| 按键精灵 识别html,【院刊】 | 您所在的位置:网站首页 › 读取网页数据的快捷键 › 按键精灵 识别html,【院刊】 |
按键精灵 识别html,【院刊】
|
抓取网页指定内容(资料),获取网页里的图片最近有遇到同学反馈,网页里的那些没有特征值的文本元素不知道怎么获取。以及,不知道怎么获取保存网页里出现的图片。
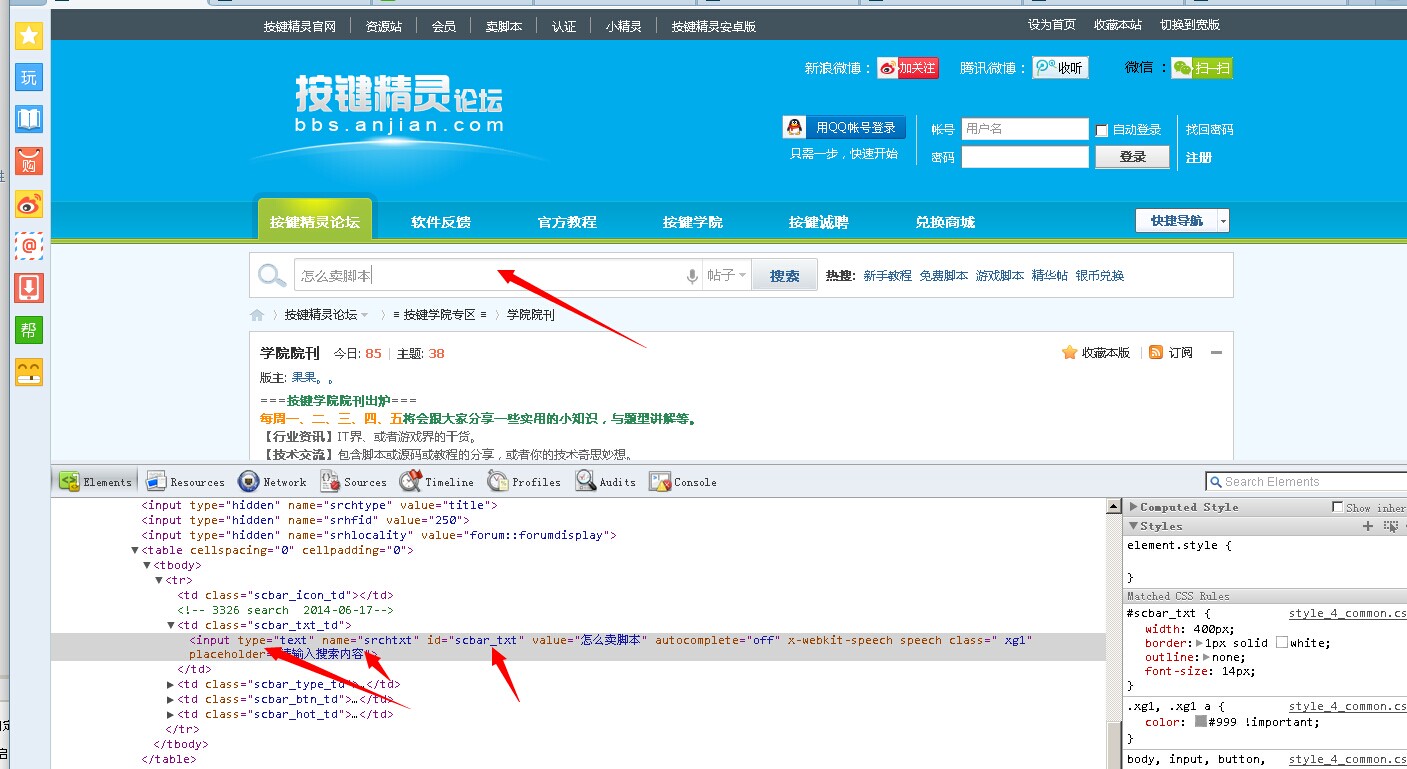
获取网页指定文字: 目前按键支持的元素特征值有这些: frame(框架) 、id(唯一标识) 、tag(标签) 、type(类型)、txt(文本) 、value(特征) 、index(索引) 、name(名字) 拥有这些特征值的元素才能直接使用HtmlGet命令来获取元素文本信息。 命令名称:HtmlGet获取网页元素的信息 命令功能:获取网页元素指定属性的信息 命令参数:参数1:字符串型,网页元素属性类型:text、html、outerHtml、value、src、href、offset 参数2:字符串型,网页元素特征字符串 例如下面的例子,按键精灵论坛搜索框,它有type、name、id这三个特征值。
2016/9/8 11:02:10 我们取它id特征值带入到HtmlGet 命令来查看下结果: Call Plugin.Web.Bind("WQM.exe") Call Plugin.Web.go("http://bbs.anjian.com/forum-250-1.html") //要提取信息的网站 Txt=Plugin.Web.HtmlGet("value","id:scbar_txt") TracePrint Txt复制代码
2016/9/8 11:02:10 成功获取到了搜索框的value值。 我们现在想要取下面红色区域块的帖子标题,想要把一个页面中的这些帖子名称都取出来。 该怎么办?
|


 1.jpg(217.62 K)
1.jpg(217.62 K)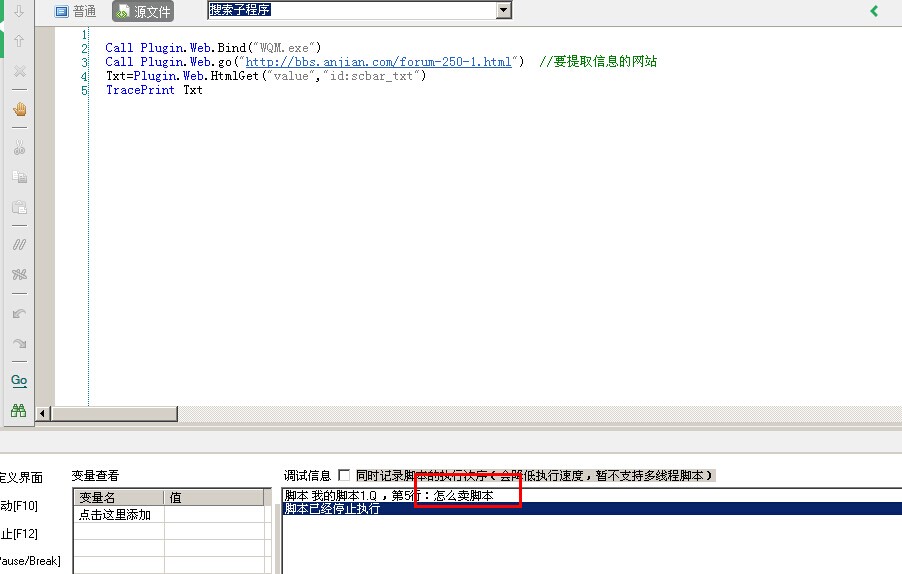
【本文地址】
公司简介
联系我们
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |