|
前言:2023-10-23日,语雀挂了一会,导致我没法写文档,这让我意识到文档全部放在云服务器上是不靠谱的,还需要进行本地备份,所以有了本篇文章内容。重要提示:代码没有经过严谨测试,但我本人用起来没问题,我就不管了,不想浪费太多时间在这个上面,导出的文件会按每个知识库一个目录进行储存
1、首先导入apache httpclient依赖
org.apache.httpcomponents
httpclient
4.5.10
2、获取你的authToken和csrfToken
首先进入你任意一个知识库,按下F12打开开发者工具,然后点击到网络,输入"yuque",然后清空日志,点击任意一篇文章,然后语雀会发送一个请求到语雀的服务器来获取你这篇文章的评论,这个请求中中就携带了你的authToken和csrfToken
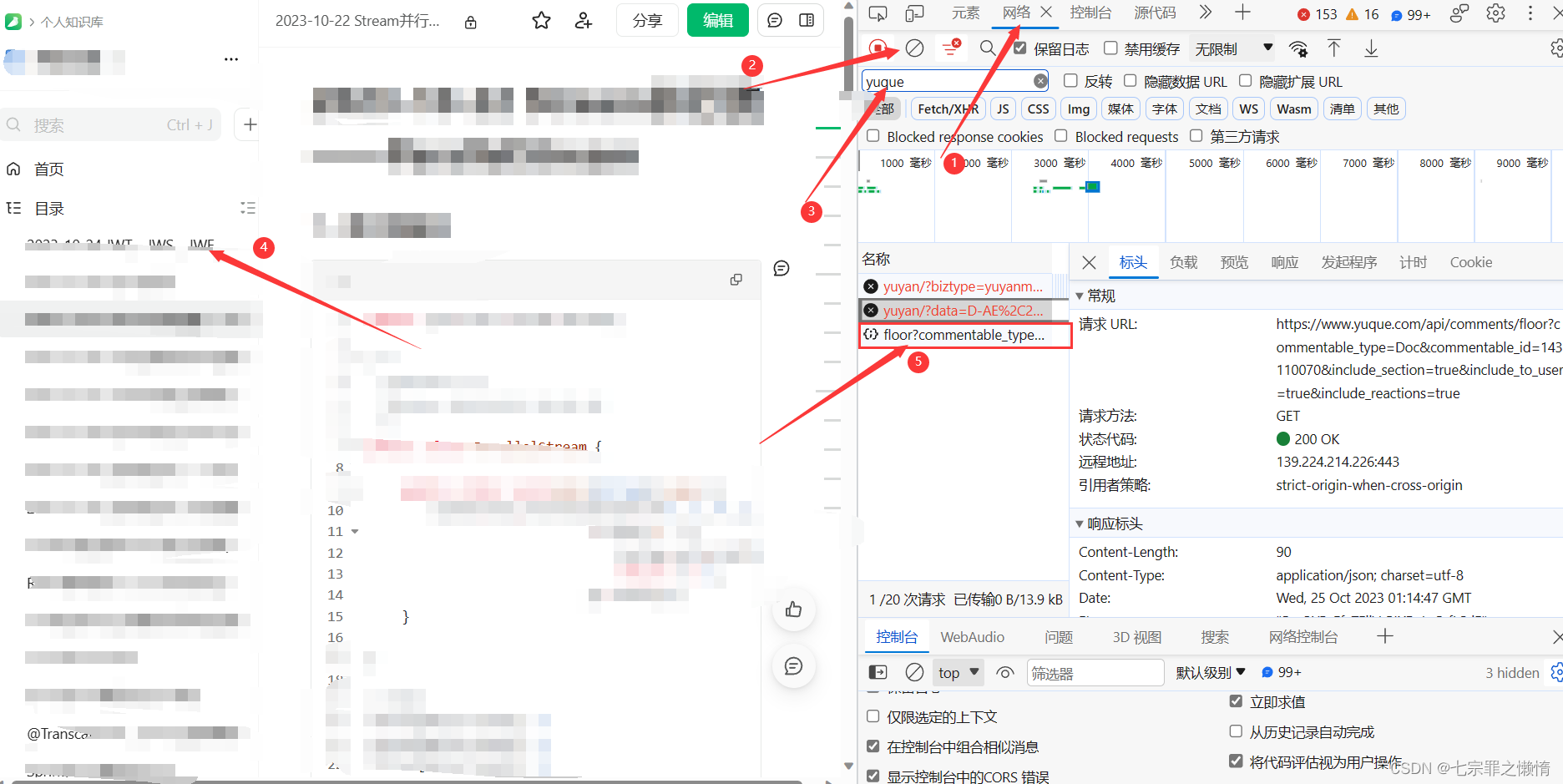
然后在右边的标头中一直下滑,找到请求标头,即可看到authToken和csrfToken,分别复制到下面的代码中进行替换即可

import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.clienthods.HttpGet;
import org.apache.http.clienthods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.json.JSONArray;
import org.json.JSONObject;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLDecoder;
public class YuqueAPIClient {
static String authToken = "待替换";
static String csrfToken = "待替换";
public static void main(String[] args) {
String baseURL = "https://www.yuque.com/api";
String personalBooksURL = baseURL + "/mine/personal_books";
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
// Step 1: 获取所有知识库的Id
HttpGet personalBooksRequest = new HttpGet(personalBooksURL);
personalBooksRequest.setHeader("Cookie", authToken);
personalBooksRequest.setHeader("X-Csrf-Token", csrfToken);
HttpResponse personalBooksResponse = httpClient.execute(personalBooksRequest);
HttpEntity personalBooksEntity = personalBooksResponse.getEntity();
String personalBooksResponseString = EntityUtils.toString(personalBooksEntity);
JSONObject personalBooksData = new JSONObject(personalBooksResponseString);
JSONArray personalBooks = personalBooksData.getJSONArray("data");
// 1.1、遍历知识库
for (int i = 0; i < personalBooks.length(); i++) {
JSONObject book = personalBooks.getJSONObject(i);
String bookId = String.valueOf(book.get("id"));
String bookName = (String) book.get("name");
// Step 2: 获取知识库下的所有文章
String bookURL = baseURL + "/docs/?book_id=" + bookId;
HttpGet docRequest = new HttpGet(bookURL);
docRequest.setHeader("Cookie", authToken);
docRequest.setHeader("X-Csrf-Token", csrfToken);
HttpResponse docResponse = httpClient.execute(docRequest);
HttpEntity docEntity = docResponse.getEntity();
String docResponseString = EntityUtils.toString(docEntity);
JSONObject docData = new JSONObject(docResponseString);
JSONArray docs = docData.getJSONArray("data");
// Step 3: 遍历知识库下的有所文章
for (int j = 0; j < docs.length(); j++) {
