| AdaBoost基本原理与详细公式推导 | 您所在的位置:网站首页 › 自守函数理论推导 › AdaBoost基本原理与详细公式推导 |
AdaBoost基本原理与详细公式推导
|
目录
Boosting简介AdaBoost1. 基本思路2. 算法过程3. 算法解释3.1 加法模型3.2 指数损失函数3.3 前向分步算法3.4 推导证明3.4.1 优化
G
m
(
x
)
G_m(x)
Gm(x)3.4.2 优化
α
m
\alpha_m
αm
机器学习中有一类集成学习算法,它基于一组弱学习器进行组合提升,得到具有优越性能的强学习器。集成学习策略主要有boosting和bagging两大类。本文要介绍的AdaBoost就是boosting的重要代表。 Boosting简介Boosting基本思想:通过改变训练数据的概率分布(训练数据的权值分布),学习多个弱分类器,并将它们线性组合,构成强分类器。Boosting算法要求基学习器能对特定的数据分布进行学习,这可通过“重赋权法”实施。对无法接受带权样本的基学习算法,则可通过“重采样法”来处理。 AdaBoost 1. 基本思路俗话说“三个臭皮匠,顶个诸葛亮”,AdaBoost算法就认为综合多个学习器得出的判断要比单独的学习器的判断要更可靠。那么它就要训练得到若干个不同的基学习器,再将它们进行组合。 这里有两个步骤:第一是训练基学习器,基学习器之间必须是不同的,要么是不同的模型,要么模型一样但是参数不一样。要不然一样的学习器只能得到一样的结果,对我们最终的判断没有任何助益。如果我们选用的基学习器都相同的话,那么就要对数据进行一定的操作 (重赋权or重采样) 使得训练得到不同的参数。AdaBoost 采用重赋权法,每训练出一个学习器后,改变样本的权值,使得被分类错误的样本拥有更大的权重,这样在下一轮的训练中将会更加关注这些错分样本,最终得到一个相对好的结果。第二步是基学习器的线性组合,AdaBoost采用加权多数表决,即分类误差率低的基学习器有更大的权重,进行线性组合。 2. 算法过程假设一个二分类训练数据集 T = { ( x 1 , y 1 ) , . . . , ( x N , y N ) } , y i ∈ { − 1 , + 1 } T=\{(x_1,y_1),...,(x_N,y_N)\},y_i\in\{-1,+1\} T={(x1,y1),...,(xN,yN)},yi∈{−1,+1}. (1)初始化权值分布 训练数据的权值分布,初始状态假设训练数据集具有均匀的权值分布,即每个训练样本在基分类器的学习中作用相同。 D 1 = ( w 11 , . . . , w 1 i , . . . , w 1 N ) , w 1 i = 1 N D_1=(w_{11},...,w_{1i},...,w_{1N}),\quad w_{1i}=\dfrac{1}{N} D1=(w11,...,w1i,...,w1N),w1i=N1 D代表数据权值分布,下标代表第几轮,因为后面还要进行很多轮学习,每次都会改变这个分布。w代标每个数据样本的权重,下标的第一个数字代表第几轮,和D的下标同步,第二个数字代表样本标号。 (2)对 m = 1 , 2 , . . . , M m=1,2,...,M m=1,2,...,M,进行以下步骤: ① 学习得到基本分类器 G m ( x ) G_m(x) Gm(x) 使用具有权值分布 D m D_m Dm的训练数据集进行学习,得到基本分类器 G m ( x ) G_m(x) Gm(x), G m ( x ) G_m(x) Gm(x)可以根据输入给出+1或-1的输出。 ② 计算 G m ( x ) G_m(x) Gm(x)的分类误差率 e m e_m em e m = ∑ i = 1 N P ( G m ( x i ) ≠ y i ) = ∑ i = 1 N e m i I ( G m ( x i ≠ y i ) e_m=\sum_{i=1}^NP(G_m(x_i)\neq y_i)=\sum_{i=1}^Ne_{mi}I(G_m(x_i\neq y_i) em=i=1∑NP(Gm(xi)=yi)=i=1∑NemiI(Gm(xi=yi) 其中, I I I 是指示函数,当后面括号里的式子成立就取1,不成立就取0。所以 e m e_m em 就是把所有分类错误的样本权重加起来,如果初始权重相等,那么5个样本分错2个,错误率就是0.4,如果权重是[0.5,0.1,0.1,0.1,0.1,0.1],而权重为0.5的样本分错了,最后错误率就是0.5。