| [图神经网络] 图节点Node表示 | 您所在的位置:网站首页 › 网站节点是什么意思 › [图神经网络] 图节点Node表示 |
[图神经网络] 图节点Node表示
|
一 前言
在大规模图上学习节点embedding,在很多任务中非常有效,如学习节点拓扑结构的 DeepWalk 以及同时学习邻居特征和拓扑结构的semi-GCN。 但是现在大多数方法都是直推式学习, 不能直接泛化到未知节点。这些方法是在一个固定的图上直接学习每个节点embedding,但是大多情况图是会演化的,当网络结构改变以及新节点的出现,直推式学习需要重新训练(复杂度高且可能会导致embedding会偏移),很难落地在需要快速生成未知节点embedding的机器学习系统上。 直推式(transductive)学习:从特殊到特殊,仅考虑当前数据。在图中学习目标是学习目标是直接生成当前节点的embedding,例如DeepWalk、LINE,把每个节点embedding作为参数,并通过SGD优化,又如GCN,在训练过程中使用图的拉普拉斯矩阵进行计算,归纳(inductive)学习:平时所说的一般的机器学习任务,从特殊到一般:目标是在未知数据上也有区分性。 GraphSAGE(Graph SAmple and aggreGatE)框架,通过训练聚合节点邻居的函数(卷积层),使GCN扩展成归纳学习任务,对未知节点起到泛化作用。 二 GraphSage 原理可视化例子:下图是GraphSAGE 生成目标节点(红色)embededing并供下游任务预测的过程
1. 先对邻居随机采样,降低计算复杂度(图中一跳邻居采样数=3,二跳邻居采样数=5) 采样的阶段首先选取一个点,然后随机选取这个点的一阶邻居,再以这些邻居为起点随机选择它们的一阶邻居。例如下图中,我们要预测 0 号节点,因此首先随机选择 0 号节点的一阶邻居 2、4、5,然后随机选择 2 号节点的一阶邻居 8、9;4 号节点的一阶邻居 11、12;5 号节点的一阶邻居 13、15
2. 生成目标节点emebedding 先聚合2跳邻居特征,生成一跳邻居embedding,再聚合一跳邻居embedding,生成目标节点embedding,从而获得二跳邻居信息。(后面具体会讲)。 聚合具体来说就是直接将子图从全图中抽离出来,从最边缘的节点开始,一层一层向里更新节点
下图展示了邻居采样的优点,极大减少训练计算量这个是毋庸置疑的,泛化能力增强这个可能不太好理解,因为原本要更新一个节点需要它周围的所有邻居,而通过邻居采样之后,每个节点就不是由所有的邻居来更新它,而是部分邻居节点,所以具有比较强的泛化能力
算法过程:
外循环表示更新迭代次数,h^k_v表示更新迭代时节点v的隐向量k。在每次更新迭代中,根据一个聚集函数、前一次迭代中v和v邻域的隐向量以及权矩阵W^k对h^k_v进行更新。 首先,(line1)算法首先初始化输入的图中所有节点的特征向量,(line3)对于每个节点v ,拿到它采样后的邻居节点N(v)后,(line4)利用聚合函数聚合邻居节点的信息,(line5)并结合自身embedding通过一个非线性变换更新自身的embedding表示。注意到算法里面的K ,它是指聚合器的数量,也是指权重矩阵的数量,还是网络的层数,这是因为每一层网络中聚合器和权重矩阵是共享的 网络的层数可以理解为需要最大访问的邻居的跳数(hops),比如在上图中,红色节点的更新拿到了它一、二跳邻居的信息,那么网络层数就是2。为了更新红色节点,首先在第一层(k=1),我们会将蓝色节点的信息聚合到红色解节点上,将绿色节点的信息聚合到蓝色节点上。在第二层(k=2)红色节点的embedding被再次更新,不过这次用到的是更新后的蓝色节点embedding,这样就保证了红色节点更新后的embedding包括蓝色和绿色节点的信息,也就是两跳信息。 