| 美股软件系列①:Snowflake(深度长文还原最真实的Snowflake产品使用体验) #雪球星计划# 2020年,美国市场迎来了有史以来规模最大的一次软件公司IPO,#snowflake# 登上神坛,受到投... | 您所在的位置:网站首页 › 美股fb是什么意思 › 美股软件系列①:Snowflake(深度长文还原最真实的Snowflake产品使用体验) #雪球星计划# 2020年,美国市场迎来了有史以来规模最大的一次软件公司IPO,#snowflake# 登上神坛,受到投... |
美股软件系列①:Snowflake(深度长文还原最真实的Snowflake产品使用体验) #雪球星计划# 2020年,美国市场迎来了有史以来规模最大的一次软件公司IPO,#snowflake# 登上神坛,受到投...
|
来源:雪球App,作者: 美股大白话,(https://xueqiu.com/4079974780/287575943) #雪球星计划# 2020年,美国市场迎来了有史以来规模最大的一次软件公司IPO,#snowflake# 登上神坛,受到投资人的热烈追捧,股神巴菲特也参与了打新,这也是一向对科技股态度冷淡的老爷子五十多年来的首次。
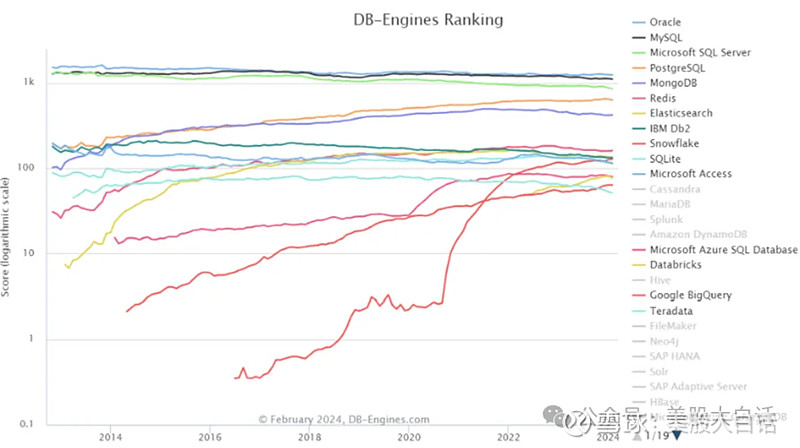
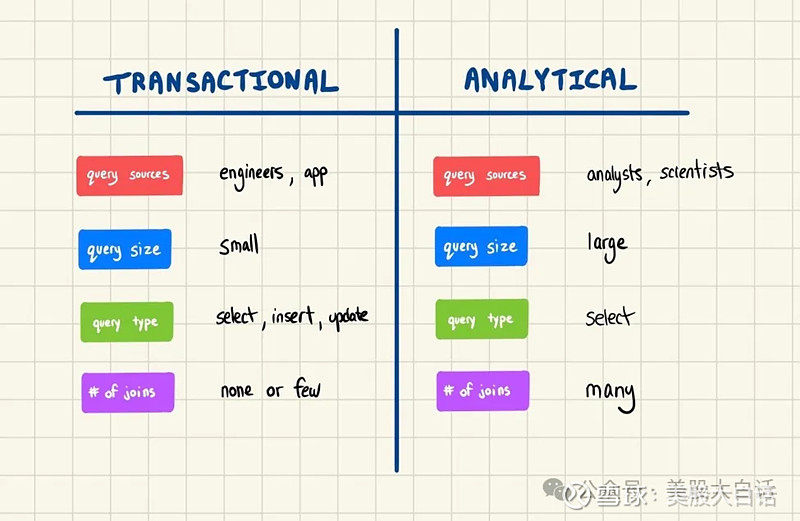
然而时隔4年,经历了美国企业IT开支优化、AI新锐Databricks竞争、更换CEO等多重事件影响,大家开始对Snowflake内忧外患的前景忧心忡忡,雪花真的要融化了吗? 今天,作为美股软件探秘系列的开篇,让我们先来好好聊聊Snowflake的核心产品和真实的使用体验。 01 什么是数据仓库?Snowflake是什么? 一个云数据仓库,数据团队使用它来存储和查询他们的分析数据。 让我们首先来回顾一下#数据库# 数据仓库的定义。 数据仓库是专门设计的数据库,用于保存分析数据。它旨在处理由数据科学家、分析师和机器学习工程师编写的长而复杂的查询。 事务型数据库与分析型数据库 数据库分为两种类型:事务型数据库(OLTP)和分析型数据库(OLAP)。 例如,PostgreSQL就是为添加、更新和删除数据而构建的事务性数据库,而分析数据库则用于复杂的查询和连接。事务性数据库通过ETL(Extract-Transform-Load,提取、转化、加载)的过程转化为分析型数据库。