因此这个设计使得,将权重高的样本分类正确能显著降低分类误差率。 ③ 计算 G m ( x ) G_m(x) Gm(x)的系数 α m \alpha_m αm α m = 1 2 l o g 1 − e m e m \alpha_m=\dfrac{1}{2}log\dfrac{1-e_m}{e_m} αm=21logem1−em 其中 α m \alpha_m αm相当于基本分类器的权重,前面说误差率低的分类器要有较大的权重,我们这里先介绍 α m \alpha_m αm的这种形式能够实现我们的需求,后面会进一步介绍这是有严格的推导的,它为什么刚刚好就是这种形式。 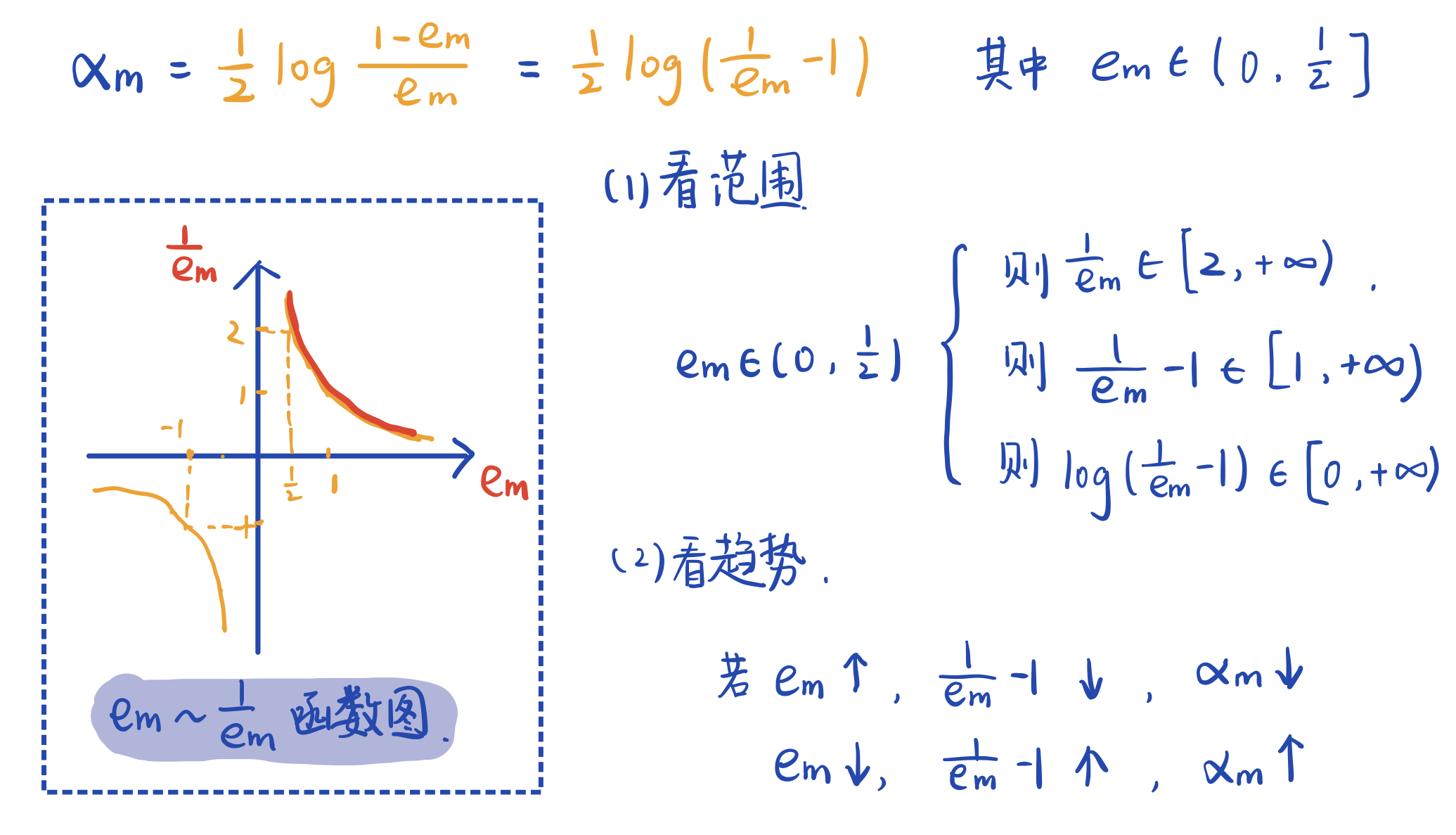
从上图不难看出, α m \alpha_m αm取值在0到正无穷,且 e m e_m em大的 α m \alpha_m αm小, e m e_m em小的 α m \alpha_m αm大,是符合我们的逻辑的。这里解释一下分类误差率 e m e_m em为什么小于等于1/2. 因为对于二分类问题,错误率超过0.5的话,只要进行简单的完全反转就可以使其降到0.5以下。举例来说,若 分类结果为 [1,1,1,-1] 错误率0.75,那么只要改成 [-1,-1,-1,1] 错误率就只有0.25了。(另一种想法是随机分类的错误率是0.5,弱学习器虽然弱,正确率也是要略高于随机分类的。 ④ 更新训练数据集的权值分布 D m + 1 = ( w m + 1 , 1 , . . . , w m + 1 , i , . . . , w m + 1 , N ) D_{m+1}=(w_{m+1,1},...,w_{m+1,i},...,w_{m+1,N}) Dm+1=(wm+1,1,...,wm+1,i,...,wm+1,N) w m + 1 , i = w w i Z m e x p ( − α m y i G m ( x i ) ) w_{m+1,i}=\dfrac{w_{wi}}{Z_m}exp(-\alpha_my_iG_m(x_i)) wm+1,i=Zmwwiexp(−αmyiGm(xi)) Z m = ∑ i = 1 N w m i e x p ( − α m y i G m ( x i ) ) Z_m=\sum_{i=1}^Nw_{mi}exp(-\alpha_my_iG_m(x_i)) Zm=i=1∑Nwmiexp(−αmyiGm(xi))这里的公式看起来很复杂,其实思想是很简单的,我们一步步看。首先, Z m Z_m Zm 是规范化因子,它将 w m + 1 , i w_{m+1,i} wm+1,i 映射到0~1的范围内,使之成为一个概率分布。 Z m Z_m Zm的值其实就是将所有的 w m + 1 , i w_{m+1,i} wm+1,i 进行求和。 然后再看 w m + 1 , i w_{m+1,i} wm+1,i ,我们就可以先忽略掉 Z m Z_m Zm 去理解。如果分类器 G m ( x ) G_m(x) Gm(x)将一个样本分类正确,说明要么真实值 y i y_i yi为1 预测结果 G m ( x i ) G_m(x_i) Gm(xi)也为1,要么真实为-1 预测也为-1,它们总是同号的,此时 y i G m ( x i ) = 1 y_iG_m(x_i)=1 yiGm(xi)=1,如果分类错误则 y i G m ( x i ) = − 1 y_iG_m(x_i)=-1 yiGm(xi)=−1.所以可以将原来的式子写成 (先忽略 Z m Z_m Zm) : w m + 1 , i = { w m i e − α m , G m ( x i ) = y i w m i e α m , G m ( x i ) ≠ y i w_{m+1,i}=\begin{cases} w_{mi}e^{-\alpha_m} & ,G_m(x_i)=y_i \\ \\ w_{mi}e^{\alpha_m}& ,G_m(x_i)\neq y_i \end{cases} wm+1,i=⎩⎪⎨⎪⎧wmie−αmwmieαm,Gm(xi)=yi,Gm(xi)=yi 可以看出,当分类正确,会在原来的权重基础上乘上 − α m -\alpha_m −αm , − α m -\alpha_m −αm是小于0的,于是权重被进一步缩小,而错分样本的权重会放大,且被放大了 e 2 α m = 1 − e m e m e^{2\alpha_m}=\dfrac{1-e_m}{e_m} e2αm=em1−em 倍。 (3) 得到最终分类器 G ( x ) G(x) G(x) f ( x ) = ∑ m = 1 M α m G m ( x ) f(x)=\sum_{m=1}^M\alpha_mG_m(x) f(x)=m=1∑MαmGm(x) G ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ m = 1 M α m G m ( x ) ) G(x)=sign(f(x))=sign\Big(\sum_{m=1}^M\alpha_mG_m(x)\Big) G(x)=sign(f(x))=sign(m=1∑MαmGm(x)) 其中, s i g n sign sign是符号函数,若括号内取值小于0则输出-1,大于0则输出1。对 M M M个基本分类器进行加权表决,系数 α m \alpha_m αm 表示了分类器的重要性,最终输出值的符号表示类别,绝对值代表了确信度。 算法描述到这里就结束了,总结一下就是:首先初始化权值分布,然后进入迭代,在每一轮中,依次计算分类器 G m ( x ) G_m(x) Gm(x),分类错误率 e m e_m em,系数 α m \alpha_m αm,并改变得到下一轮的权值分布 D m + 1 D_{m+1} Dm+1,当满足迭代停止条件则退出,对得到的若干基分类器进行加权求和,得到最终的分类器 G ( x ) G(x) G(x)。 3. 算法解释AdaBoost算法的另一种解释是,可以认为AdaBoost算法是模型为加法模型、损失函数为指数函数、学习算法为前向分步算法时的二分类学习方法。 下面分别解释加法模型、指数损失函数、前向分步算法。 3.1 加法模型f ( x ) = ∑ m = 1 M β m b ( x ; γ m ) f(x)=\sum_{m=1}^M\beta_mb(x;\gamma_m) f(x)=m=1∑Mβmb(x;γm)其中, b ( x ; γ m ) b(x;\gamma_m) b(x;γm)为基函数, γ m \gamma_m γm为基函数的参数, β m \beta_m βm为基函数的系数。显然,上面构建的基本分类器的线性组合 f ( x ) = ∑ m = 1 M α m G m ( x ) f(x)=\sum_{m=1}^M\alpha_mG_m(x) f(x)=∑m=1MαmGm(x) 是一个加法模型。 在给定训练数据和损失函数 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x))的条件下,学习加法模型 f ( x ) f(x) f(x)成为损失函数极小化问题: min β m , γ m ∑ i = 1 N L ( y i , ∑ m = 1 m β m b ( x i ; γ m ) ) \mathop{\min}\limits_{\beta_m,\gamma_m}\sum_{i=1}^NL\Big(y_i,\sum_{m=1}^ m \beta_mb(x_i;\gamma_m)\Big) βm,γmmini=1∑NL(yi,m=1∑mβmb(xi;γm))其含义是要求得最优的系数 β m \beta_m βm和参数 γ m \gamma_m γm使得损失函数最小,第一个求和号指对所有样本数据求和,第二个是对所有基分类器求和。 讨论:比较前向分步算法和梯度下降算法 这是一个复杂的优化问题,如果使用传统梯度下降,它要一次性优化2M个参数,复杂度很高。而前向分步算法求解的思想是:因为学习的是加法模型,如果能够从前向后,每一步只学习一个基函数机器系数,逐步逼近优化目标函数式,那么就可以简化优化的复杂度。 3.2 指数损失函数L ( y , f ( x ) ) = e x p [ − y f ( x ) ] L(y,f(x))=exp[-yf(x)] L(y,f(x))=exp[−yf(x)] 这是一般指数损失函数的表达式,也不用多做解释,根据前面的式子很容易看出来,只不过乘了一些系数和权重。 