| 编译原理复习 | 您所在的位置:网站首页 › 编辑程序将高级语言程序翻译成与之等价 › 编译原理复习 |
编译原理复习
|
《编译原理》复习
README
来源网络&书本&PPT整理
截取了老师课上讲解or布置的题目
一些题目懒得贴答案了,写了些注意事项
第1 章引论
运行编译程序的计算机:宿主机
运行编译程序所产生的目标代码的计算机:目标机
第1 题解释下列术语:
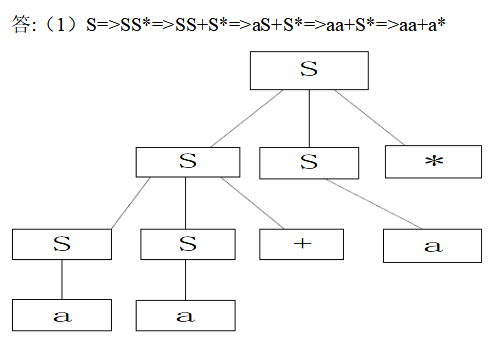
(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。 (2)源程序:源语言编写的程序称为源程序。 (3)目标程序:目标语言书写的程序称为目标程序。 (4)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。 (5)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。 (6)遍:是对源程序或其等价的中间语言程序从头到尾扫视并完成规定任务的过程。 第2 题一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。(区别编译程序的六个阶段) 答案:一个典型的编译程序通常包含8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。其各部分的主要功能简述如下。 词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。 语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。 中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。 中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。 目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。 表格管理程序:负责建立、填写和查找等一系列表格工作。表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。可以说整个编译过程就是造表、查表的工作过程。需要指出的是,这里的“表格管理程序”并不意味着它就是一个独立的表格管理模块,而是指编译程序具有的表格管理功能。 错误处理程序:处理和校正源程序中存在的词法、语法和语义错误。当编译程序发现源程序中的错误时,错误处理程序负责报告出错的位置和错误性质等信息,同时对发现的错误进行适当的校正(修复),目的是使编译程序能够继续向下进行分析和处理。 第3 题 何谓翻译程序、编译程序和解释程序?它们三者之间有何种关系?答案:翻译程序是指将用某种语言编写的程序转换成另一种语言形式的程序的程序,如编译程序和汇编程序等。 编译程序是把用高级语言编写的源程序转换(加工)成与之等价的另一种用低级语言编写的目标程序的翻译程序。 解释程序是解释、执行高级语言源程序的程序。解释方式一般分为两种:一种方式是,源程序功能的实现完全由解释程序承担和完成,即每读出源程序的一条语句的第一个单词,则依据这个单词把控制转移到实现这条语句功能的程序部分,该部分负责完成这条语句的功能的实现,完成后返回到解释程序的总控部分再读人下一条语句继续进行解释、执行,如此反复;另一种方式是,一边翻译一边执行,即每读出源程序的一条语句,解释程序就将其翻译成一段机器指令并执行之,然后再读人下一条语句继续进行解释、执行,如此反复。无论是哪种方式,其加工结果都是源程序的执行结果。目前很多解释程序采取上述两种方式的综合实现方案,即先把源程序翻译成较容易解释执行的某种中间代码程序,然后集中解释执行中间代码程序,最后得到运行结果。 广义上讲,编译程序和解释程序都属于翻译程序,但它们的翻译方式不同,解释程序是边翻译(解释)边执行,不产生目标代码,输出源程序的运行结果。而编译程序只负责把源程序翻译成目标程序,输出与源程序等价的目标程序,而目标程序的执行任务由操作系统来完成,即只翻译不执行。 第4 题 对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、代码生成)报告的。(1)else 没有匹配的if (2)数组下标越界 (3)使用的函数没有定义 (4)在数中出现非数字字符 答案:(1)语法分析 (2)语义分析 (3)(课上说是语义分析) (4)词法分析 第2 章文法和语言 第1 题文法G=({A,B,S},{a,b,c},P,S)其中P 为:S→Ac|aB A→ab B→bc 写出L(G[S])的全部元素。 答案:L(G[S])={abc} 第2 题文法G[N]为:N→D|ND D→0|1|2|3|4|5|6|7|8|9 G[N]的语言是什么? 答案:G[N]的语言是V+。V={0,1,2,3,4,5,6,7,8,9} N=>ND=>NDD.... =>NDDDD...D=>D......D 第5题 已知文法G[Z]:Z→aZb|ab 写出L(G[Z])的全部元素。答案:Z=>aZb=>aaZbb=>aaa..Z...bbb=> aaa..ab...bbb L(G[Z])={anbn|n>=1} 第8题 考虑下面上下文无关文法S—>SS*|SS+|a (1)表明通过此文发如何生成串aa+a*, 并为该串构造推导树。 (2)该文法生成的语言是什么?
