| CMU 15 | 您所在的位置:网站首页 › 西双版纳的大象现在到哪儿了 › CMU 15 |
CMU 15
|
日安,这里是码呆茶。4 月活动比较多,空余时间更加碎片化。因为总是断断续续地写,花费的时间远超过预期,目前关于并发的优化就暂时搁置了。完成 Project 2 实验的时间线如下: DateMilestone2023/04/02写了 Homework 22023/04/08通过 Project 2 Checkpoint 12023/04/17完成 B+ 树删除逻辑2023/04/19通过 Project 2 Checkpoint 2先说 Homework 2,对我来说这次作业还挺有收获的:一方面,今年 P1 没有考察 Extendible Hash Table 的实现;另一方面,听完视频课对 B+Tree 的理解确实还不够。作业可以帮助我们巩固这些知识。 下面就以自问自答的形式,记录一下在做 Project 2 过程中用到的参考资料、踩的坑及个人的理解。 ReferencesProject 2 要求:Project #2 - B+Tree - CMU 15-445/645 :: Intro to Database Systems (Spring 2023)官方的讨论频道:常见问题 | CMU 15-445/645 :: 数据库系统简介(2023 年春季)胡神的交流群:CMU 15-445:知名教授历时多年打磨,数据库神级课程限时免费! - 知乎 (zhihu.com)Checkpoint 1Q1:b_plus_tree_page中array_[0]的作用?B+Tree 的每个节点都对应 Project 1 中实现的 Buffer Pool Manager 中的每一页。Page类包含了一个长度为 4096 字节的数据部分data_,这就是我们 B+Tree 节点所分配的内存大小。在 Spring 2023 的 Bustub 中,共有三种类型的节点: b_plus_tree_internal_page:中间节点,键值对数组的值为对应子节点的 page id;b_plus_tree_leaf_page:叶节点, 键值对数组的值为 RID,记录了到元组的信息;b_plus_tree_header_page :头节点,存储了 root page id,使得根节点也和非根节点一样拥有父节点每次对 B+Tree 的节点进行查询或修改前,我们都需要先从 Buffer Pool Manager 中获取 Page,之后将其数据部分data_通过reinterpret_cast强制转换为对应的节点类(也可以使用 Page Guard 封装好的As或AsMut方法进行转换)。 