| 训练集和测试集的分布差距太大有好的处理方法吗? | 您所在的位置:网站首页 › 训练组与测试组的关系 › 训练集和测试集的分布差距太大有好的处理方法吗? |
训练集和测试集的分布差距太大有好的处理方法吗?
|
机器学习常见步骤 1.对数据集进行划分,分为训练集和测试集两部分; 2.对模型在测试集上面的泛化性能进行度量; 3.基于测试集上面的泛化性能,依据假设检验来推广到全部数据集上面的泛化性能。 三种数据集的含义在进行机器学习算法之前,通常需要将数据集划分,通常分为训练集和测试集,部分还有验证集。首先介绍这三种数据集的含义: **训练集(Training Set):**帮助我们训练模型,即通过训练集的数据让我们确定拟合曲线的参数。 **验证集(Validation Set):**用来做模型选择(model selection),即做模型的最终优化及确定的,用来辅助我们的模型的构建,可选; 测试集(Test Set): 为了测试已经训练好的模型的精确度。因为在训练模型的时候,参数全是根据现有训练集里的数据进行修正、拟合,有可能会出现过拟合的情况,即这个参数仅对训练集里的数据拟合比较准确,如果出现一个新数据需要利用模型预测结果,准确率可能就会很差。 所以测试集的作用是为了对学习器的泛化误差进行评估,即进行实验测试以判别学习器对新样本的判别能力,同时以测试集的的测试误差”作为泛化误差的近似。因此在分配训练集和测试集的时候,如果测试集的数据越小,对模型的泛化误差的估计将会越不准确。所以需要在划分数据集的时候进行权衡。 测试集的比例 训练集数据的数量一般占2/3到4/5。在实际应用中,基于整个数据集数据的大小,训练集数据和测试集数据的划分比例可以是6:4、7:3或8:2。对于庞大的数据可以使用9:1,甚至是99:1。具体根据测试集的划分方法有所不同。 常见的划分方法留出法 直接将数据集D划分为两个互斥的的集合,其中一个集合作为训练集S,另一个作为测试集T,即D=S∪T, S ∩ T = 空集。在S上训练出模型后,用T来评估其误差。 需要注意的是,训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入的额外的偏差而对最终结果产生影响。例如在分类任务中,至少要保持样本的类别比例相似。从”采样”的角度来看待数据集的划分过程,则保留类别比例的采样方式通常称为“分层采样”。例如从1000个数据里,分层采样获得70%样本的训练集S和30%样本的测试集T,若D包含500个正例,500个反例,则分层采样得到的S应包含350个正例,350个反例,T应包含150个正例,150个反例;若S、T中样本比例差别很大,则最终拟合的误差将会变大。 一般,在用留出法划分集合的时候,会通过若干次随机划分、重复实验评估后取平均值作为留出法的评估结果,减少误差。留出法还有一个问题就是,到底我们训练集和测试集应该按照什么比例来划分呢?如果我们训练集的比例比较大,可能会导致训练出的模型更接近于用D训练出的模型,同时T较小,评价结果又不够准确;若T的比例比较大,则有可能导致评估的模型与之前有较大的差别,从而降低了评估的保真性。这个问题没有完美的解决方案,常见的做法是将大约2/3~4/5的样本用于训练。 交叉验证法 将数据集D划分为k个大小相似的互斥子集,即D=D1∪D2∪…∪Dk,Di ∩ Dj = 空集(i ≠j) 每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值。 