数据仓库就是一组为了分析场景而非事务场景而构建的数据库,特点是: 数据仓库将多个来源的数据汇集到一处; 与事务性数据通常直接和应用程序链接,数据仓库很少与应用程序直接交互,它们主要由数据分析师和数据科学家使用; 数据仓库中存储的数据量通常比事务数据库多得多。 举个例子: 假设一个商家在电商上销售运动鞋,用户可以在该网站上创建并登录帐户。他有一个事务性的记录产品制造和商品交易的数据库,其中包含有关的用户信息以及有关付款和订单的 支付系统数据。 这时候,商家如果想构建一个直观的数据界面来统计每月从南美洲的用户那里赚了多少钱,他需要: 1. 清理用户数据,以确保像“Soth America”这样的拼写错误得以纠正; 2. 将用户数据和 支付系统数据(比如Stripe)汇总在一起以便筛选南美洲的用户; 3. 定期(比如每天)运行一次查询动作(query)以最终计算每月的收入,并将其存储在数据仓库的表格中。 最终我们就得到了一个新的数据集,包含我们需要的处理过的数据,并存储在数据仓库中。而我们刚刚的过程就是所谓的ETL,就是从系统中取出数据、对其进行处理,然后将其放入仓库的方式。 数据仓库最令人困惑的部分在于大部人不理解它到底是什么。 答案是数据仓库其实包含以下两个方面: 1. 一个存储数据的不同位置(单独的数据库服务器) 2. 一个存储数据的不同方式(新的数据源、结构等) 大多数拥有数据团队的公司至少有两个独立的数据处理位置:生产数据库和数据仓库。生产数据库仅包含与其应用程序核心操作相关的数据(用户、业务等)。另一方面,数据仓库可能拥有生产数据、支付数据、网站流量数据和许多其他数据的副本,只要是数据团队想要分析的数据,都可以存一份副本在数据仓库中。 02 数据仓库演变和云原生数仓数据仓库有着悠久的历史,而且技术水平一直在不断变化。在很长一段时间里,企业的数据团队直接在为生产数据库提供支持的同一个数据库软件(例如 PostgreSQL)之上直接运行数据仓库。而过去10年,大数据时代的产物Hadoop生态系统风靡一时(这个如果大家感兴趣可以留言,我单独再开一个专题讲Hadoop)。 