而b_plus_tree_leaf_page和b_plus_tree_internal_page中的成员array_[0]是柔性数组 (Flexible Array),当其作为类中的最后一个成员时,在为对象分配内存时,会自动填充未被其他变量使用的内存[1]。 关于这方面的详细知识,可以参考十一大佬的博客,有很多易于理解的配图: 而在插入的过程中,就有可能用到这一特性:B+Tree 对叶节点和中间节点的分裂的处理逻辑是不同的—— 对叶节点,我们在插入后键值对数量达到leaf_max_size_时立刻进行分裂;而对于中间节点,则是在插入后键值对数量达到internal_max_size_ + 1时才进行分裂。这就意味着插入时无法直接在中间节点上先插入再分裂,有可能溢出。教材的伪代码中,建议我们单独开辟一块内存空间,在完成插入与分裂后释放。  因此,利用 Flexible Array 的特性,我们可以先申请一片大小为 BUSTUB_PAGE_SIZE + sizeof(MappingType)的内存空间, 将其强制转换为b_plus_tree_internal_page类型,从而我们可容纳的键值对数量就是INTERNAL_PAGE_SIZE + 1 ,可以完成插入操作。 当然,对于中间节点的插入,也可以使用先计算出应插入的 index、分裂后再将键插入到左节点或右节点的方式。可以减少一次复制的操作。 Q2:确定 Min Size 与 Max Size?Task 1 要求我们补充 B+Tree 节点的方法。而这里的 Min Size 与 Max Size 就比较让人困惑——比如对于中间节点,位于array_[0]的键是无效的,那么计算 Size 时是否应该考虑呢? 对于GetSize()、GetMaxSize()、GetMinSize()这几个方法的实现,可以使用课程组提供的 BPT Printer,在每次修改 B+Tree 后,都会显示每个节点的大小信息,有助于理解这些概念。 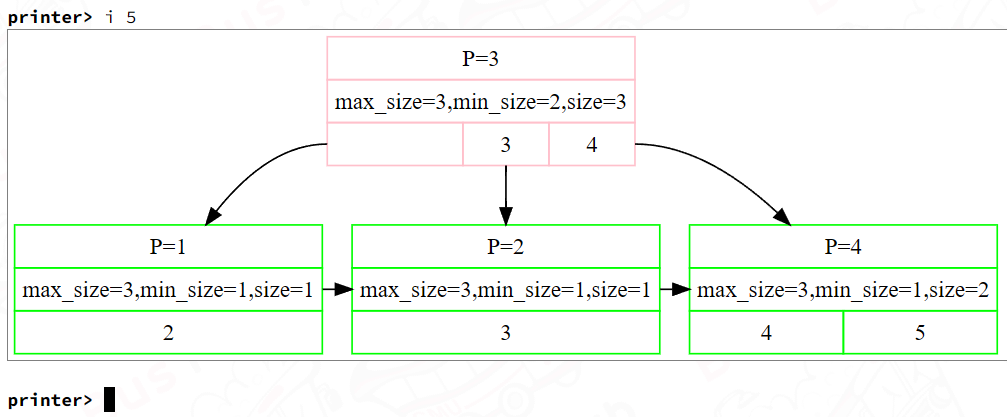 比如在这里我新建了一棵leaf_max_size_ = 3, internal_max_size_ = 3的 B+Tree,可以发现叶节点的min_size为 \lfloor{max\_size/2}\rfloor ,而中间节点的min_size为 \lceil{max\_size/2}\rceil 。 Q3:在 Internal Page 二分查找的方式?中间节点比较特殊,在array_[0]位置的键无效,存储的是比array_[1]的键小的子节点。在查找的过程中,我们或者找到第一个满足 v\leq C.K_i 的键值对,或者在无法找到时使用最后一个键值对。