邻居的定义: 作者的做法是设置一个定值,每次选择邻居的时候就是从周围的直接邻居(一阶邻居)中均匀地采样固定个数个邻居。 那我就有一个疑问了?每次都只是从其一阶邻居聚合信息,为何作者说:随着迭代,可以聚合越来越远距离的信息呢? 后来我想了想,发现确实是这样的。虽然在聚合时仅仅聚合了一个节点邻居的信息,但该节点的邻居,也聚合了其邻居的信息,这样,在下一次聚合时,该节点就会接收到其邻居的邻居的信息,也就是聚合到了二阶邻居的信息。
其中feature_dim表示顶点属性特征向量的维度,neighbor_num是一个list表示每一层抽样的邻居顶点的数量,n_hidden为聚合函数内部非线性变换时的参数矩阵的维度,n_classes表示预测的类别的数量,aggregator_type为使用的聚合函数的类别。 三 GraphSage的聚合我们将更新某个节点的过程展开来看,如下图分别为更新节点A和更新节点B的过程,可以看到更新不同的节点过程每一层网络中聚合器和权重矩阵都是共享的。
特征聚合是指各节点自身特征和采样出的邻居节点的特征进行聚合,聚合操作类似CNN里的Pooling,可以选择Mean、Max等方式。聚合后的特征向量经过一个全连接层,迭代生成各节点的新特征。 那么GraphSAGE Sample是怎么做的呢?GraphSAGE是采用定长抽样的方法,具体来说,定义需要的邻居个数S ,然后采用有放回的重采样/负采样方法达到 。保证每个节点(采样后的)邻居个数一致,这样是为了把多个节点以及它们的邻居拼接成Tensor送到GPU中进行批训练。 聚合函数 1. 平均聚合器 Mean aggregator 先对邻居embedding中每个维度取平均(原始第4,5行),然后与目标节点embedding拼接后进行非线性转换。
改进版的平均聚合是采用GCN的卷积层方法(GCN的归纳式学习版本),直接对目标节点和所有邻居embedding中每个维度取平均,后再非线性转换。
上式对应于伪代码中的第4-5行,直接产生顶点的向量表示,而不是邻居顶点的向量表示。 mean aggregator将目标顶点和邻居顶点的第k-1层向量拼接起来,然后对向量的每个维度进行求均值的操作,将得到的结果做一次非线性变换产生目标顶点的第k层表示向量。 与原始方程相比,它删除了上面伪代码第5行中的连接操作。这种操作可以看作是一种“跳跃连接”,本文稍后的部分证明了这种连接在很大程度上提高了模型的性能。 举个简单例子,比如一个节点的3个邻居的embedding分别为[1,2,3,4],[2,3,4,5],[3,4,5,6]按照每一维分别求均值就得到了聚合后的邻居embedding为[2,3,4,5] 2. 池化聚合器 Pooling aggregator: 这个操作符在相邻的集合上执行一个元素池化函数。下面是最大池化的例子:
先对目标顶点的邻接点表示向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将得到结果与目标顶点的表示向量拼接,最后再经过一次非线性变换得到目标顶点的第k层表示向量。可以用均值池化或任何其他对称池化函数替换。池化聚合器性能最好,而均值池化聚合器和最大池化聚合器性能相近。本文使用max-pooling作为默认的聚合函数。
3. LSTM聚合器 LSTM aggregator: 由于图中的节点没有任何顺序,将中心节点的邻居节点随机打乱作为输入序列。与平均聚合相比,LSTM聚合具有更大的表达能力。但是,重要的是LSTM并不具有排列不变性,因为它们是以顺序方式处理其输入。因此,需要将LSTM应用于节点邻居的随机排列,这可以使LSTM适应无序集合。