3.3 前向分步算法输入:训练数据集 T = { ( x 1 , y 1 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),...,(x_N,y_N)\} T={(x1,y1),...,(xN,yN)}; 损失函数 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x)); 基函数集 { b ( x ; γ ) } \{b(x;\gamma)\} {b(x;γ)} 输出:加法模型 f ( x ) f(x) f(x) (1)初始化 f 0 ( x ) = 0 ; f_0(x)=0; f0(x)=0; (2)对 m = 1 , 2 , . . . , M m=1,2,...,M m=1,2,...,M,依次进行: ① 极小化损失函数得到 β m , γ m \beta_m,\gamma_m βm,γm ( β m , γ m ) = arg min β , γ ∑ i = 1 N L ( y i , f m − 1 ( x i ) + β b ( x i ; γ ) ) (\beta_m,\gamma_m)=\mathop{\arg\min}\limits_{\beta,\gamma}\sum_{i=1}^NL(y_i,f_{m-1}(x_i)+\beta b(x_i;\gamma)) (βm,γm)=β,γargmini=1∑NL(yi,fm−1(xi)+βb(xi;γ))② 更新 f m ( x ) = f m − 1 ( x ) + β m b ( x ; γ m ) f_m(x)=f_{m-1}(x)+\beta_mb(x;\gamma_m) fm(x)=fm−1(x)+βmb(x;γm)(3)得到加法模型 f ( x ) = f M ( x ) = ∑ m = 1 M β m b ( x ; γ m ) f(x)=f_M(x)=\sum_{m=1}^M\beta_mb(x;\gamma_m) f(x)=fM(x)=∑m=1Mβmb(x;γm) 这样,前向分步算法将同时求解从m=1到M所有参数 β m , γ m \beta_m,\gamma_m βm,γm的优化问题简化为主次求解各个 β m , γ m \beta_m,\gamma_m βm,γm的问题。可以看出AdaBoost是前向分步算法的特例,其基函数是基本分类器,损失函数是指数损失函数。 3.4 推导证明现在我们要进行推导证明,用基函数是基本分类器、损失函数是指数损失函数的前向分步算法对 α m , G m ( x ) \alpha_m,G_m(x) αm,Gm(x)进行优化,求得的结果就是我们上面介绍AdaBoost时给出的形式。 第 m 轮迭代得到 α m , G m ( x ) , f m ( x ) \alpha_m,G_m(x),f_m(x) αm,Gm(x),fm(x),而 f m ( x ) = f m − 1 ( x ) + α m G m ( x ) f_m(x)=f_{m-1}(x)+\alpha_mG_m(x) fm(x)=fm−1(x)+αmGm(x) 这是容易理解的,第m轮的 f m ( x ) f_m(x) fm(x)是【新得到的分类器 G m ( x ) G_m(x) Gm(x)】 加上前【m-1轮分类器累加得到的 f m − 1 ( x ) f_{m-1}(x) fm−1(x)】 目标是使前向分步算法得到的 α m \alpha_m αm 和 G m ( x ) G_m(x) Gm(x) 使 f m ( x ) f_m(x) fm(x) 在训练集上的指数损失最小,即 ( α m , G m ( x ) ) = arg min α , G ∑ i = 1 N e x p [ − y i ( f m − 1 ( x i ) + α G ( x i ) ) ] = arg min α , G ∑ i = 1 N e x p [ − y i ( f m − 1 ( x i ) ] e x p [ − y i α G ( x i ) ] = arg min α , G ∑ i = 1 N w ‾ m i e x p [ − y i α G ( x i ) ] \begin{aligned}(\alpha_m,G_m(x)) &=\mathop{\arg\min}\limits_{\alpha,G}\sum_{i=1}^Nexp[-y_i(f_{m-1}(x_i)+\alpha G(x_i))] \\&=\mathop{\arg\min}\limits_{\alpha,G}\sum_{i=1}^Nexp[-y_i(f_{m-1}(x_i)]exp[-y_i\alpha