(2)??? 由a, +, * 组成的逆波兰表达式 \(S->S(S)S|\varepsilon\) (1)生成的语言是什么? (2)该文发是二义的吗?说明理由。
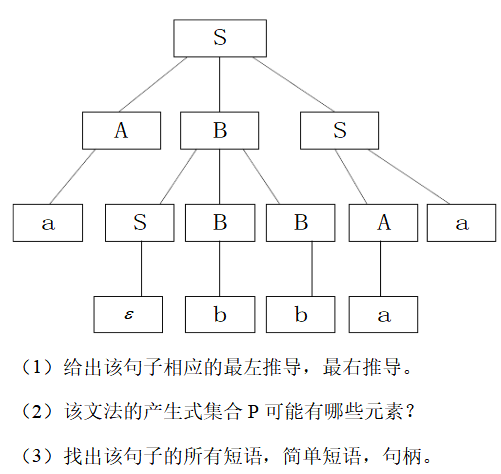
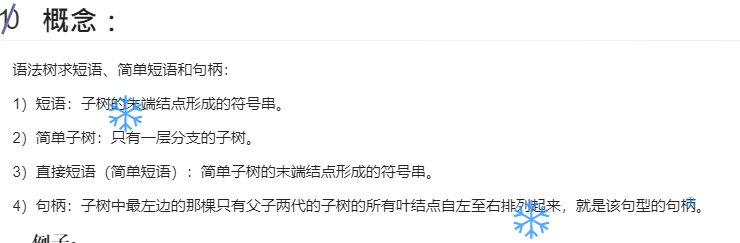
令文法G[E]为: E->T|E+T|E-T T->F|T*F|T/F F->(E)|i 证明E+T*F是它的一个句型,指出这个句型的所有短语,直接短语和句柄。 答:因为E=>E+T=>E+T*F,所以E+T*F是它的一个句型。 因为E=>E+T=>E+T*F,所以该句型相对于E的短语有:E+T*F 因为T-> T*F,所以该句型相对于T的短语有:T*F 直接短语为:T*F 句柄为:T*F 第11题一个上下文无关文法生成句子abbaa的推导树如下
(1) 最右推导: S=>ABS=>ABAa=>ABaa=>ASBBaa=>ASBbaa=> ASbbaa=>Abbaa=>Abbaa=>abbaa 最左推导: S=>ABS=>aBS=>aSBBS=>aBBS=>aBBS=>abBS=> abbS=>abbAa=>abbaa (2)
(3)
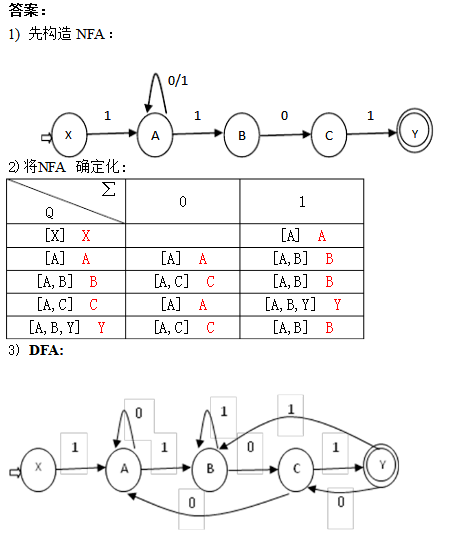
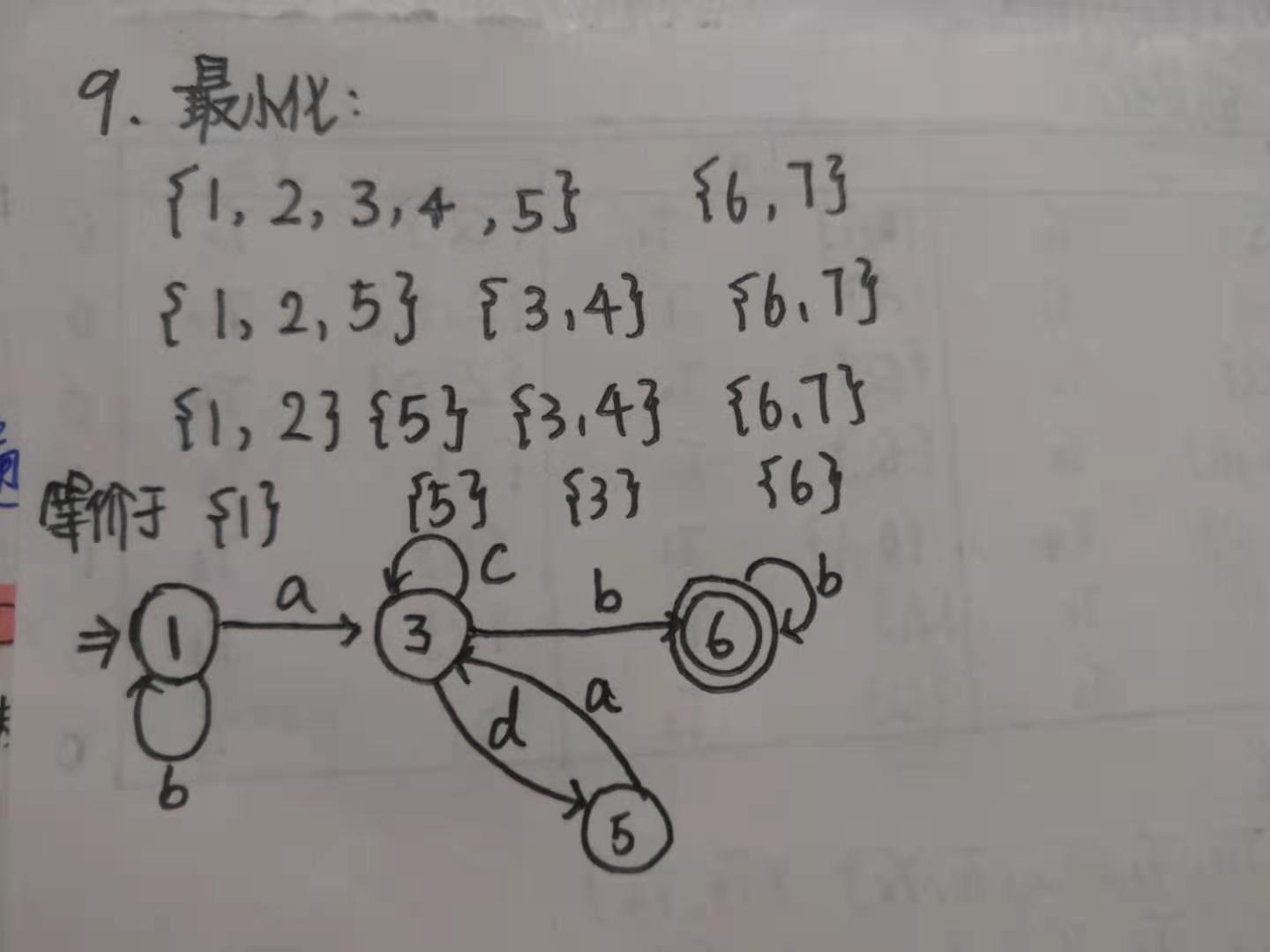
1.构造下列正规式相应的DFA. (1)1(0|1)*101
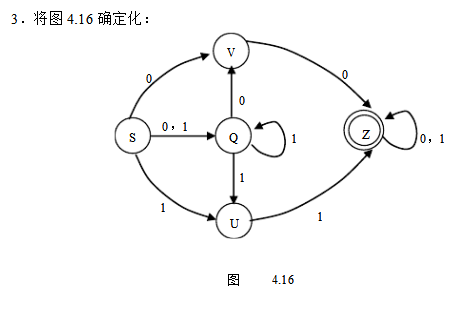
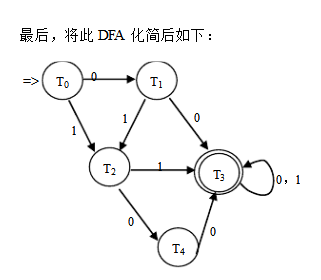
将3.16中的NFA确定化
答: 
