| 语言 | 您所在的位置:网站首页 › 语言起源假说声音假说 › 语言 |
语言
|
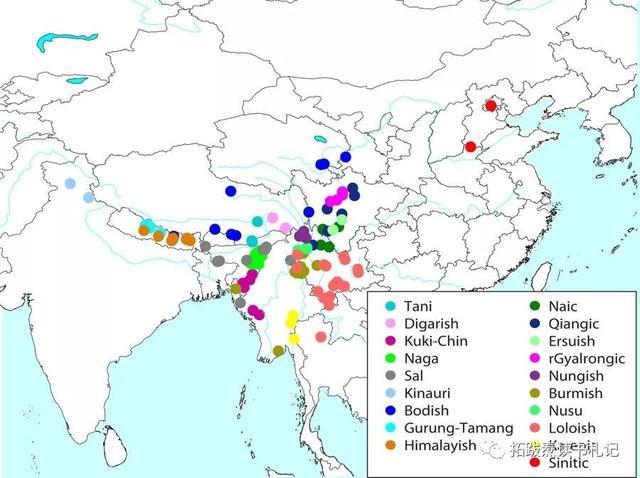
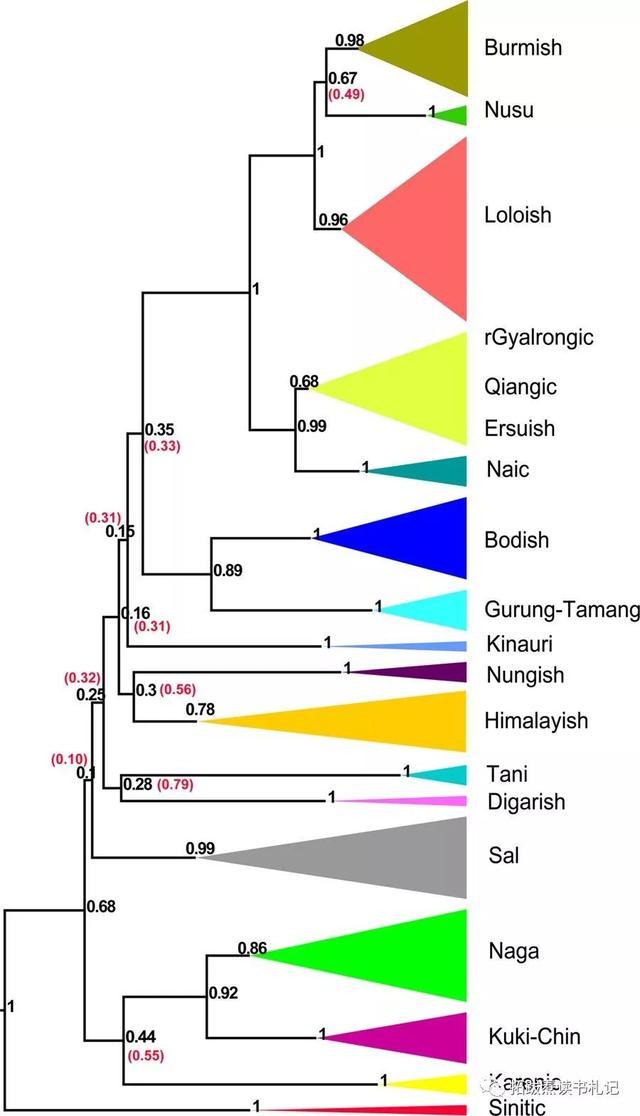
本文转自:拓跋焘读书札记 转自:语标 翻译者按: 2019年4月25日,复旦大学金力团队在《自然》上发表了探讨汉藏语言起源相关问题的文章(综合报道),并引发学界热议(这里)。发布后,拓跋(山东师范大学语言学及应用语言学在读研究生张涛)第一时间看了这篇文章,并决定译成汉语,以飨同学。(感谢董庆进一同翻译,也感谢百度翻译软件作为参考) 文章包括两部分,一是文本(下文),多阐述总结性的成果;二是若干附件压缩包,主要是原始材料、数据的整理。一般读者读文本即可,想更深入理解文章的读者建议去下载原始材料。原文中的图表在本文中仅附少数,其余请点击“原文”自行到原网站下载观看。 汉藏语起源于新石器晚期中国北方的谱系发生学证据 摘要:语言起源和分化的研究对于理解人类及其文化的历史具有重要意义。汉藏语系是世界上仅次于印欧语系的第二大语系,关于其谱系发生和原始分化的时间深度一直存在争论。本文对汉藏语系起源的两个相互竞争的假说——“北方起源假说”和“西南起源假说”进行了贝叶斯系统发生分析。北方起源假说指出,汉藏语言的最初扩散发生在距今约4000-6000年前(以公元1950年为基准),发生在中国北方黄河流域,并且这种扩散与仰韶和(或)马家窑新石器文化的发展有关。西南起源假说指出,汉藏语言的早期扩散发生在9000年前的中国四川西南部地区或印度东北部地区,那里如今存在着非常多样的藏缅语言。 我们对109种语言的949个词根义进行了贝叶斯谱系发生分析,估算出汉藏语言的分化时间深度约为4200-7800年,平均值约为5900年,这与北方起源假说相一致。此外,谱系发生分析支持了汉语族和藏缅语之间的二分法。我们的研究结果与考古记录相吻合,与中国农业扩张和语言传播假说相吻合。我们的研究结果为进一步跨学科研究东亚史前人类活动提供了语言基础。 正文 史前人类的知识建立在三个学科上:考古学、遗传学和语言学。遗传学和语言学之间的相似性反映了历史人口活动的可比的潜在过程。因为语言承载着文化信息,语言的进化提供了对史前人类文化的洞察。 汉藏语系是世界第二大语系,由400多种语言和方言组成,约15亿母语者共同使用这些语言和方言。汉藏语系在地理上分布于东亚、东南亚半岛和南亚北部,包括有良好记录的语言,如汉语、缅甸语和藏语。了解汉藏语系的历史,将有助于我们深入研究其成员语言之间的关系,以及它们与阿尔泰语系、南亚语系、苗瑶语系、侗台语系和南岛语系的相互作用。此外,这一知识对于解决整个欧亚大陆东部人口迁移的来源、形成和历史问题至关重要。 尽管汉藏语言的语言学研究最近蓬勃发展,但重建汉藏语系早期历史的三个基本问题仍未解决。第一个问题涉及汉藏语言的基本分类,特别是汉藏语言的地位。汉藏语系的基本分类有三种假设,其中最为广泛接受的一种假设提出了汉语族和藏缅语族之间的二分法:即汉语族(主要是汉语及其方言)被认为是汉藏语系的一个主要分支,所有的藏缅语族都被认为是汉藏语系的一个单系群体。一个对立的假设认为,汉语族是汉藏语系主要分支的一个次分支。