交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为了强调这一点,通常把交叉验证法称为”k折交叉验证”(k-fold cross validation),k通常取10—10折交叉验证。 交叉验证的好处就是从有限的数据中尽可能挖掘多的信息,从各种角度去学习我们现有的有限的数据,避免出现局部的极值。在这个过程中无论是训练样本还是测试样本都得到了尽可能多的学习。 交叉验证法的缺点就是,当数据集比较大时,训练模型的开销较大。 自助法 给定包含m个样本的数据集D,我们对它进行采样产生数据集D’:每次从D中挑选一个样本,将其放入D’,然后再将该样本放回初始数据集D中;这个过程重复执行m次后,我们就得到了包含m个样本的数据集D’ 即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样集D′里。于是 ,实际评估的模型与期望评估的模型都是使用m个样本,而我们仍有数据总量约1/3的没在训练集出现过的样本用于测试。 自助法在数据集较小、难以有效划分训练/测试集时比较有用。然而自助法产生的测试集改变了初始数据集的分布,这会引入误差。 因此在数据集比较大时,采用留出法和交叉验证法较好。 神经网络在网络结构确定的情况下,有两部分影响模型最终的性能,一是普通参数(比如权重w和偏置b),另一个是超参数(例如学习率,网络层数)。普通参数我们在训练集上进行训练,超参数我们一般人工指定(比较不同超参数的模型在验证集上的性能)。那为什么我们不像普通参数一样在训练集上训练超参数呢?(花书给出了解答)一是超参数一般难以优化(无法像普通参数一样通过梯度下降的方式进行优化)。二是超参数很多时候不适合在训练集上进行训练,例如:如果在训练集上训练能控制模型容量的超参数,这些超参数总会被训练成使得模型容量最大的参数(因为模型容量越大,训练误差越小),所以训练集上训练超参数的结果就是模型绝对过拟合。 正因为超参数无法在训练集上进行训练,因此我们单独设立了一个验证集,用于选择(人工训练)最优的超参数。因为验证集是用于选择超参数的,因此验证集和训练集是独立不重叠的。 测试集是用于在完成神经网络训练过程后,为了客观评价模型在其未见过(未曾影响普通参数和超参数选择)的数据上的性能,因此测试与验证集和训练集之间也是独立不重叠的,而且测试集不能提出对参数或者超参数的修改意见,只能作为评价网络性能的一个指标。 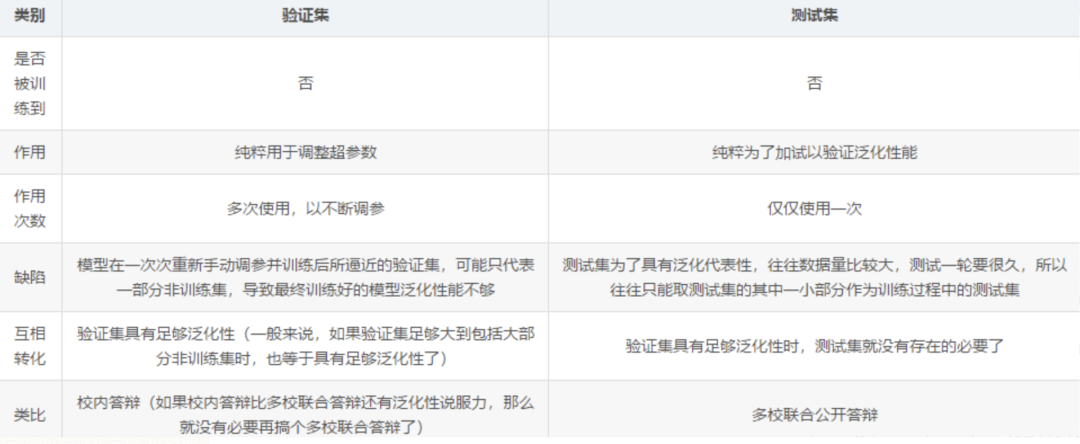 从训练集中划分出一部分作为验证集,该部分不用于训练,作为评价模型generalization error,而训练集与验证集之间的误差作为data mismatch error,表示数据分布不同引起的误差。 这种划分方式有利于保证:数据具有相同的分布 如果训练集和测试集的数据分布可能不相同,那么必定会导致一个问题,模型在训练集上的表现会非常的好,而在测试集上表现可能不会那么理想。 通过训练数据来训练模型,就是希望模型能够从训练集中学习到数据的分布,如果训练集和测试集数据不在同一个分布中,那么模型在测试集上的表现肯定是不会理想的。 训练集高分,测试集预测提交后发现分数很低,为什么?