G(x_i)]\\&=\mathop{\arg\min}\limits_{\alpha,G}\sum_{i=1}^N\overline{w}_{mi}exp[-y_i\alpha G(x_i)]\end{aligned} (αm,Gm(x))=α,Gargmini=1∑Nexp[−yi(fm−1(xi)+αG(xi))]=α,Gargmini=1∑Nexp[−yi(fm−1(xi)]exp[−yiαG(xi)]=α,Gargmini=1∑Nwmiexp[−yiαG(xi)] 其中, w ‾ m i = e x p [ − y i f m − 1 ( x i ) ] \overline{w}_{mi}=exp[-y_if_{m-1}(x_i)] wmi=exp[−yifm−1(xi)],第一个式子到第二个式子就是把指数部分拆开。现在要证明使这个式子达到最小的 α m ∗ , G m ∗ ( x ) \alpha_m^*,G_m^*(x) αm∗,Gm∗(x)就是AdaBoost算法得到的 α m , G m ( x ) \alpha_m,G_m(x) αm,Gm(x). 3.4.1 优化 G m ( x ) G_m(x) Gm(x)G m ∗ ( x ) = arg min G ∑ i = 1 N w ‾ m i I ( y i ≠ G ( x i ) ) G_m^*(x)=\mathop{\arg\min}\limits_{G}\sum_{i=1}^N\overline{w}_{mi}I(y_i\neq G(x_i)) Gm∗(x)=Gargmini=1∑NwmiI(yi=G(xi)) 使右边式子值最小的G就是我们要求的最优G*,但是我们知道AdaBoost算法的基本分类器 G m ( x ) G_m(x) Gm(x)使第m轮加权训练数据分类误差率最小,而第m轮加权训练数据分类误差率就是求和号及其后面的部分。所以,此处 G m ∗ ( x ) G_m^*(x) Gm∗(x)也就是AdaBoost算法得到的 G m ( x ) G_m(x) Gm(x). 3.4.2 优化 α m \alpha_m αm损失函数对 α m \alpha_m αm 求导,令导数为0,得到的 α m \alpha_m αm 即为所求。 先对上面经过一定变形的损失函数进行进一步变换,由于 − y i G ( x i ) -y_iG(x_i) −yiG(xi)有两种取值,我们可以将其拆开: ∑ i = 1 N w ‾ m i e x p [ − y i α m G ( x i ) ] = ∑ y i = G m ( x i ) w ‾ m i e − α m + ∑ y i ≠ G m ( x i ) w ‾ m i e α m = e − α m ∑ y i = G m ( x i ) w ‾ m i + e α m ∑ y i ≠ G m ( x i ) w ‾ m i = ( e − α m ∑ y i = G m ( x i ) w ‾ m i + e − α m ∑ y i ≠ G m ( x i ) w ‾ m i ) + ( e α m ∑ y i ≠ G m ( x i ) w ‾ m i + e − α m ∑ y i ≠ G m ( x i ) w ‾ m i ) \begin{aligned}\sum_{i=1}^N\overline{w}_{mi}exp[-y_i\alpha_m G(x_i)]&=\sum_{y_i= G_m(x_i)}\overline{w}_{mi}e^{-\alpha_m}+\sum_{y_i\neq G_m(x_i)}\overline{w}_{mi}e^{\alpha_m}\\&=e^{-\alpha_m}\sum_{y_i= G_m(x_i)}\overline{w}_{mi}+e^{\alpha_m}\sum_{y_i\neq G_m(x_i)}\overline{w}_{mi}\\ &=\Big(e^{-\alpha_m}\sum_{y_i= G_m(x_i)}\overline{w}_{mi}+e^{-\alpha_m}\sum_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big)+\Big(e^{\alpha_m}\sum_{y_i\neq