| 【遥感影像处理】最大似然分类(附MATLAB代码) | 您所在的位置:网站首页 › 计算机分类的方法 › 【遥感影像处理】最大似然分类(附MATLAB代码) |
【遥感影像处理】最大似然分类(附MATLAB代码)
|
引言
最大似然分类(也叫贝叶斯分类)是一种常见的监督分类的方法,其实现方法比较简单,因此通常会作为相关课程的编程小作业。这篇帖子就是以我自己做过的一个小作业为例进行说明。 原理最大似然分类是一种监督分类,监督分类的概念想必大家都清楚,我们需要将数据分为训练集和测试集。 至于最大似然的原理,网上有很多帖子都介绍了,我自己讲估计也讲不清楚,就只说一下编程实现的方法吧。 1. 通过训练集数据计算每一个类别的最大似然判别函数 要分多少个类别,就有多少个判别函数。判别函数中的x是一个列向量,比如一张RGB影像,其R、G、B值构成的列向量就是x。对于每一个类别,我们都可以计算该类别的像素的数学期望u(一般直接使用均值),u也是一个列向量,大小和x相同。对于每一个类别的像素,我们将他们放在一起,比如RGB影像中某一个类别有100个像素,我们可以将其排成一个矩阵,大小为3×100,第一行为所有像素的R值,第二行为G值,第三行为B值。使用这个矩阵可以计算出下面所说的协方差矩阵,大小为3×3。P(w)代表先验概率,这里我们可以认为其等于该类别在训练集中出现的概率(虽然这并不准确)。
2. 将每一个像素点的值代入进行计算 比如要分五个类别,第一步得到的结果就是对应于五个类别的五个判别函数,我们将训练集中的每一个像素点(即每一个像素点的RGB值构成的列向量作为x)都代入五个判别函数进行计算,哪一个函数计算的结果最大,说明该数据(像素点)属于这个类别的概率最大,分类完毕。 注意:上述的过程中使用的协方差阵和先验概率理论上来说是不相同的,协方差矩阵按照处理的问题的不同有不同的选择方法,先验概率也应该按照实际的数据进行计算,不能说分五个类别就简单的记为0.2。但是,从我最终运行的结果来看,将五个类别的协方差阵的和作为这五个类别的协方差阵,将每个类别的先验概率记为0.2时得到的结果是最好的。但还是要知道这并不是最正确的做法。至于具体原因,有兴趣的同学们可以自己去了解。 3. 评定分类结果的精度 这里采用最基础的混淆矩阵来进行评定,通过混淆矩阵可以计算kappa系数。 数据介绍训练数据和训练集的标签 这里展示两个版本的代码,第一个版本是我开头写的,对于每一个像素点采用的是for循环来进行计算,更容易理解,不过需要更多的运行时间,第二个版本是为了优化运行时间,将计算的过程改为了使用矩阵来进行(如果是编写C++代码的话,可以通过opencv或者eigen这些库来实现矩阵运算 )。 第一版,采用for循环: clear;clc;close all; %% 读取数据 train_data = double(imread('train_data.tiff')); train_label = rgb2gray(imread('train_label.tiff')); check_data = double(imread('check_data.tiff')); check_label = rgb2gray(imread('check_label.tiff')); %% 把图像缩小 ,测试效果 k = 0.2; train_data = imresize(train_data,k,'nearest'); train_label = imresize(train_label,k,'nearest'); check_data = imresize(check_data,k,'nearest'); check_label = imresize(check_label,k,'nearest'); %% 从训练集的标签数据中找到每个类别的位置信息,以及所占的百分比 % tag 第一列为label中类别的编号,第二列为该类别的像素的数量,第三列为所占的百分比 tag = tabulate(train_label(:)); % 如果label中的类别数将占比最低的类别去掉 if size(tag,1) > 5 rt = tag(:,3) > min(tag(:,3)); tag = tag(rt,:); end % 将每一个类别的像素的 r\g\b 值保存到一个类别的矩阵中 r = train_data(:,:,1);g = train_data(:,:,2);b = train_data(:,:,3); V1(:,1) = r(train_label == tag(1,1)); V1(:,2) = g(train_label == tag(1,1)); V1(:,3) = b(train_label == tag(1,1)); V2(:,1) = r(train_label == tag(2,1)); V2(:,2) = g(train_label == tag(2,1)); V2(:,3) = b(train_label == tag(2,1)); V3(:,1) = r(train_label == tag(3,1)); V3(:,2) = g(train_label == tag(3,1)); V3(:,3) = b(train_label == tag(3,1)); V4(:,1) = r(train_label == tag(4,1)); V4(:,2) = g(train_label == tag(4,1)); V4(:,3) = b(train_label == tag(4,1)); V5(:,1) = r(train_label == tag(5,1)); V5(:,2) = g(train_label == tag(5,1)); V5(:,3) = b(train_label == tag(5,1)); %% 计算判别函数 % 计算均值 这里的均值向量是 3×1 的列向量 u1 = mean(V1)';u2 = mean(V2)';u3 = mean(V3)';u4 = mean(V4)';u5 = mean(V5)'; % 计算协方差矩阵 c1 = cov(V1);c2 = cov(V2);c3 = cov(V3);c4 = cov(V4);c5 = cov(V5); % 假设协方差阵相同 c = c1 + c2 + c3 + c4 + c5; % 各个类别的判别函数 tic f1 = Jug_Func(u1,c,0.2); f2 = Jug_Func(u2,c,0.2); f3 = Jug_Func(u3,c,0.2); f4 = Jug_Func(u4,c,0.2); f5 = Jug_Func(u5,c,0.2); fprintf('生成判别函数用时:%f 秒\n',toc); %% 把每一个像素都代入判别式中进行计算 [height,width,channel] = size(check_data); % 用来保存分类结果 Res = zeros(height,width); tic % 显示进度条 bar = waitbar(0,'开始逐像素计算...'); for i = 1:height for j = 1:width x1 = check_data(i,j,1);x2 = check_data(i,j,2);x3 = check_data(i,j,3); rs(1) = f1*[x1,x2,x3,1]'; rs(2) = f2*[x1,x2,x3,1]'; rs(3) = f3*[x1,x2,x3,1]'; rs(4) = f4*[x1,x2,x3,1]'; rs(5) = f5*[x1,x2,x3,1]'; [~,index] = max(rs); Res(i,j) = tag(index,1); % 更新进度条 str = ['计算中.....',num2str((i-1)*width + j),'/',num2str(width*height),',用时',num2str(toc),'秒']; waitbar(((i-1)*width + j)/(width*height),bar,str); end end close(bar); fprintf('分类过程用时: %f 秒\n',toc); %% 展示分类结果 figure() subplot(1,3,1);imshow(uint8(check_data));title('待分类影像') subplot(1,3,2);imshow(check_label);title('参考分类结果') subplot(1,3,3);imshow(uint8(Res));title('最大似然分类结果') %% 计算混淆矩阵来评估分类效果,CM_i 直接记录像素数量,CM_p记录百分比 CM_i = zeros(6,6);CM_p = CM_i; % 分类结果中不同类别的位置,用逻辑矩阵表示 R1 = Res == tag(1,1);R2 = Res == tag(2,1);R3 = Res == tag(3,1); R4 = Res == tag(4,1);R5 = Res == tag(5,1); for i = 1:5 % 标签中属于第 i 类的像素位置,用逻辑矩阵表示 Li = check_label == tag(i,1); % 进行逻辑与运算 ,统计被分到每个类别的像素数量 CM_i(i,6) = sum(Li,'all'); CM_i(i,1) = sum(Li & R1,'all'); CM_i(i,2) = sum(Li & R2,'all'); CM_i(i,3) = sum(Li & R3,'all'); CM_i(i,4) = sum(Li & R4,'all'); CM_i(i,5) = sum(Li & R5,'all'); end CM_i(6,1) = sum(R1,'all');CM_i(6,2) = sum(R2,'all'); CM_i(6,3) = sum(R3,'all');CM_i(6,4) = sum(R4,'all'); CM_i(6,5) = sum(R5,'all');CM_i(6,6) = height*width; CM_p(:,1) = CM_i(:,1) ./ CM_i(:,6);CM_p(:,2) = CM_i(:,2) ./ CM_i(:,6); CM_p(:,3) = CM_i(:,3) ./ CM_i(:,6);CM_p(:,4) = CM_i(:,4) ./ CM_i(:,6); CM_p(:,5) = CM_i(:,5) ./ CM_i(:,6);CM_p(1:5,6) = CM_i(1:5,6) / CM_i(6,6); CM_p(6,6) = 1; %% 保存数据 train_data = uint8(train_data);train_label = uint8(train_label); check_data = uint8(check_data);check_label = uint8(check_label); Res = uint8(Res); save('All.mat','train_data','train_label','check_data','check_label','Res','CM_i','CM_p'); imwrite(Res,'分类结果.jpg'); %% 判别函数,x 为每个像素点的 r\g\b 值, u 为均值向量,C 为协方差阵,Pw 为先验概率 function result = Jug_Func(u,C,Pw) wi=inv(C)*u; wio=-0.5*u'*inv(C)*u-0.5*log(det(C))+log(Pw); result = [wi(1),wi(2),wi(3),wio]; end第二版,使用矩阵进行计算,优化了运行时间: clear;clc;close all; %% 读取数据 train_data = double(imread('train_data.tiff')); train_label = rgb2gray(imread('train_label.tiff')); check_data = double(imread('check_data.tiff')); check_label = rgb2gray(imread('check_label.tiff')); %% 从训练集的标签数据中找到每个类别的位置信息,以及所占的百分比 % tag 第一列为label中类别的编号,第二列为该类别的像素的数量,第三列为所占的百分比 tag = tabulate(train_label(:)); % 如果label中的类别数将占比最低的类别去掉 if size(tag,1) > 5 rt = tag(:,3) > min(tag(:,3)); tag = tag(rt,:); end % 将每一个类别的像素的 r\g\b 值保存到一个类别的矩阵中 r = train_data(:,:,1);g = train_data(:,:,2);b = train_data(:,:,3); V1(:,1) = r(train_label == tag(1,1)); V1(:,2) = g(train_label == tag(1,1)); V1(:,3) = b(train_label == tag(1,1)); V2(:,1) = r(train_label == tag(2,1)); V2(:,2) = g(train_label == tag(2,1)); V2(:,3) = b(train_label == tag(2,1)); V3(:,1) = r(train_label == tag(3,1)); V3(:,2) = g(train_label == tag(3,1)); V3(:,3) = b(train_label == tag(3,1)); V4(:,1) = r(train_label == tag(4,1)); V4(:,2) = g(train_label == tag(4,1)); V4(:,3) = b(train_label == tag(4,1)); V5(:,1) = r(train_label == tag(5,1)); V5(:,2) = g(train_label == tag(5,1)); V5(:,3) = b(train_label == tag(5,1)); %% 计算判别函数 % 计算均值 这里的均值向量是 3×1 的列向量 u1 = mean(V1)';u2 = mean(V2)';u3 = mean(V3)';u4 = mean(V4)';u5 = mean(V5)'; % 计算协方差矩阵 c1 = cov(V1);c2 = cov(V2);c3 = cov(V3);c4 = cov(V4);c5 = cov(V5); % 假设协方差阵相同 c = c1 + c2 + c3 + c4 + c5; % 各个类别的判别函数 tic % 假设先验概率相同的情况 f1 = Jug_Func(u1,c,0.2); f2 = Jug_Func(u2,c,0.2); f3 = Jug_Func(u3,c,0.2); f4 = Jug_Func(u4,c,0.2); f5 = Jug_Func(u5,c,0.2); % 先验概率不同的情况 % f1 = Jug_Func(u1,c,tag(1,3)); % f2 = Jug_Func(u2,c,tag(2,3)); % f3 = Jug_Func(u3,c,tag(3,3)); % f4 = Jug_Func(u4,c,tag(4,3)); % f5 = Jug_Func(u5,c,tag(5,3)); fprintf('生成判别函数用时:%f 秒\n',toc); %% 把每一个像素都代入判别式中进行计算 [height,width,channel] = size(check_data); % 用来保存分类结果 Res = zeros(height,width); tic rs = zeros(height,width,5); rs(:,:,1) = check_data(:,:,1)*f1(1) + check_data(:,:,2)*f1(2) + check_data(:,:,3)*f1(3) + ones(height,width)*f1(4); rs(:,:,2) = check_data(:,:,1)*f2(1) + check_data(:,:,2)*f2(2) + check_data(:,:,3)*f2(3) + ones(height,width)*f2(4); rs(:,:,3) = check_data(:,:,1)*f3(1) + check_data(:,:,2)*f3(2) + check_data(:,:,3)*f3(3) + ones(height,width)*f3(4); rs(:,:,4) = check_data(:,:,1)*f4(1) + check_data(:,:,2)*f4(2) + check_data(:,:,3)*f4(3) + ones(height,width)*f4(4); rs(:,:,5) = check_data(:,:,1)*f5(1) + check_data(:,:,2)*f5(2) + check_data(:,:,3)*f5(3) + ones(height,width)*f5(4); [~,index] = max(rs,[],3); for i = 1:5 Res(index==i) = tag(i,1); end fprintf('分类过程用时: %f 秒\n',toc); %% 展示分类结果 figure() subplot(1,3,1);imshow(uint8(check_data));title('待分类影像') subplot(1,3,2);imshow(check_label);title('参考分类结果') subplot(1,3,3);imshow(uint8(Res));title('最大似然分类结果') %% 计算混淆矩阵来评估分类效果,CM_i 直接记录像素数量,CM_p记录百分比 CM_i = zeros(6,6);CM_p = CM_i; % 分类结果中不同类别的位置,用逻辑矩阵表示 R1 = Res == tag(1,1);R2 = Res == tag(2,1);R3 = Res == tag(3,1); R4 = Res == tag(4,1);R5 = Res == tag(5,1); for i = 1:5 % 标签中属于第 i 类的像素位置,用逻辑矩阵表示 Li = check_label == tag(i,1); % 进行逻辑与运算 ,统计被分到每个类别的像素数量 CM_i(i,6) = sum(Li,'all'); CM_i(i,1) = sum(Li & R1,'all'); CM_i(i,2) = sum(Li & R2,'all'); CM_i(i,3) = sum(Li & R3,'all'); CM_i(i,4) = sum(Li & R4,'all'); CM_i(i,5) = sum(Li & R5,'all'); end CM_i(6,1) = sum(R1,'all');CM_i(6,2) = sum(R2,'all'); CM_i(6,3) = sum(R3,'all');CM_i(6,4) = sum(R4,'all'); CM_i(6,5) = sum(R5,'all');CM_i(6,6) = height*width; CM_p(:,1) = CM_i(:,1) ./ CM_i(:,6);CM_p(:,2) = CM_i(:,2) ./ CM_i(:,6); CM_p(:,3) = CM_i(:,3) ./ CM_i(:,6);CM_p(:,4) = CM_i(:,4) ./ CM_i(:,6); CM_p(:,5) = CM_i(:,5) ./ CM_i(:,6);CM_p(1:5,6) = CM_i(1:5,6) / CM_i(6,6); CM_p(6,6) = 1; %% 保存数据 train_data = uint8(train_data);train_label = uint8(train_label); check_data = uint8(check_data);check_label = uint8(check_label); Res = uint8(Res); save('All.mat','train_data','train_label','check_data','check_label','Res','CM_i','CM_p'); imwrite(Res,'分类结果.jpg'); %% 判别函数,x 为每个像素点的 r\g\b 值, u 为均值向量,C 为协方差阵,Pw 为先验概率 function result = Jug_Func(u,C,Pw) wi=inv(C)*u; wio=-0.5*u'*inv(C)*u-0.5*log(det(C))+log(Pw); result = [wi(1),wi(2),wi(3),wio]; end 运行结果两个版本的运行结果是一致的 总之按照这个流程,改写成C++版本的应该并不困难,矩阵运算推荐使用Eigen库。这个运行结果可以看出很多地方是没有被正确分类的,不过也只能做这种程度了,先验概率和协方差矩阵那里有兴趣的可以自己更改一下试试效果,使用的数据不同,这两个因素对结果会有一些影响。 |
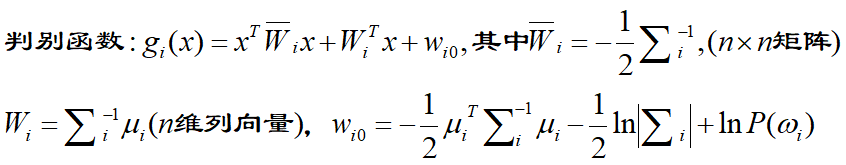 其中:
其中: 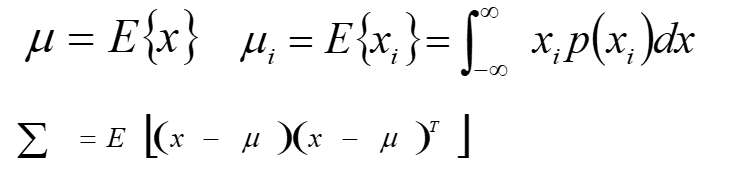
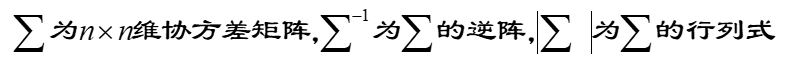
 待分类的影像和该影像的标签(需要标签数据来评定分类结果的精度)
待分类的影像和该影像的标签(需要标签数据来评定分类结果的精度) 
 与标签相对比,可以看出大体是可以分类出来的,更多的分析可以使用混淆矩阵进行
与标签相对比,可以看出大体是可以分类出来的,更多的分析可以使用混淆矩阵进行 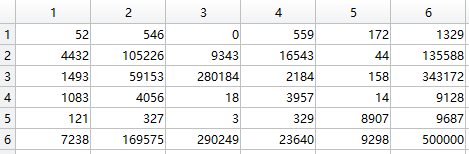
【本文地址】