第三个假设认为,汉藏语系底下分出若干个平行的分支(并且汉语族是这些分支之一)。除这些假设外,还有“落叶”模型,它认为汉藏语系的主要亚群之间没有明显的内部关系。 在汉藏语系分类争议的基础之上,其他有争议的问题包括汉藏语言分化和扩散的时间和起源地。这些争议可分为两个主要假设:北部起源和西南起源假说(表1)。北方起源假说认为,黄河上游和(或)中游地区的人讲汉藏语系祖先的语言,他们在距今4000-6000年间分成了两部分:一部分向西迁移到西藏,然后向南迁移到缅甸(成为说藏缅语的当代人口的主要祖先),而另一部分(说汉语的祖先)向东和南移动,最终成为汉人。大多数历史语言学家倾向于这种假设,并认为汉藏语言的扩散与新石器时代仰韶文化(约7000-5000年前)和(或)马家窑文化(约5500-4000年前)的发展有着合理的联系。 相比之下,西南起源假说认为,汉藏语系的扩散发生在约距今9000-10000年的东亚西南地区。西南起源假说主要有两种形式(见表1),这里称为假说II和假说III。假说II认为,讲汉藏语的人口最早起源于13500年前的四川省西南部,并在大约距今9000年前分为两组:一组人进入印度东北部,另一组向北进入黄河流域;后者被认为是当代中国人和西藏人民的祖先。假说III认为汉藏语言起源于大约9000年前的印度东北部,最早讲汉藏语言的人从事游牧畜牧活动而非农业。 有关汉藏语言起源地的争论交织着谱系发生的不确定性和对语言何时分化的巨大分歧。所有讨论过汉藏语言与东亚农业文明之间关系的语言学家都把仰韶文化、马家窑文化和汉藏语系联系了起来,因为中国周朝先民和今天说藏缅语的一些人在文化考古上具有清晰的联系。问题在于,和仰韶和马家窑新石器文化有关的地理区域是否就是汉藏语系主要的播迁之地。明确的语言谱系重建和可靠的语言分化估算时间是推断汉藏语言发源地的必要条件。在历史语言学中,运用丰富的当代材料和历史文献的比较方法是一种广泛应用于建立语言关系的方法。语言年代学是语言比较方法的一个扩展,它使用词汇数据来估计语言分化的年代。然而,语言年代学有相当大的局限性(例如它假定语言进化的速率是恒定的),并且不考虑语言接触、环境变化或不同种类的词之间不同的替换速率、语言进化不同的速率等,但这些问题也经常出现在汉藏语言研究中。例如,在东亚,汉藏语系与周边非汉藏语系,如苗瑶和侗台之间的语言接触很普遍。此外,缺乏对汉藏语言完整的历史记录和全面的语言调查,这些都对语言比较方法造成了挑战。然而,进化生物学的贝叶斯谱系发生方法的最新进展提供了绕过这些局限性的替代机会。这些方法允许灵活的进化模型,并且是推断全球语言家族进化速度和变化模式的有力工具。 为了研究“北方起源”和“西南起源”假说,我们对分布在中国、东南亚(例如缅甸)和南亚(例如印度、尼泊尔和不丹)的109种汉藏语系的949个二进制编码词根义进行了贝叶斯谱系发生分析(图1,扩展数据图1)。通过匹配Swadesh 100单词表中的词义,根据多种选择标准(补充信息,第1.1节)手动识别和整理词根含义。利用已知历史事件的多次时间校准来估算汉藏语言的分化时间(补充表2),并比较了几种模型组合(扩展数据图2)。与以前的研究不同,我们在没有任何祖先限制或单系限制的前提下进行分析,以避免在系统发育重建过程中出现人为偏差。 