有可能是训练集和测试集分布不一致,导致模型过拟合训练集,个人很不喜欢碰到这种线下不错但线上抖动过大的比赛,有种让你感觉好像在“碰运气”,看谁“碰”对了测试集的分布。但实际是有方法可循的,而不是说纯碰运气。本文我将从“训练/测试集分布不一致问题”的发生原因讲起,然后罗列判断该问题的方法和可能的解决手段。  一、发生原因 训练集和测试集分布不一致也被称作数据集偏移(Dataset Shift)。西班牙格拉纳达大学Francisco Herrera教授在他PPT[1]里提到数据集偏移有三种类型: 协变量偏移(Covariate Shift): 独立变量的偏移,指训练集和测试集的输入服从不同分布,但背后是服从同一个函数关系,如图1所示。 先验概率偏移(Prior Probability Shift): 目标变量的偏移。概念偏移(Concept Shift): 独立变量和目标变量之间关系的偏移。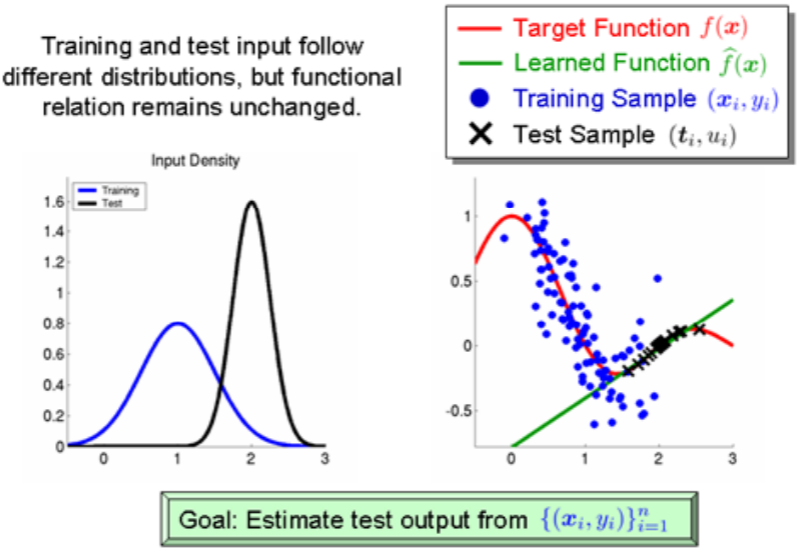 图1:协变量偏移 最常见的有两种原因[1]: 样本选择偏差(Sample Selection Bias): 训练集是通过有偏方法得到的,例如非均匀选择(Non-uniform Selection),导致训练集无法很好表征的真实样本空间。 环境不平稳(Non-stationary Environments): 当训练集数据的采集环境跟测试集不一致时会出现该问题,一般是由于时间或空间的改变引起的。在分类任务上,有时候官方随机划分数据集,没有考虑类别平衡问题,例如: 训练集类别A数据量远多于类别B,而测试集相反,这类样本选择偏差问题会导致训练好的模型在测试集上鲁棒性很差,因为训练集没有很好覆盖整个样本空间。此外,除了目标变量,输入特征也可能出现样本选择偏差问题,比如要预测泰坦尼克号乘客存活率,而训练集输入特征里“性别”下更多是男性,而测试集里“性别”更多是女性,这样也会导致模型在测试集上表现差。 样本选择偏差也有些特殊的例子,之前我参加阿里天池2021“AI Earth”人工智能创新挑战赛[2],官方提供两类数据集作为训练集,分别是CMIP模拟数据和SODA真实数据,然后测试集又是SODA真实数据,CMIP模拟数据是通过系列气象模型仿真模拟得到的,即有偏方法,但选手都会选择将模拟数据加入训练,因为训练集真实数据太少了,可模拟数据的加入也无可避免的引入了样本选择偏差。 聊完样本选择偏移,我们聊下环境不平稳带来的数据偏移,我想最常见是在时序比赛里了吧,用历史时序数据预测未来时序,未来突发事件很可能带来时序的不稳定表现,这便带来了分布差异。环境因素不仅限于时间和空间,还有数据采集设备、标注人员等。 二、判断方法  1. KDE (核密度估计)分布图 当我们一想到要对比训练集和测试集的分布,便是画概率密度函数直方图,但直方图看分布有两点缺陷: 受bin宽度影响大和不平滑,因此多数人会偏向于使用核密度估计图(Kernel Density Estimation, KDE),KDE是非参数检验,用于估计分布未知的密度函数,相比于直方图,它受bin影响更小,绘图呈现更平滑,易于对比数据分布。我研究生的有一门课的小作业有要去对比直方图和KDE图,相信这个能帮助大家更直观了解到它们的差异: 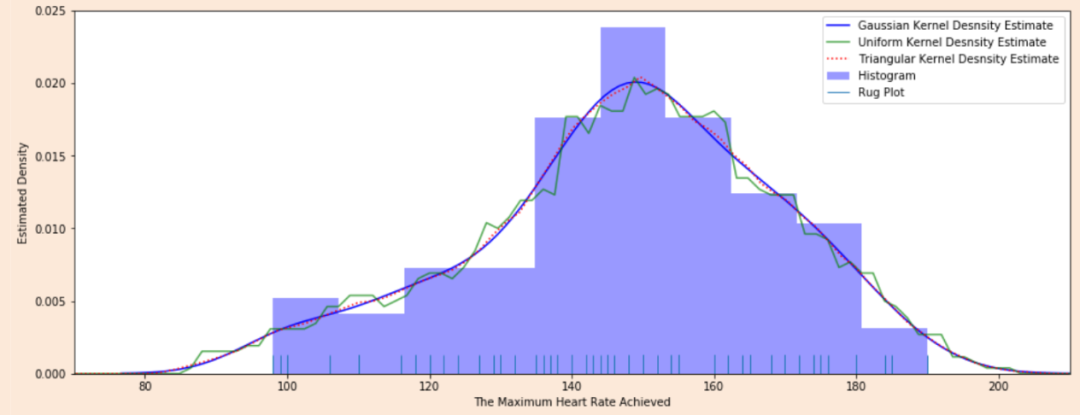 图2:心脏疾病患者最大心率的概率密度函数分布图,数据源自UCI ML开放数据集 这里在略微细讲下KDE,我们先看KDE函数: 是来自未知分布的样本, 是样本总数, 是核函数,h是带宽(Bandwidth)。