那么GraphSAGE是如何学习聚合器的参数以及权重矩阵W 1 有监督的情况下,可以使用每个节点的预测lable和真实lable的交叉熵作为损失函数。对所有的节点进行一个分类任务,假如是二分类,那么损失函数就是一个交叉熵损失
训练的过程,我们可以把多个节点的embedding作为一个batch,如下图是3个节点对应的embedding
参数主要有三部分,分类任务的 θ、生成embedding的 W_k与 B_k,这些参数对于不同的节点都是共享的
训练好的模型,只要是同样的场景都可以使用,例如我们对某有机物A构建了其蛋白质结构图,同样适用于有机物B。在工业场景中,图中新加一个节点也是很常见的情况,特别是社交网络这样的图,我们依旧不需要重新训练模型,直接对新加的节点使用训练好的神经网络进行embedding的生成即可。 2 无监督的情况下,可以假设相邻的节点的embedding表示尽可能相近,因此可以设计出如下的损失函数,损失函数定义如下:
其中u和v共出现在固定长度的随机游动中,v_n是与u不共出现的负样本。这种损失函数鼓励距离较近的节点进行类似的嵌入,而距离较远的节点则在投影空间中进行分离。通过这种方法,节点将获得越来越多的关于其邻域的信息。 GraphSage通过聚合其附近的节点,为不可见的节点生成可表示的嵌入。它允许将节点嵌入应用于涉及动态图的领域,其中图的结构是不断变化的。例如,Pinterest采用GraphSage的扩展版本PinSage作为内容发现系统的核心。 预测时需要采样吗?其实采样是独立于模型的,训练时输入采样后的mini-batch进行训练 预测时,不进行采样直接输入模型,即聚合节点的所有邻接节点信息产生embedding, 当然预测时也可以进行采样,根据实际效果选择即可。 五 总结
为什么GCN是transductive,为啥要把所有节点放在一起训练? 不一定要把所有节点放在一起训练,一个个节点放进去训练也是可以的。无非是如果想得到所有节点的embedding,那么GCN可以把整个graph丢进去,直接得到embedding,还可以直接进行节点分类、边的预测等任务。 其实,通过GraphSAGE得到的节点的embedding,在增加了新的节点之后,旧的节点也需要更新,这个是无法避免的,因为,新增加点意味着环境变了,那之前的节点的表示自然也应该有所调整。只不过,对于老节点,可能新增一个节点对其影响微乎其微,所以可以暂且使用原来的embedding,但如果新增了很多,极大地改变的原有的graph结构,那么就只能全部更新一次了。从这个角度去想的话,似乎GraphSAGE也不是什么“神仙”方法,只不过生成新节点embedding的过程,实施起来相比于GCN更加灵活方便了。在学习到了各种的聚合函数之后,其实就不用去计算所有节点的embedding,而是需要去考察哪些节点,就现场去计算,这种方法的迁移能力也很强,在一个graph上学得了节点的聚合方法,到另一个新的类似的graph上就可以直接使用了。 至此,GraphSAGE介绍完毕。我们来总结一下,GraphSAGE的一些优点 (1)利用采样机制,很好的解决了GCN必须要知道全部图的信息问题,克服了GCN训练时内存和显存的限制,即使对于未知的新节点,也能得到其表示 (2)聚合器和权重矩阵的参数对于所有的节点是共享的 (3)模型的参数的数量与图的节点个数无关,这使得GraphSAGE能够处理更大的图 (4)既能处理有监督任务也能处理无监督任务 当然,GraphSAGE也有一些缺点,每个节点那么多邻居,GraphSAGE的采样没有考虑到不同邻居节点的重要性不同,而且聚合计算的时候邻居节点的重要性和当前节点也是不同的。 六 PinSAGEPin是什么意思 Pinterest是一个图片素材网站,pins是指图片,而boards则是图片收藏夹的意思。 Pinterest会根据用户的浏览历史来向用户推荐图片 比GraphSAGE改进了什么? 采样: 使用重要性(权重)采样替代GraphSAGE的均匀采样; 聚合函数: 聚合函数考虑了边的权重; 生产者-消费者模式的minibatch: 在CPU端采样节点和构建特征,构建计算图;在GPU端在子图上进行卷积运算,从而可以低延迟的随机游走构建子图,而不需要把整个图存在显存中; 采样时只能选取真实的邻居节点吗?如果构建的是一个与虚拟邻居相连的子图有什么优点?PinSAGE 算法将会给我们解答 PinSAGE 算法通过多次随机游走,按游走经过的频率选取邻居,例如下面以 0 号节点作为起始,随机进行了 4 次游走 
其中 5、10、11 三个节点出现的频率最高,因此我们将这三个节点与 0 号节点相连,作为 0 号节点的虚拟邻居
回到上述问题,采样时选取虚拟邻居有什么好处?可以快速获取远距离邻居的信息。实际上如果是按照 GraphSAGE 算法的方式生成子图,在聚合的过程中,非一阶邻居的信息可以通过消息传递逐渐传到中心,但是随着距离的增大,离中心越远的节点,其信息在传递过程中就越困难,甚至可能无法传递到;如果按照 PinSAGE 算法的方式生成子图,有一定的概率可以将非一阶邻居与中心直接相连,这样就可以快速聚合到多阶邻居的信息
DGL源码【Code】GraphSAGE 源码解析 - 知乎 (zhihu.com) DGL图神经网络 - 知乎 (zhihu.com) 论文:Inductive Representation Learning on Large Graphs知乎:【Graph Neural Network】GraphSAGE: 算法原理,实现和应用知乎:网络表示学习: 淘宝推荐系统&&GraphSAGEGNN 系列(三):GraphSAGEGraphSAGE: GCN落地必读论文 图神经网络(GNN)入门之旅(四)-GraphSAGE和PinSAGE |


 3. 将embedding作为全连接层的输入,预测目标节点的标签。
3. 将embedding作为全连接层的输入,预测目标节点的标签。




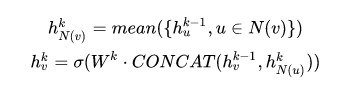
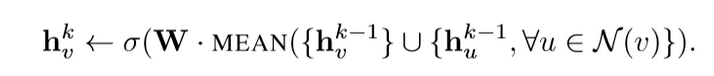


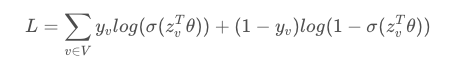





【本文地址】