贝叶斯谱系发生分析的结果显示,汉语族和藏缅语之间存在二分法,其中传统分类的藏缅语族被确认为一个单系,后验值为0.68(图1,扩展数据图3)。分析还评估了汉藏语系几个有争议的亚组的可靠性(补充资料,第2.3节,扩展数据图4)。汉藏语言最初分化的平均时间估计(距今5871年)(图1,扩展数据图5)发生在仰韶新石器文化时期,而最初的藏缅语分化时间(距今4665年)(图1,扩展数据图6)估计发生在源于仰韶文化的马家窑文化中期。因此,谱系发生和分化时间与北方起源假说相一致,也就是说,汉藏语言的最初分化可能与中国北方的这两种新石器文化有关(图2a,补充资料,第2.4节)。所估藏缅语分化的时间与Y染色体数据的遗传证据也是一致。 考古证据表明,汉藏语言分化扩散与新石器时代两种文化发展之间的联系可能归因于人口的快速增长和农业的普及。黄河流域考古遗址和持续的森林砍伐数量迅速增加,表明两次快速的人口增长开始于大约距今6000年前,并在距今5000-4500年加剧(图2b,c)。这一时间线与本研究中汉藏语和藏缅语分家的估计时间一致。此外,汉藏语传播可能与距今6000年后谷粟农业的传播有关,这与“农业和语言传播”假说相一致。一系列考古证据,如建筑形式、陶器的图案和形状,也显示出沿着藏-彝走廊向南扩散到川西和云南西部省份的连续波;这种扩散可以追溯到仰韶、马家窑和齐家文化(新石器时代到青铜时代期间马家窑文化的延续,大约距今4300-3500年)。特别是,距今5000年后,谷粟农业的传播主要发生在中国北方(特别是黄河流域)(补充资料,第2.5节),并沿着青藏高原边缘向西部和南部扩散。此外,根据之前的工作,我们对汉藏语进行了起源地推测(扩展数据图7)。不过对于汉藏语言,起源地推测的前提条件并不满足(补充资料,第2.7节)。 虽然我们采用谱系树模型来证明汉藏语系的血统,但我们并不认为汉藏语系的文化史确实是树形的。人口迁移和汉藏语使用者之间的互动是复杂的,并在很长一段时间内发生。因此,汉藏语言之间的大量语言接触可能发生在这些语言多样化的早期阶段,并可能一直持续到现在。这些接触以前已知发生在汉藏语言之间,以及与周围的南岛语、侗台语和苗瑶语之间(补充资料,第2.5、2.6节)。不幸的是,我们还不能为识别这些影响提供具体的数据,因此我们不能重建汉藏语言和其他语言家族之间的显性遗传关系。许多汉藏语言的描述仍然很差,这使得在历史语言学中进行明确的比较变得困难。因此,对汉藏语言演变的研究尚处于起步阶段,需要更多的跨学科数据。为了明确地展示汉藏语言的演变,我们需要全面的考古调查和从古代DNA研究中获得足够的证据。 方法 没有使用统计方法来预先确定样本量。在实验和结果评估过程中,实验不是随机的,研究者也没有对分配视而不见。 词根意义数据 根据一系列选择标准(见补充资料,第1.1节),我们选择了109个汉藏语言样本,这些样本在低级亚组中得到了很好的描写。109种语言包括108种当代语言和一种古代语言(上古汉语),它们的语言分支根据语言文字和民族语(补充表1)命名。根据Swadesh 100单词表中的项目,我们在多种严格的选择标准(补充信息,第1.1节)下,从STEDT数据库中整理了109种汉藏语言的949个词根-含义。这些根含义被编码为离散二进制字符(补充表1;作为补充数据以nexus格式提供(文件名'109sinotibetanlanguage_swadesh100.nex'))。 