题目: // TODO: (1) 注意分层 (2) 改写:非LL(1)转换为LL(1)文法。这个知识点主要是提左公因子和消除左递归。 这道题 \(T \to T,S|S\) 递归下降子程序:注意要看Select(...),特别是推出\(\varepsilon\)的情况。(3) 判断是否为LL(1)文法:看产生式左部相同的SELECT集之间是否有交集,有则不是,否则是。 预测分析表:注意看整个预测分析表的结构
(4) 分析过程:使用预测分析表,预测分析表有四个部分 步骤 分析栈:右边是栈顶,初始时栈内为”#S“ 剩余输入串:这个不是栈,就是要求的输入串,从左到右扫描 所用产生式或匹配:使用产生式,先在分析栈中把原来的左部弹出,再逆序将右部压入栈。 当最终分析栈和剩余输入串都是#时,匹配部分写:接受 第2题 (1) 求FIRST, FOLLOW, SELECT太容易连环错啦!!! 求FIRST时,建议拿个铅笔对着产生式,求一个删一个,别看错了!!!!啊啊啊!! 求FOLLOW的时候用哪个产生式,拿手或者对那个产生式做个标记,别看歪了。大😭 而且求这个FOLLOW集的时候,可能要用到别的FOLLOW集,别看错把FIRST集填进去了,最好写个F几,到时求出来了就回填。 (4)递归下降分析有缘再贴上来,太多了哈哈🐷 第3题
第3题
求FIRST的时候建议把\(\varepsilon\)放集合的末尾,以免我又分析完为空的情况就以为自己做完了😐
老师的简单总结 编译过程的各个阶段 文法和语言的关系,给定一个文法,生成语言的句子;给定句子,设计相应的文法;文法的分类;句型、句子、最左推导,最右推导,规范推导、短语,直接短语,句柄; 单词的描述工具:正规文法和正规式,有穷自动机,三者之间的转换关系,有穷自动机的确定化和最小化; 自顶向下的语法分析:LL(1)文法,非LL(1)文法消除左递归,提取左公因子;预测分析法,递归子程序法,如何利用预测分析表进行某个句型或句子的语法分析判断; LR分析:LR(0)\SLR(1),如何构造识别活前缀和可归前缀的有穷自动机,项目是什么,项目集规范族来构造DFA,得到LR分析表,如何进行语法分析。 