| 视觉SLAM中的深度估计问题 | 您所在的位置:网站首页 › 视觉slam什么意思 › 视觉SLAM中的深度估计问题 |
视觉SLAM中的深度估计问题
|
一、研究背景 视觉SLAM需要获取世界坐标系中点的深度。 世界坐标系到像素坐标系的转换为(深度即Z):
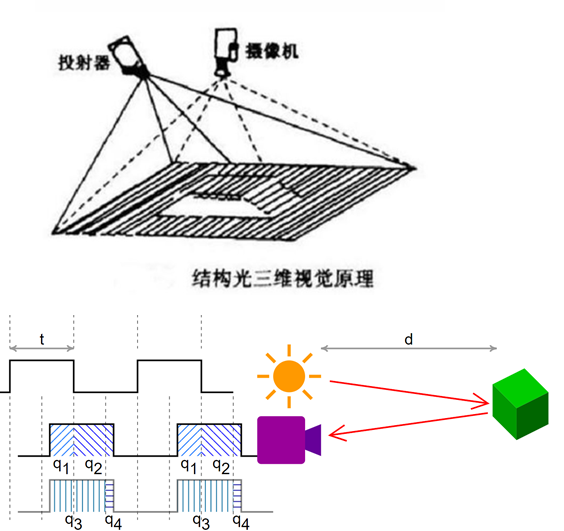
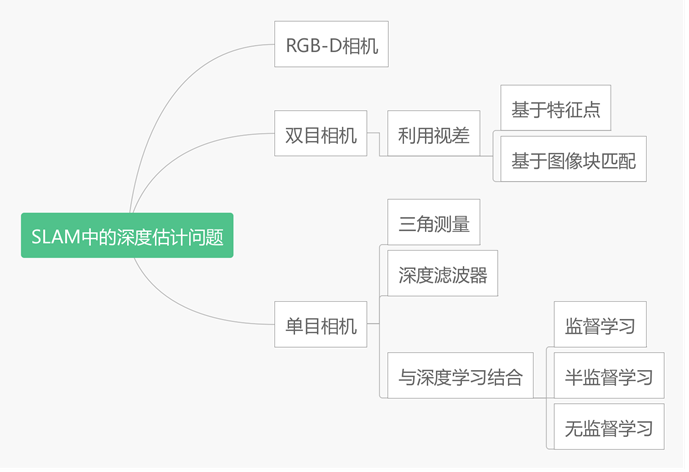
深度的获取一共分两种方式: a)主动式 RGB-D相机按照原理又分为结构光测距、ToF相机 ToF相机原理
b)被动 被动式无法精确得到点的深度值,因此存在深度的估计问题,按照主流相机的种类可以分为双目相机估计以及单目相机估计。 接下来详细介绍双目系统以及单目SLAM系统的深度估计问题
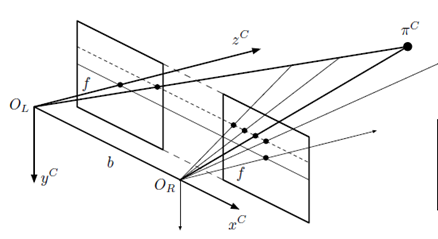
二、双目系统 双目相机模型如下图所示:
(图源《视觉SLAM十四讲》)
要计算深度z,需要已知世界坐标系中一点在左相机与右相机中对应的像素坐标UL与UR,即视差d。 获取d关键在于双目匹配,即左相机与右相机中的像素坐标对应的世界坐标系中的同一点。 举例: ORB-SLAM2基于特征点获取视差:FAST特征点+BREIF算子。
得到匹配到的像素必须满足通过对极约束:
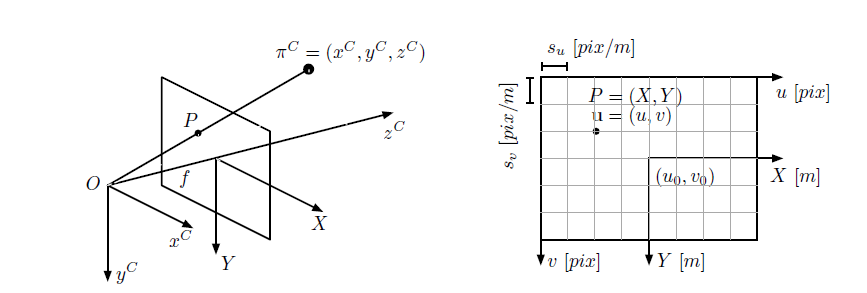
三、单目相机 针孔相机模型为:
相机坐标系下为(xC,yC,zC),像素坐标系为(u,v),归一化坐标系为(u0,v0)
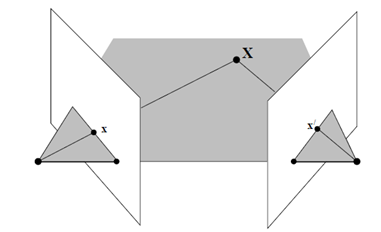
3.1 三角化估计深度 通过两处观察同一个夹角,从而确定该点的距离
在通过对极几何求得R,t后,R,t已知