而这可以很好地概括为「找到第一个严格大于 key v 的节点的前一个节点」[2]:对不存在这样的节点的情况,迭代器将停留在GetSize()处,此时index-1即为最后一个键值对。 而 C++ 的std::upper_bound函数返回第一个严格大于给定 key 的值的迭代器,并支持传入比较的 Lamda 函数[3]。对于中间节点,我们从array[1]位置开始搜索,那么可以这样处理: int index = std::upper_bound(array_ + 1, array_ + GetSize(), key, comparator) - array_ - 1;这里有个小坑点就是std::upper_bound和std::lower_bound传入的 comparator 的参数是不同的,但对匿名函数,Language Server 不会直接报错,所以直到编译了才会给一大堆报错……  Q5:相比 Fall 2022,Spring 2023 的改动? Q5:相比 Fall 2022,Spring 2023 的改动?如果你和我一样,遇到瓶颈时就到网上搜搜大佬写的博客,那么就可以发现 Spring 2023 的 Project 2 有很多让实现难度变得更低、Coding 过程更加愉悦的改动: Page Guard:在 2023 Project 1 中新增的功能,大大降低了写 Project 2 的心智负担。可以在超出作用域时自动释放持有的 Page 锁、进行 Unpin 操作;此外如果使用了AsMut转换,还会自动置脏。更加简单的节点结构:在之前的版本中,节点中还包含了 Parent ID 等成员,所以在更新父节点的信息时,还需要同步更新子节点信息;但为了确保加锁顺序是一致的,基本不会有用到GetParentId()的情况。独立的 Context:在之前的版本中,要保存父节点的锁时,需要把父节点队列存到Transaction中,其中还包含了不少在后续 Project 才需要用到的功能;而在 Spring 2023 中,使用 Context 来保存父节点队列。Header Page:在之前的版本中,BPlusTree 直接存储了根节点的 Page ID,因此在更新根节点时通常还需要额外的锁,并且螃蟹规则也对根节点不起作用;在使用 Header Page 单独存储根节点 Page ID 后,就可以把螃蟹规则同样运用在根节点上了。Q6:将单线程 B+Tree 的插入与删除可视化?课程组已经为我们提供了 B+Tree 的可视化工具链,在此基础上可以安装 Graphviz 插件。让程序在每次插入和删除后都进行打印,在还不熟悉 B+Tree 的插入与删除逻辑时,很有帮助。 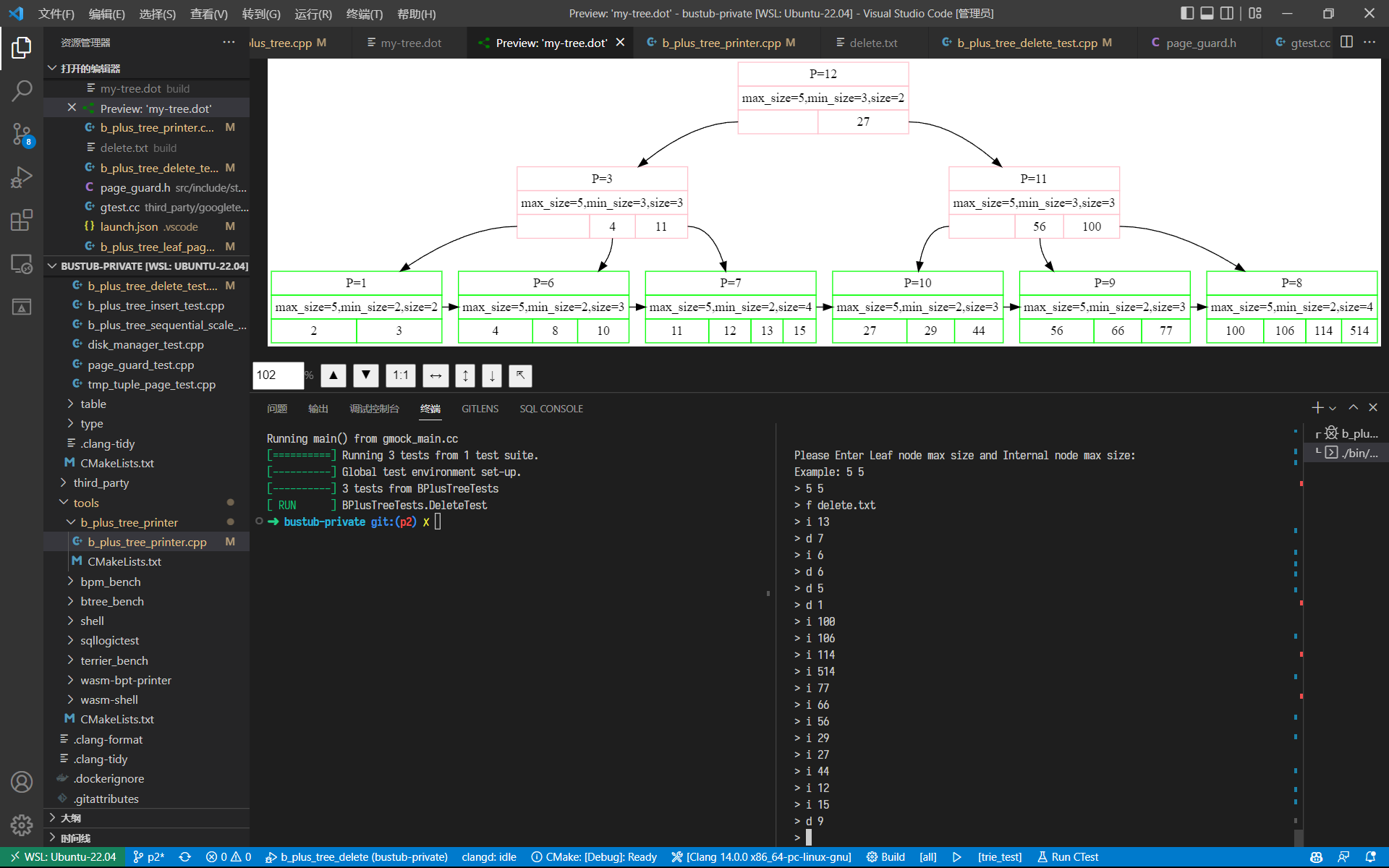 Q6:分析单线程 B+Tree 的性能瓶颈? Q6:分析单线程 B+Tree 的性能瓶颈?