核函数定义一个用于生成PDF(概率分布函数Probability Distribution Function)的曲线,不同于将值放入离散bins内,核函数对每个样本值都创建一个独立的概率密度曲线,然后加总这些平滑曲线,最终得到一个平滑连续的概率分布曲线,如下图所示: 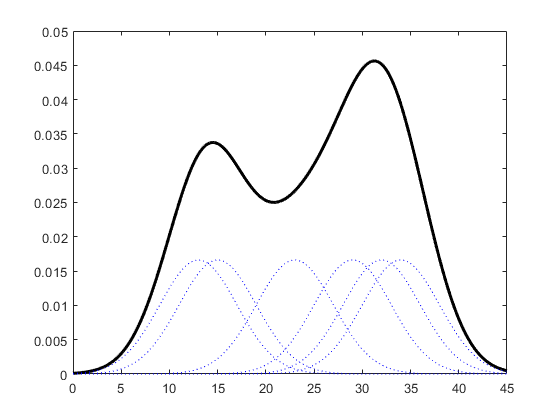 图3:生成KDE的过程呈现[3] 言归正传,对比训练集和测试集特征分布时,我们可以用seaborn.kdeplot()[4]进行绘图可视化,样例图和代码如下: 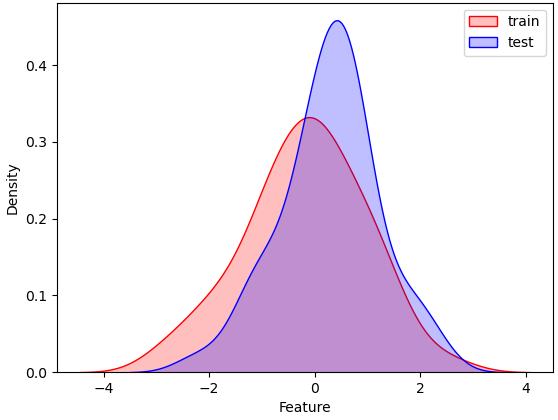 图4:不同数据集下的KDE对比 代码语言:javascript复制import numpy as np import seaborn as sns import matplotlib.pyplot as plt # 创建样例特征 train_mean, train_cov = [0, 2], [(1, .5), (.5, 1)] test_mean, test_cov = [0, .5], [(1, 1), (.6, 1)] train_feat, _ = np.random.multivariate_normal(train_mean, train_cov, size=50).T test_feat, _ = np.random.multivariate_normal(test_mean, test_cov, size=50).T # 绘KDE对比分布 sns.kdeplot(train_feat, shade = True, color='r', label = 'train') sns.kdeplot(test_feat, shade = True, color='b', label = 'test') plt.xlabel('Feature') plt.legend() plt.show()2.KS检验 KDE是PDF来对比,而KS检验是基于CDF(累计分布函数Cumulative Distribution Function)来检验两个数据分布是否一致,它也是非参数检验方法(即不知道数据分布情况)。两条不同数据集下的CDF曲线,它们最大垂直差值可用作描述分布差异(见下图5中的D)。 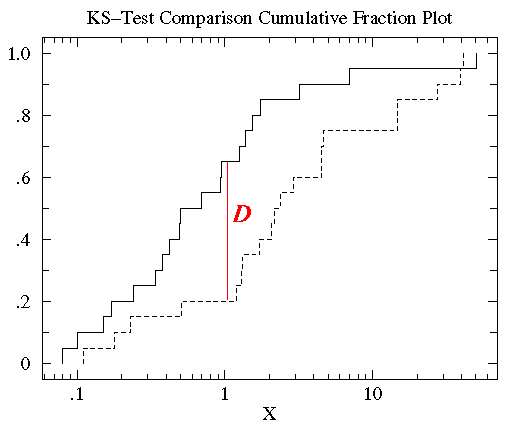 图5:不同数据集下的CDF对比[5] 调用scipy.stats.ks_2samp()[6]可轻松得到KS的统计值(最大垂直差)和假设检验下的p值: 代码语言:javascript复制from scipy import stats stats.ks_2samp(train_feat, test_feat) 输出:KstestResult(statistic=0.2, pvalue=0.2719135601522248)若KS统计值小且p值大,则我们可以接受KS检验的原假设H0,即两个数据分布一致。上面样例数据的统计值较低,p值大于10%但不是很高,因此反映分布略微不一致。注意: p值 |
【本文地址】