谱系发生重建和分化时间估计 我们使用Beast2软件(v.2.4.8)33和babel包建立了汉藏语言谱系树,并估计了树根的时间深度。babel包用于执行语言分析(https://github.com/rbouckaert/babel)。Beast中不需要任何例外组;相反,Beast将对根位置以及树中的其余节点进行采样。我们评估了两个词根-意义模型(连续时间马尔可夫链(CTMC)和协变)、时钟模型(严格和宽松的对数正态时钟)和伽马率异质性的六个组合,其中一个或四个比率类别属于CTMC模型(补充信息,第1.2节)。因为在我们的分析中并不是所有的语言样本都是当代的,所以我们选择合并贝叶斯天际线模型作为树优先模型。 为了估计汉藏语系的根年龄,我们根据已知的人类学和人口统计学证据以及历史事件(补充表2,补充数据(文件名'binarycovation.releadclock.xml')对谱系树进行了校正。这些校准用概率分布表示。根据之前工作中校准的设置,我们选择了两种分布:涉及估计误差系数均匀分布的可能日期的情况下的正态分布,以及评估发散时间潜在范围的均匀分布。我们的目标是获得推断的汉藏语言的谱系。因此,我们并没有预先设置任何单系约束,即使它们是经过良好证明的语言分支。 利用时钟模型、站点模型和速率异质性的六种组合分析词根义数据集。我们对这6种组合进行了5千万代的测试,每5000代进行一次采样,结果得到了1万棵树的样本。前10%的迭代被视为老化,并被丢弃。示踪剂(v.1.6)35用于检查自相关和收敛状态,并通过log10贝叶斯因子(补充信息,第2.1节,补充表3)测试最佳拟合模型组合。使用Beast v.2.4.8中的TreeanNotator包生成最大clade可信度树。 语言分化的速度估计和考古遗址数量的变化 为了估计语言分化的速度,我们在语言系统中应用了一个滑动窗口,从7000年前到现在。在每个窗口中,我们计算内部节点的数量。每个内部节点的平均高度是从给定的汉藏语言系统中获得的(参见补充数据中的高度数据(文件名'109sino tibetan language.mcc.tree')。推拉窗的长度设定为500年,移动步距设定为50年。利用这个估计,我们得到了整个系统发育的节点数曲线。在Matlab 2015b中,使用作为平滑函数的局部加权散点图平滑算法36对曲线进行平滑处理,其中参数“平滑跨度”设置为0.1。 同样,我们采用同样的方法来计算考古遗址数量的变化,如图2b、c所示。具体来说,我们调查了中国西北部(包括甘肃、青海、宁夏和陕西)和西南部(包括四川、云南和西藏自治区)两个地理区域的考古遗址数量。收集的考古遗址的数据来自先前的出版物(补充信息,第1.5节)。在距今7000到2500年(移动步骤设置为1)之间的每个时间点,我们计算了覆盖时间点的时间范围内的站点数量(补充数据(文件名“Matlab codes for estimation of Sino-Tibetan evolutionary tempo.zip”)。 (译者:张涛 董庆进) 特别声明:以上文章内容仅代表作者本人观点,不代表新浪网观点或立场。如有关于作品内容、版权或其它问题请于作品发表后的30日内与新浪网联系。 |
【本文地址】