如今,大多数初创公司(以及越来越大的公司)都在使用云原生、完全托管的数据仓库,典型代表就是Snowflake 或Google BigQuery等产品。 云原生数据库的特点: 1. 完全托管的基础设施(客户不需要自己管理服务器、考虑自动扩展等) 2. 按实际使用量的付费模式:通常按存储数据量和查询量收费 3. 基于浏览器的十分易用的用户界面,用于管理权限和数据 就这样,云原生数据仓库逐渐占据了绝大部分的市场,也奠定了Snowflake的地位。 03 Snowflake核心产品:存储和计算从本质上讲,Snowflake 只是一个数据仓库即服务(data warehouse as a service),市面上也有很多类似的服务(比如 BigQuery、Redshift等),而Snowflake 提供的“产品”实际上只是一个存储分析型数据,并提供查询服务的地方。以下是公司官网对产品的介绍:
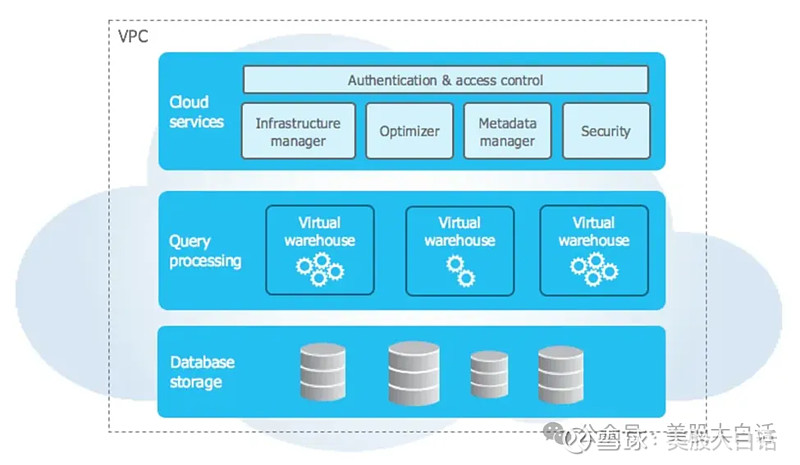
存算分离 谈到Snowflake必然离不开存算分离,云原生数据仓库的主要创新之一就是存储和计算的分离。回想一下前文所提到的,数据仓库的独特之处在于它是为大量、复杂、耗时长的查询任务而构建的。因此,如果可以让这些查询在它们自己的服务器上运行,计算的服务器与存储数据的服务器分开,就可以大大提高处理性能。 具体到 Snowflake 中,存算分离是这样实现的: 存储:Snowflake 负责数据存储的方式:帮助企业优化数据、压缩数据、处理元数据等,所有这些处理都由Snowflake负责在幕后进行; 计算:Snowflake 允许企业创建任意数量的“虚拟仓库”来运行查询任务。 Snowflake 中的“虚拟仓库”基本上是用于运行分析查询的专用服务器。企业用户可以直接在 Snowflake的使用界面中直观、简单地创建和配置任意数量的“虚拟仓库”:
这样存算分离的方式允许 Snowflake : 在后台优化数据存储方式,不用将完整的数据呈现给客户,对Snowflake来说更便宜,而对企业用户来说操作更快; 可无限扩展的查询所需的计算资源。需要运行巨大的海量查询时,只需创建一个或两个新的虚拟仓库;当不再需要它们的时候,随时关闭即可; 分离单个查询任务,以便耗时长的查询任务不会影响其他正在运行的查询任务。 