注意:构造识别一个文法活前缀的有穷自动机是DFA 项目:在文法G中每个产生式的右部适当位置添加一个圆点构成项目 注意:\(A\rightarrow \varepsilon\)只有一个项目\(A\rightarrow \cdot\) 中间代码的形式,基本语言成分的中间代码的生成; 逆波兰表达式 三元式 四元式 树形表示 中间代码优化,分为局部优化,循环优化和全局优化,基本块,如何利用DAG进行优化; 存储分配:静态和动态(栈式和堆式); 静态:指在编译时对数据对象分配固定的存储位置,运行时始终不变。即一旦存储空间的某个位置分配给了某个数据名,则在目标程序的整个运行过程中,此位置(地址)就属于该数据名。 特点:简单,易于实现 动态栈式存储分配:在数据空间中开辟一个栈区,每当调用一个过程时,他所需要的数据空间就分配在栈顶,每当过程工作结束时就释放这部分空间。空间使用符合先借后还得原则。 特点;先借后还,管理简单,空间使用效率高 动态堆式存储分配:在数据空间中开辟一片连续的存储区(堆),每当需要时就从这片空间借用一块,不用时再环。借用和归还未必服从“先借后还”原则。 特点:适用范围广,容易出现碎片。 存储分配:参数传递形式; 传值(值调用) 传地址(引用调用) 传名(换名) 目标代码生成的基本知识。 简答题复习 文法 文法定义 G=(VN, VT, P, S) VN:一组非终结符号 VT:一组终结符号 P: 一组产生式 S: 一个开始符号 文法分类 按对产生式施加不同的限制把文法分成四种类型: 0型:短语文法 1型:上下文有关文法 2型:上下文无关文法 3型:正规文法(正则文法、线性文法) 涉及的上下文无关文法:LL(1)文法、LR文法 文法的二义性 对于一个文法G而言,如果L(G)中存在某个句子对应两颗不同的语法树,那么该文法就称为二义的。 