通过优化方法可求得上式中右边的最小二乘解,三角化的矛盾:平移增大,测量的精度会变高,但是可能会导致匹配失效。 ORB-SLAM单目中的三角化代码如下,可作参考: void Initializer::Triangulate(const cv::KeyPoint &kp1, const cv::KeyPoint &kp2, const cv::Mat &P1, const cv::Mat &P2, cv::Mat &x3D) { cv::Mat A(4,4,CV_32F); A.row(0) = kp1.pt.x*P1.row(2)-P1.row(0); A.row(1) = kp1.pt.y*P1.row(2)-P1.row(1); A.row(2) = kp2.pt.x*P2.row(2)-P2.row(0); A.row(3) = kp2.pt.y*P2.row(2)-P2.row(1); cv::Mat u,w,vt; cv::SVD::compute(A,w,u,vt,cv::SVD::MODIFY_A| cv::SVD::FULL_UV); x3D = vt.row(3).t(); x3D = x3D.rowRange(0,3)/x3D.at(3); }
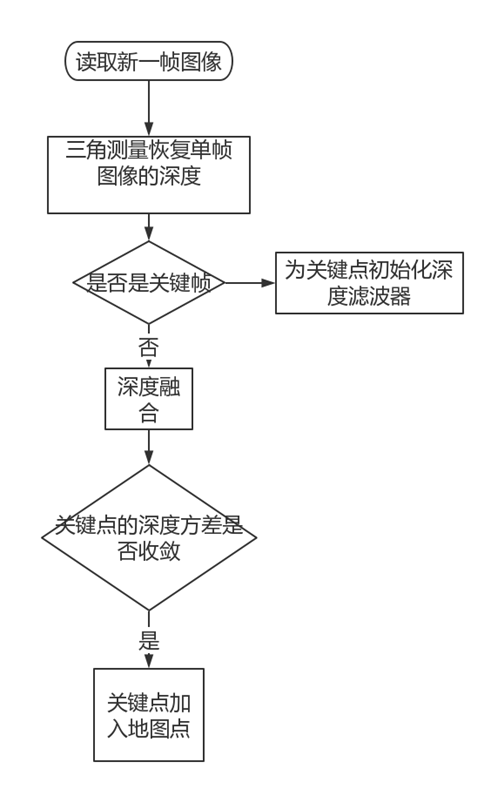
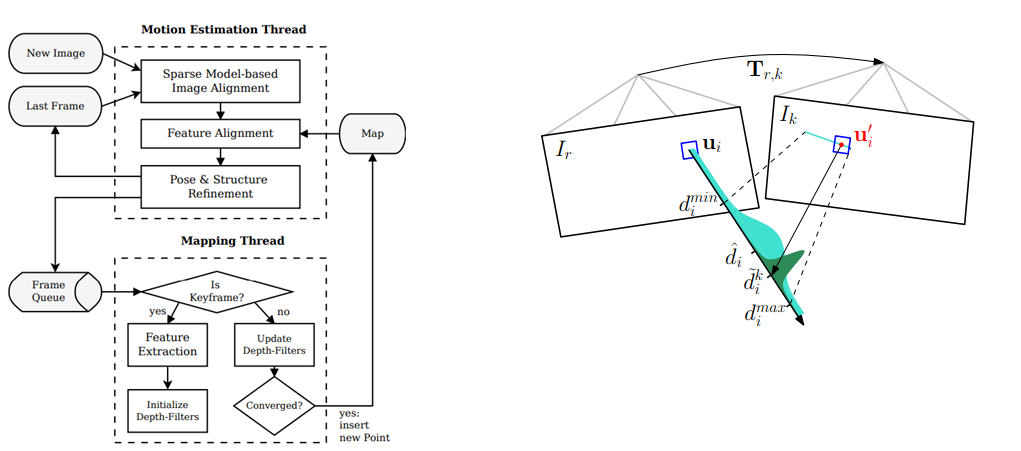
3.2 深度滤波器 本质上为卡尔曼滤波估计深度 假设深度服从某种分布,最后深度的方差不断减少并收敛 以SVO为例: SVO估计深度流程如下:
SVO中点服从高斯均匀分布:
点深度满足分布:
3.3 与监督学习结合
[1]Tateno, K., Tombari, F., Laina, I., & Navab, N. (2017, July). CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Vol. 2). [2] Eigen D, Fergus R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 2650-2658.