在阅读大佬们写的博客时,发现有好多大佬都在用火焰图分析性能瓶颈。但我是在 WSL 2 开发的,没有可用的 linux-tools-common,因此需要手动编译[4]: # windows wsl --update # wsl 2 sudo apt install flex bison sudo apt install libdwarf-dev libelf-dev libnuma-dev libunwind-dev \ libnewt-dev libdwarf++0 libelf++0 libdw-dev libbfb0-dev \ systemtap-sdt-dev libssl-dev libperl-dev python-dev-is-python3 \ binutils-dev libiberty-dev libzstd-dev libcap-dev libbabeltrace-dev git clone https://github.com/microsoft/WSL2-Linux-Kernel --depth 1 cd WSL2-Linux-Kernel/tools/perf make -j8 # parallel build sudo cp perf /usr/local/bin perf --version # check if perf has been installed之后安装 FlameGraph,并添加到环境变量: git clone https://github.com/brendangregg/FlameGraph.git --depth 1 sudo mv FlameGraph /opt/FlameGraph vim ~/.zshrc source ~/.zshrc # ~/.zshrc export PATH=$PATH:/opt/FlameGraph现在我们就可以愉快地绘制火焰图了,以 b_plus_tree_insert_test为例: cd build make b_plus_tree_insert_test perf record -g ./test/b_plus_tree_insert_test perf script | stackcollapse-perf.pl | flamegraph.pl > out.svg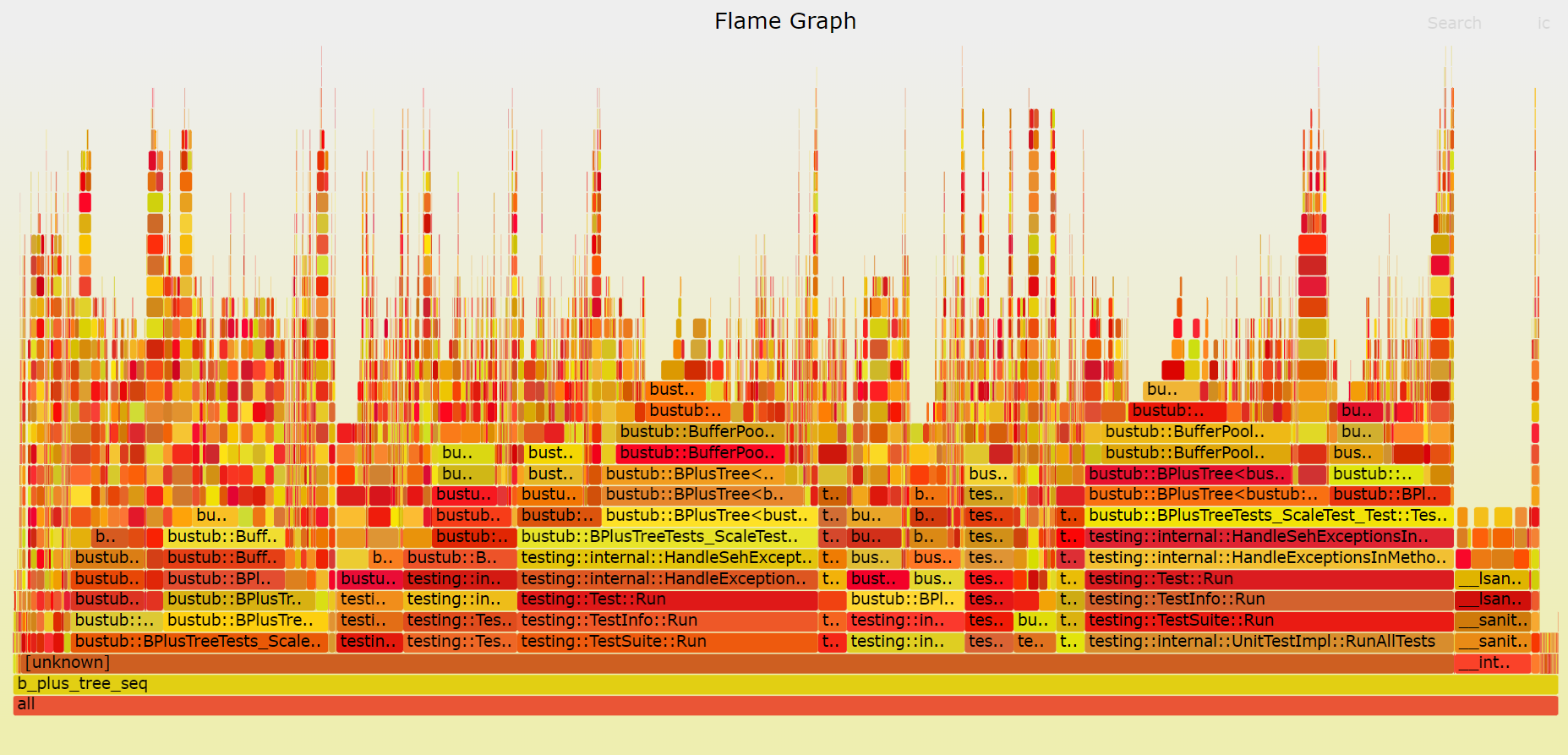 Checkpoint 2Q7:B+Tree 删除的过程是怎样的? Checkpoint 2Q7:B+Tree 删除的过程是怎样的?