很少的时候可能会出现这样的分布情况,A服务会承担大部分请求。这种情况就叫做数据倾斜。 那如何解决数据倾斜的问题呢? 加入虚拟节点。 首先一个服务器根据需要可以有多个虚拟节点。假设一台服务器有n个虚拟节点。那么哈希计算时,可以使用 IP+端口+编号的形式进行哈希值计算。其中的编号就是0到n的数字。由于IP+端口是一样的,所以这n个节点都是指向的同一台机器。
图6 引入虚拟节点 在没有加入虚拟节点之前,A服务器承担了绝大多数的请求。但是假设每个服务器有一个虚拟节点(A-1,B-1,C-1),经过哈希计算后落在了如上图所示的位置。那么A服务器的承担的请求就在一定程度上(图中标注了五角星的部分)分摊给了B-1、C-1虚拟节点,实际上就是分摊给了B、C服务器。 一致性哈希算法中,加入虚拟节点,可以解决数据倾斜问题。 04 一致性哈希在DUBBO 中的应用
图7 Dubbo中一致性哈希环 这里相同颜色的节点均属于同一个服务提供者,比如Invoker1-1,Invoker1-2,……, Invoker1-160。这样做的目的是通过引入虚拟节点,让 Invoker 在圆环上分散开来,避免数据倾斜问题。所谓数据倾斜是指,由于节点不够分散,导致大量请求落到了同一个节点上,而其他节点只会接收到了少量请求的情况。比如:
图8 数据倾斜问题 如上,由于Invoker-1 和 Invoker-2 在圆环上分布不均,导致系统中75%的请求都会落到 Invoker-1 上,只有 25% 的请求会落到 Invoker-2 上。解决这个问题办法是引入虚拟节点,通过虚拟节点均衡各个节点的请求量。 到这里背景知识就普及完了,接下来开始 分析源码。我们先从 ConsistentHashLoadBalance 的 doSelect 方法开始看起,如下: privatefinalConcurrentMap>; @Overrideprotected Invoker doSelect(List invokers, URL url, Invocation invocation){ String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get( 0).getUrl.getServiceKey + "."+ methodName; // 获取 invokers 原始的 hashcodeintidentityHashCode = System.identityHashCode(invokers); ConsistentHashSelector selector = (ConsistentHashSelector) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if(selector == null|| selector.identityHashCode != identityHashCode) { // 创建新的 ConsistentHashSelectorselectors.put(key, newConsistentHashSelector(invokers, methodName, identityHashCode)); selector = (ConsistentHashSelector) selectors.get(key);} // 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturnselector.select(invocation); }privatestaticfinalclassConsistentHashSelector< T> {...} } 如上,doSelect 方法主要做了一些前置工作,比如检测 invokers 列表是不是变动过,以及创建 ConsistentHashSelector。这些工作做完后,接下来开始调用 ConsistentHashSelector 的 select 方法执行负载均衡逻辑。在分析 select 方法之前,我们先来看一下一致性 hash 选择器 ConsistentHashSelector 的初始化过程,如下: // 使用 TreeMap 存储 Invoker 虚拟节点privatefinalTreeMap virtualInvokers; privatefinalintreplicaNumber; privatefinalintidentityHashCode; privatefinalint[] argumentIndex; ConsistentHashSelector(List invokers, String methodName, intidentityHashCode) { this.virtualInvokers = newTreeMap; this.identityHashCode = identityHashCode; URL url = invokers.get( 0).getUrl; // 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160); // 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0")); argumentIndex = newint[index.length]; for( inti = 0; i < index.length; i++) { argumentIndex[i] = Integer.parseInt(index[i]);}for(Invoker invoker : invokers) { String address = invoker.getUrl.getAddress;for( inti = 0; i < replicaNumber / 4; i++) { // 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i); // 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for( inth = 0; h < 4; h++) { // h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上longm = hash(digest, h); // 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}} ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。ConsistentHashLoadBalance 不 关系权重,因此使用时需要注意一下。 在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点hash 值,并将虚拟节点存储到 TreeMap 中。到此,ConsistentHashSelector 初始化工作就完成了。接下来,我们来看看 select 方法的逻辑。 privateInvoker selectForKey( longhash ) { // 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry entry = virtualInvokers.tailMap(hash, true).firstEntry; // 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif(entry == null) { entry = virtualInvokers.firstEntry;} // 返回 Invokerreturnentry.getValue; } 如上,选择的过程相对比较简单了。首先是对参数进行md5 以及 hash 运算,得到一个 hash 值。然后再拿这个值到 TreeMap 中查找目标 Invoker 即可。 到此关于ConsistentHashLoadBalance 就分析完了。 在阅读ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。 05 应用场景 DNS负载均衡 最早的负载均衡技术 是通过 DNS来实现的,在DNS中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。 DNS负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。 代理服务器负载均衡 使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。 然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。 地址转换网关负载均衡 支持负载均衡的地址转换网关,可以将一个外部IP地址映射为多个内部IP地址,对每次TCP连接请求动态使用其中一个内部地址,达到负载均衡的目的。 协议内部支持负载均衡 除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP协议中的重定向能力等,HTTP运行于TCP连接的最高层。 NAT负载均衡 NAT(Network Address Translation网络地址转换)简单地说就是将一个IP地址转换为另一个IP地址,一般用于未经注册的内部地址与合法的、已获注册的Internet IP地址间进行转换。 适用于解决Internet IP地址紧张、不想让网络外部知道内部网络结构等的场合下。 反向代理负载均衡 普通代理方式是代理内部网络用户访问 internet上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到internet上服务器的连接请求发送给代理服务器处理。 反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。 反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。 混合型负载均衡 在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。 将这种方式称之为混合型负载均衡。 此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。END 微软Edge正在偷窥你 这里有最新开源资讯、软件更新、技术干货等内容 点这里 ↓↓↓ 记得 关注✔ 标星⭐ 哦返回搜狐,查看更多 |




【本文地址】