G_m(x_i)}\overline{w}_{mi}+e^{-\alpha_m}\sum_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big)\end{aligned} i=1∑Nwmiexp[−yiαmG(xi)]=yi=Gm(xi)∑wmie−αm+yi=Gm(xi)∑wmieαm=e−αmyi=Gm(xi)∑wmi+eαmyi=Gm(xi)∑wmi=(e−αmyi=Gm(xi)∑wmi+e−αmyi=Gm(xi)∑wmi)+(eαmyi=Gm(xi)∑wmi+e−αmyi=Gm(xi)∑wmi) 第二个等号就是将 e α m , e − α m e^{\alpha_m},e^{-\alpha_m} eαm,e−αm提到求和号前面,第三个等号是加上并减去 e − α m ∑ y i ≠ G m ( x i ) w ‾ m i e^{-\alpha_m}\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi} e−αmyi=Gm(xi)∑wmi 分别和原来的两项组合。第一个大括号内变成 e − α m ∑ i = 1 N w ‾ m i e^{-\alpha_m}\sum\limits_{i=1}^N\overline{w}_{mi} e−αmi=1∑Nwmi,第二个大括号内变成 ( e α m − e − α m ) ∑ y i ≠ G m ( x i ) w ‾ m i (e^{\alpha_m}-e^{-\alpha_m})\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi} (eαm−e−αm)yi=Gm(xi)∑wmi 整理一下就得到: α m ∗ = arg min α m ( e − α m ∑ i = 1 N w ‾ m i + ( e α m − e − α m ) ∑ y i ≠ G m ( x i ) w ‾ m i ) \alpha_m^*=\mathop{\arg\min}\limits_{\alpha_m}\Big( e^{-\alpha_m}\sum\limits_{i=1}^N\overline{w}_{mi}+(e^{\alpha_m}-e^{-\alpha_m})\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big) αm∗=αmargmin(e−αmi=1∑Nwmi+(eαm−e−αm)yi=Gm(xi)∑wmi) 求偏导并令求导结果为0: ∂ L ∂ α m = − e − α m ∑ i = 1 N w ‾ m i + ( e α m + e − α m ) ∑ y i ≠ G m ( x i ) w ‾ m i = − e − α m ∑ y i = G m ( x i ) w ‾ m i + e α m ∑ y i ≠ G m ( x i ) w ‾ m i = 0 \begin{aligned}\dfrac{\partial L}{\partial\alpha_m}&=-e^{-\alpha_m}\sum\limits_{i=1}^N\overline{w}_{mi}+(e^{\alpha_m}+e^{-\alpha_m})\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\\&=-e^{-\alpha_m}\sum\limits_{y_i=G_m(x_i)}\overline{w}_{mi}+e^{\alpha_m}\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\\&=0\end{aligned} ∂αm∂L=−e−αmi=1∑Nwmi+(eαm+e−αm)yi=Gm(xi)∑wmi=−e−αmyi=Gm(xi)∑wmi+eαmyi=Gm(xi)∑wmi=0 也就得到一个等式关系,并在等式两边取对数: l n ( − e − α m ∑ y i = G m ( x i ) w ‾ m i ) = l n ( e α m ∑ y i ≠ G m ( x i ) w ‾ m i ) − α m + l n ( ∑ y i = G m ( x i ) w ‾ m i ) = α m + l n ( ∑ y i ≠ G m ( x i ) w ‾ m i ) 2 α m = l n ( ∑ y i = G m ( x i ) w ‾ m i ) − l n ( ∑ y i ≠ G m ( x i ) w ‾ m i ) α m = 1 2 l n ( ∑ y i = G m ( x i ) w ‾ m i ∑ y i ≠ G m ( x i ) w ‾ m i ) \begin{aligned} ln\Big(-e^{-\alpha_m}\sum\limits_{y_i=G_m(x_i)}\overline{w}_{mi}\Big)&=ln\Big(e^{\alpha_m}\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big)\\-\alpha_m+ln\Big(\sum\limits_{y_i=G_m(x_i)}\overline{w}_{mi}\Big)&=\alpha_m+ln\Big(\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big)\\2\alpha_m &=ln\Big(\sum\limits_{y_i=G_m(x_i)}\overline{w}_{mi}\Big)-ln\Big(\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}\Big)\\\alpha_m&=\dfrac{1}{2}ln\Bigg(\dfrac{\sum\limits_{y_i=G_m(x_i)}\overline{w}_{mi}}{\sum\limits_{y_i\neq G_m(x_i)}\overline{w}_{mi}}\Bigg)\end{aligned} ln(−e−αmyi=Gm(xi)∑wmi)−αm+ln(yi=Gm(xi)∑wmi)2αmαm=ln(eαmyi=Gm(xi)∑wmi)=αm+ln(yi=Gm(xi)∑wmi)=ln(yi=Gm(xi)∑wmi)−ln(yi=Gm(xi)∑wmi)=21ln(yi=Gm(xi)∑wmiyi=Gm(xi)∑wmi) 而此处,对数里面的分母就是分类误差率 e m e_m em,就得到上面的结果 α m = 1 2 l o g 1 − e m e m \alpha_m=\dfrac{1}{2}log\dfrac{1-e_m}{e_m} αm=21logem1−em 最后最后,我们知道在AdaBoost中计算了 α m \alpha_m αm后面就要更新权值 w w w,因为 w ‾ m i = e x p [ − y i f m − 1 ( x i ) ] \overline{w}_{mi}=exp[-y_if_{m-1}(x_i)] wmi=exp[−yifm−1(xi)],所以: w ‾ m + 1 , i = e x p [ − y i f m ( x i ) ] = e x p [ − y i ( f m − 1 ( x ) + α m G m ( x ) ) ] = e x p [ − y i f m − 1 ( x i ) ] e x p [ − y i α m G m ( x ) ] = w ‾ m i e x p [ − y i α m G m ( x ) ] \begin{aligned}\overline{w}_{m+1,i}&=exp[-y_if_{m}(x_i)]\\&=exp[-y_i\Big(f_{m-1}(x)+\alpha_mG_m(x)\Big)]\\&=exp[-y_if_{m-1}(x_i)]exp[-y_i\alpha_mG_m(x)]\\&=\overline{w}_{mi}exp[-y_i\alpha_mG_m(x)]\end{aligned} wm+1,i=exp[−yifm(xi)]=exp[−yi(fm−1(x)+αmGm(x))]=exp[−yifm−1(xi)]exp[−yiαmGm(x)]=wmiexp[−yiαmGm(x)] 和AdaBoost中的结果也是一样的,除了没进行规范化之外。顺带一提, w ‾ m i = e x p [ − y i f m − 1 ( x i ) ] \overline{w}_{mi}=exp[-y_if_{m-1}(x_i)] wmi=exp[−yifm−1(xi)]也表达了AdaBoost将损失函数视为训练数据权值的思想。 |
【本文地址】