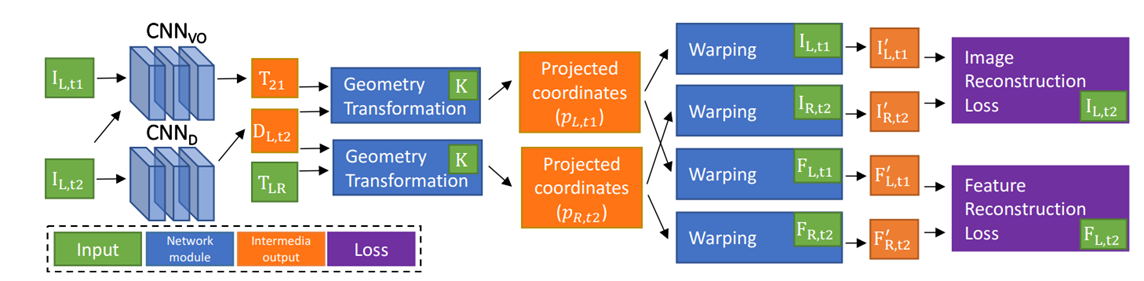
3.4 与非监督学习结合
总结一下思想:
矩阵T21的估计值,深度估计网络根据单目图像,输出深度的估计值。该值再结合左右视图的变换矩阵TLR,以及相机的内参K,可以从左图重构出右图,还可以把左图的特征映射到右图。重构图和特征与真值的差异构成了损失函数,利用反向传播算法可以不断优化网络。 Zhan, H., Garg, R., Weerasekera, C. S., Li, K., Agarwal, H., & Reid, I. (2018, March). Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 340-349).
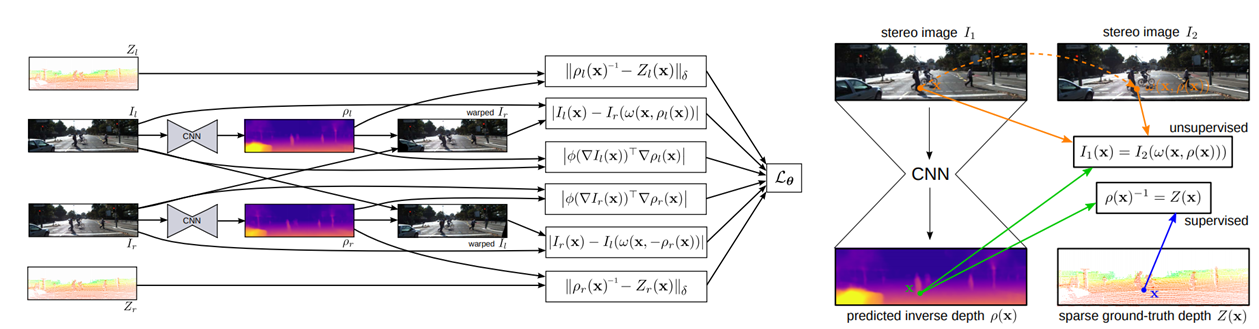
3.5 与半监督学习结合
监督学习部分 ground-truth depth由激光雷达提供,无监督学习部分由双目相机的图像训练。损失函数的构成:预测深度与groud-truth的差,左图与右图+左深度图重构的左图的光度误差,右图与左图重构的光度误差,泛化损失:对深度和灰度求梯度。 Kuznietsov, Y., Stückler, J., & Leibe, B. (2017, July). Semi-supervised deep learning for monocular depth map prediction. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 6647-6655).
四、总结
|
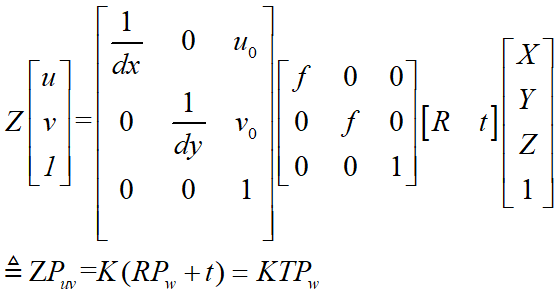
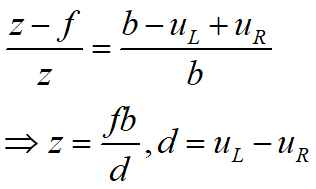

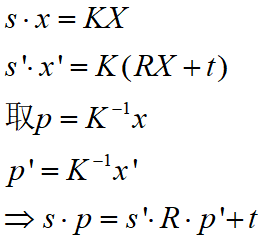
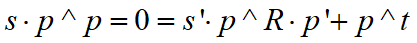
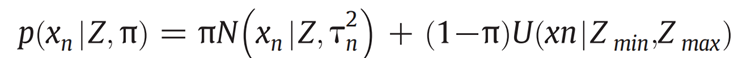
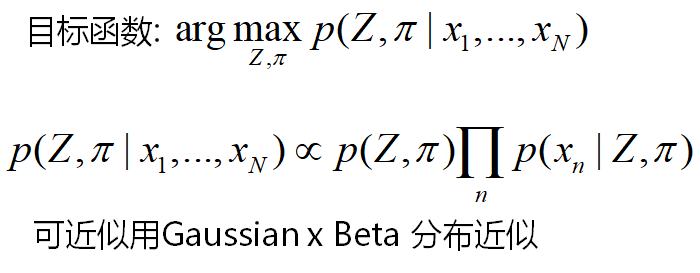


【本文地址】