| 几种常用的聚类算法及评价方法 | 您所在的位置:网站首页 › 聚类常见算法有哪些 › 几种常用的聚类算法及评价方法 |
几种常用的聚类算法及评价方法
|
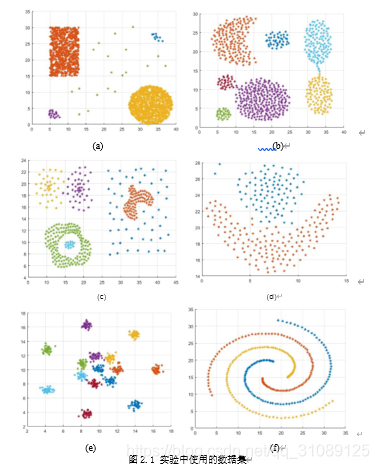
本文分析了Kmeans、Kmedoids、Cure、Birch、DBSCAN、OPTICS、Clique、DPC算法。 除了Birch聚类算法的python算法调用了sklearn.cluster里的Birch函数,没有未搜到Clique聚类的matlab版本的算法。其余算法python和matlab算法都是根据原理所编。喜欢的给个star~喔。github项目 2.聚类算法实际类别数据集如图2.1所示。 1.确定类别N的值 2.随机从数据集{X_1,X_2,…,X_n}中选择N个数据作为数据中心点,记N_1,N_2,…,N_m 开始迭代: 3.将某个数据分别和N_1,N_2,…,N_n进行距离比较,选出距离最近的将此数据归入此类别的族中,继续分类其他的数据 4.重新确定N个族中心,采用里面各个类别中所有的数据进行x和y轴的平均值的那个点(重心),作为族中心。 5.迭代到合适的时候终止迭代(从代码上来看,每个族中心点和新的族中心点距离小于0.1时即可终止迭代)。 缺点:①类别要人为确定 ②族中心点的迭代选择存在风险 2.1.2.Kmeans聚类算法预测结果可视化 经过不断地运行,得到准确率较高的分类,如图2.2所示。 图2.2 Keams预测分类图 2.1.3 评估指标
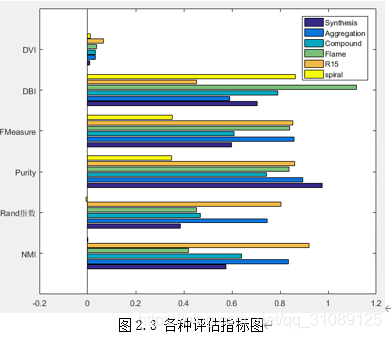
图2.3 各种评估指标图 2.2 .Kmedoids聚类算法 2.2.1.Kmedoids聚类算法相当于Kmeans聚类算法的改进,其改进了迭代中簇中心的选择,从而提高了分 类的准确性。 1.确定类别N的值 2.随机从数据集{X_1,X_2,…,X_n}中选择N个数据作为数据中心点,记 N_1,N_2,…,N_m,并去除数据集中随机抽取到的那个数据,即目前数据个数为 n-m 3.将每个类别中某个数据分别和N_1,N_2,…,N_n进行距离比较,选出距离最近的将此数据归入此类别的族中,继续分类其他的数据 开始迭代 4.在每个类别中随机产生一个待定的族中心,计算其他数据到此待定族中心的距离总和o_rand_sum和其他数据点到原族中心的距离总和o_sum。若o_rand_sum |
【本文地址】