04 如何访问Snowflake中的数据Snowflake 为企业提供多种不同方式查询和访问存储在其系统中的数据。 1)通过Snowflake用户界面 Snowflake 有一个 Web 端的用户界面,用户可以直接通过浏览器访问该界面。此外,它还允许创建工作表,可以在其中针对仓库编写 SQL语言。 2)通过Snowflake Python SDK 如果数据团队需要使用 Python 进行数据分析,则可以通过Python SDK直接访问存储在Snowflake中的数据。这个功能和大多数编程语言的数据库包装器一样,主要就是一些用于身份验证的函数,然后执行查询函数。一个简单查询的示例如下:
3)通过指令行界面( SnowSQL ) 尽管这在技术上显然是建立在 Snowflake Python SDK之上的,但SnowSQL是 Snowflake 的命令行界面 (CLI),用于与 Snowflake 数据进行交互。如果想使用终端编写查询任务,就可以使用如下指令。
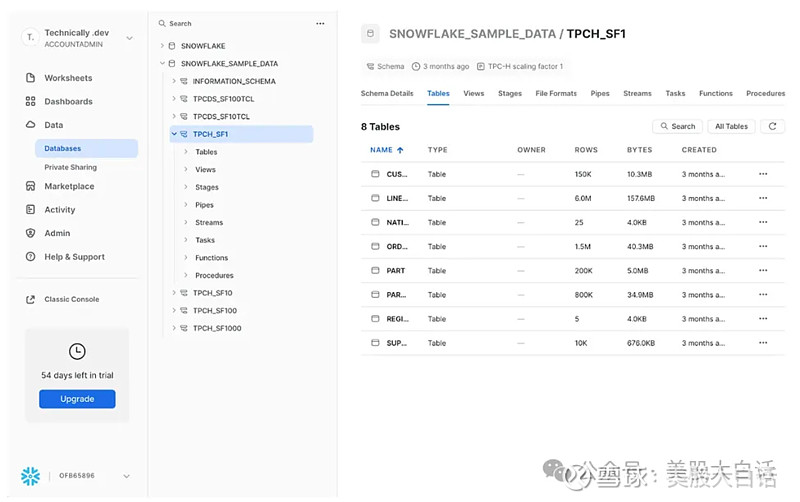
4) 其他连接器和驱动器 除了 Python 连接器之外,Snowflake 还提供了 JavaScript、Go、.NET、PHP、Java 等其他连接器,主要是针对用户在可能需要使用更注重应用程序的语言来访问 Snowflake 数据的场景。 05 Snowflake的用户界面:Snowsight在这里将这个使用界面单独作为一节分析,是因为与传统的数据仓库相比,Snowflake 最优秀的特点就是是Web 界面丰富、强大且易用的功能。用户可以直接从从snowflake.com登录帐户并执行许多操作,比如: 可以查看数据,具体到特定的表和列:
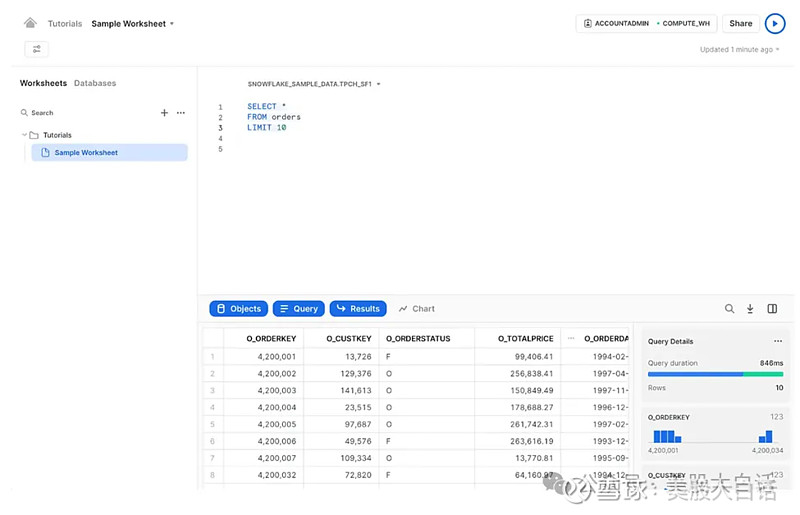
可以在Snowflake Worksheet功能中编写 SQL 查询:
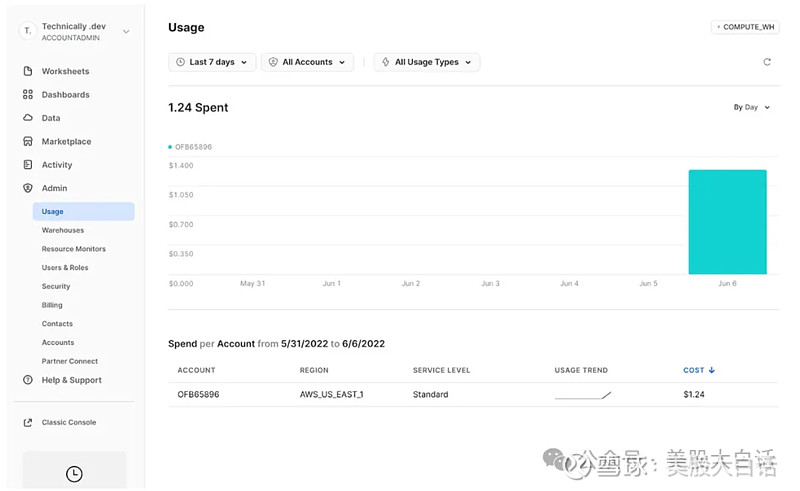
查看和调整管理信息设置(例如分析数据库资源的使用情况):