教材给出了一页的伪代码……删除的过程确实是非常复杂,这里推荐几篇大佬的博客: Jackson wang 的文章把教材里的演示图汇集在了一起,不用在 PDF 中来回翻页了。 xiao 的文章给出了多个具体的例子,可以在完成自己的实现后对比一下。 Q8:将螃蟹法则运用在 B+Tree 的并发中?在单线程版本中,我基本上都是使用FetchPageWrite获取 Page,原则上已经可以保证多线程的正确性。而在改写多线程版本时,需要做的就是: GetValue:使用读锁,获取子节点的读锁后释放父节点的读锁;Insert/Remove:如果确认节点不会分裂/合并/重分配,就将 Context 中存储的父节点都进行释放;InsertIntoParent/DeleteEntry:因为用到了 Page Guard,而InsertIntoParent又存在递归的情况,所以可能会出现 Page Guard 的生命周期在函数递归的全过程中,从而直到完成递归才释放 Page,导致 out of memory,因此需要在进入下一级递归时,及时释放当前持有的不需要的 Page Guard。Q9:多线程 Debug 的打开方式?在完成 Task 4 后,我开始了本地测试,然而在 Concurrent Insert 部分的测试,却出现了死锁。 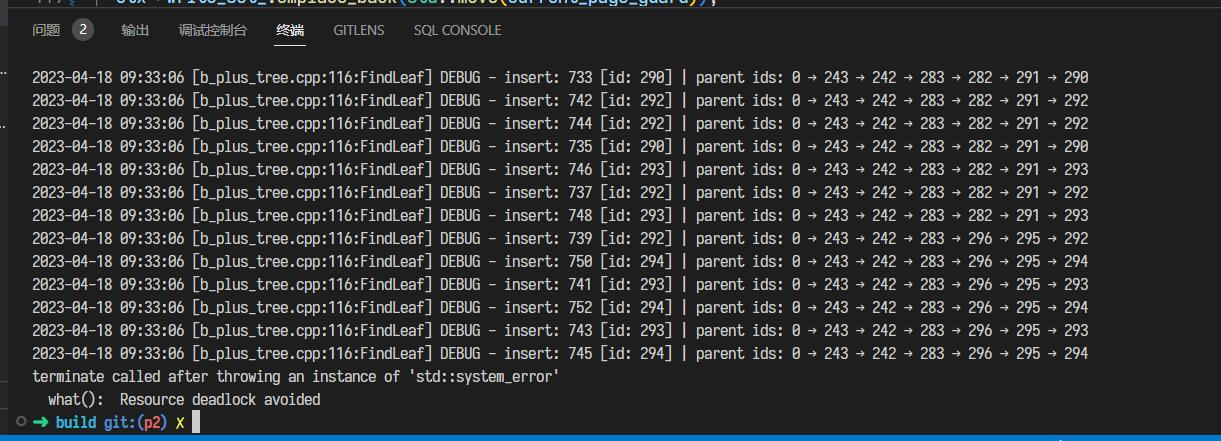 对删除操作,存在对 Sibling 节点加锁的情况,但由于持有父节点的写锁,因此在迭代器不使用读锁的情况下,不会有其他线程请求 Sibling,因而不会发生死锁;而对于 Insert 情况,获取锁的方向始终都是自顶向下的,所以按理来说更不会发生死锁。 于是我便怀疑是否是之前 Project 1 的并发 I/O 导致了死锁。经过不断地打 Log,终于发现了明显是 Buffer Pool Manager 原因的死锁情况:如果 frame 47 上原有的 page 1568 刚刚被驱逐而写回磁盘,此时又立刻请求 page 1568 的内容,就会出现无法读取 page 1568 的情况,从而破坏树的结构,进而导致各种奇怪的并发问题。  关于这里我还是有一些疑惑,因为 disk manager 是线程安全的,所以我原本是在进行磁盘 I/O 之前先释放了 BPM 的读写锁,仅保留 frame 的锁。在将刷脏的操作放入 BPM 读写锁的作用域后,这一问题就得到了解决。 而在多线程 Debug 中,打 Log 应该是最主要的一种方式,虽然有时打完 Log 问题就不复现了……  这次也学习了 C++ 打印日志的方式: // log write set #ifdef MONDAYCHA_P2_DEBUG auto log = std::stringstream(); // operation log |
【本文地址】