JSONObject docEntry = docs.getJSONObject(j);
String docId = String.valueOf(docEntry.get("id"));
String exportURL = baseURL + "/docs/" + docId + "/export";
HttpPost exportRequest = new HttpPost(exportURL);
exportRequest.setHeader("Cookie", authToken);
exportRequest.setHeader("X-Csrf-Token", csrfToken);
JSONObject jsonObject = new JSONObject();
jsonObject.put("type", "markdown");
jsonObject.put("force", 0);
// jsonObject.put("options", "{\"latexType\": 2,\"enableAnchor\": 0,\"enableBreak\": 0}");
// latexType:1、导出 LaTeX 公式图片 2、导出 LaTeX 公式为 Markdown 语法
// enableAnchor:导出保持语雀的锚点
// enableBreak:导出保持语雀的换行
jsonObject.put("options", "{\"latexType\":2}");
StringEntity entity = new StringEntity(jsonObject.toString());
entity.setContentType("application/json");
exportRequest.setEntity(entity);
HttpResponse exportResponse = httpClient.execute(exportRequest);
HttpEntity exportEntity = exportResponse.getEntity();
String exportResponseString = EntityUtils.toString(exportEntity);
JSONObject exportData = new JSONObject(exportResponseString).getJSONObject("data");
String downloadURL = (String) exportData.get("url");
try {
// Step 3.1:保存文章到本地
saveFileFromURL(downloadURL, bookName);
}
catch (Exception e) {
e.printStackTrace();
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void saveFileFromURL(String fileURL, String bookName) {
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet httpGet = new HttpGet(fileURL);
httpGet.setHeader("Cookie", authToken);
httpGet.setHeader("X-Csrf-Token", csrfToken);
HttpResponse response = httpClient.execute(httpGet);
HttpEntity entity = response.getEntity();
String fileName;
if (response.getHeaders("Content-Disposition")[0].getElements()[0].getParameters().length == 2) {
String file = response.getHeaders("Content-Disposition")[0].getElements()[0].getParameters()[1].getValue();
fileName = URLDecoder.decode(file);
fileName = fileName.substring(fileName.lastIndexOf("'"));
}
else
fileName = response.getHeaders("Content-Disposition")[0].getElements()[0].getParameters()[0].getValue();
if (entity != null) {
try (InputStream inputStream = entity.getContent();
FileOutputStream outputStream = new FileOutputStream("./files/" + bookName + "/" + fileName)) {
byte[] buffer = new byte[1024];
int n;
while ((n = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, n);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
|