Snowflake 一直致力于开发的、更有意思的功能就是他们的数据市场。Snowflake的用户可以在这里找到有趣、有用的数据集,并将这些数据集上传到他们的 Snowflake 数据仓库。 Snowflake数据市场上基本上有两种类型的数据: 公开、免费的数据集:比如查找表(查找不同地区的邮政编码等)、公共医疗数据、天气数据等类似的公开数据。 与其他工具的专有连接数据:例如与Hubspot(CRM系统)和Mixpanel(网页、应用端用户数据系统)打通。 尤其是这里的第二类数据集非常有意思。 再举个例子。 如果一个公司本身使用了Hubspot之类的CRM系统,他们会将自己的营销数据存储在其内部数据库中,但通过数据市场将其与 Snowflake 连接就可以在企业的snowflake数据仓库中生成该业务数据库的部分副本,且无需额外的配置工作。
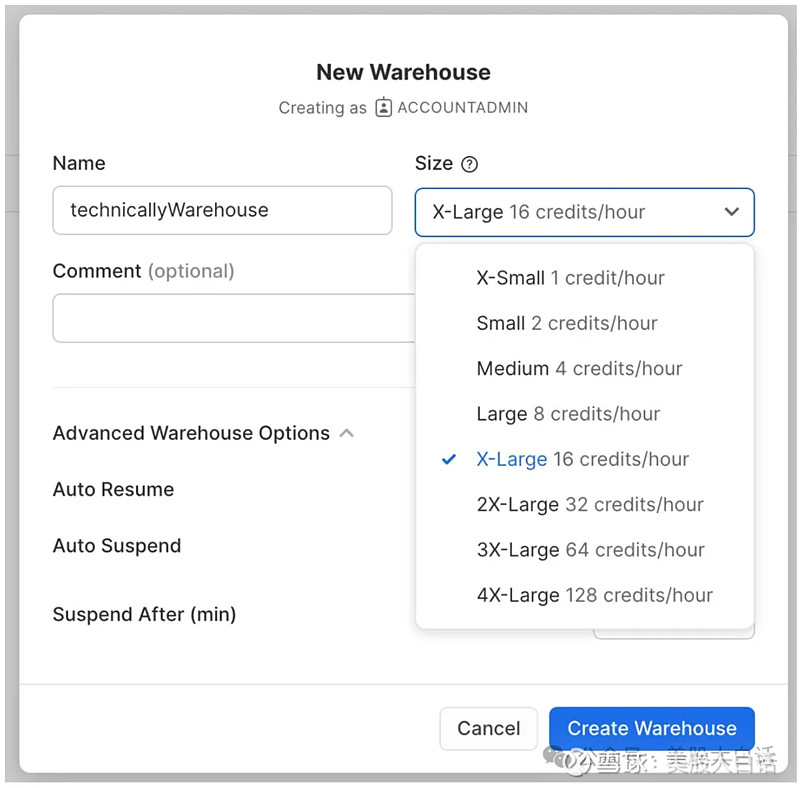
从理论上讲,云数据仓库的巨大好处之一是企业只需为实际使用的内容付费,而不必在服务器上花费数百万美元的固定成本。 但Snowflake 的收费方式其实并不是那么直观,而是通过Credit 的单位收费,如下图:
Snowflake 中的每项资源(无论是存储数据、查询数据还是使用其周围的云服务)都会以每小时的积分来计算成本。例如,如果企业用户设置了一个“虚拟仓库”来查询数据(上文提示:这就是 Snowflake 所说的用于计算的服务器),并且选择“X-Small”大小,则每小时将花费 1 个积分。如果企业使用的是标准计划,则为 2 美元/小时。 但针对Snowflake的credit模式其实一直以来存在一些争议。有些人希望 Snowflake 直接收取正在使用的资源费用,并以自己特定的方式为每个资源定价,而不是搞这种弯弯绕。 总结Snowflake的核心创新在于实现了存储与计算的分离,克服了传统数据仓库架构中,由于存储和计算紧密耦合导致在节点关系变化和升级时容易产生的各种问题,做到了真正的“弹性”拓展,从而大幅提高并发查询性能,将原本复杂的数据处理分析任务的操作变得简单、直观。 但相应的交换条件是企业用户对于每个“虚拟仓库”背后使用的硬件资源、操作系统和网络配置等的控制能力是减弱的,同时也需要为Snowflake平台的易用性而付出高于传统云厂商的存储和计算代价。 下期预告从企业部署本地大模型的工作流角度,探讨Snowflake AI系列新产品Snowpark和Cortex到底是什么。 欢迎关注、收藏、点赞、转发~ |





【本文地址】