文法的实用限制 基本概念(按概念的关联性分组记忆)直接推出、推导、句型、句子、语言、最左推导、最右推导(规范推导)、规范句型 直接推出: 推导: 句型: 如果符号串x是从识别符号推导出来的,即\(S\Rightarrow ^* x\)那么称x是G[S]的句型 句子:若x仅由终结符号组成,即\(S\Rightarrow ^* x, x\in V_T^*\) 语言:文法描述的语言是该文法一切句子的集合。 最左推导: 最右推导(规范推导): 规范句型(右句型):由规范推导所得到的句型
直接归约、归约、句柄、规范归约(最左归约) 可归前缀、LR(0)项目集规范族 活前缀:形成可归前缀之前包括可归前缀的所有前缀 其他什么叫翻译程序?什么叫汇编程序?什么叫编译程序 编译程序:将用高级语言书写的程序翻译成等价的低级语言程序 汇编程序:将用高级语言书写的程序翻译成等价的汇编语言程序 翻译程序:将用某种语言编写的程序转换成另一种语言形式的程序的程序,如编译程序和汇编程序等。编译过程分哪几个主要阶段?每个阶段的主要任务是什么? 词法分析:对构成源程序的字符流进行扫描和分解,从而识别出一个个单词。 语法分析:在词法分析的基础上,将单词序列分解成各类语法短语,确定整个输入串是否构成语法上的正确程序。 语义分析:审查源程序是否有语义错误,为代码生成阶段收集类型信息。 中间代码生成:将源程序生成一种内部表示形式,这种内部表示形式叫中间代码。 代码优化:对中间代码进行等价变换,以便生成更高效的目标代码。 目标代码生成:把中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码,它的工作与硬件系统和指令含义有关。单词符号分哪几类?各举出例子。 标识符 基本字(关键字) 运算符 界符 常数正则表达式到DFA的转换(子集法和分割法) 什么叫静态存储分配? 指在编译时对数据对象分配固定的存储位置,运行时始终不变。即一旦存储空间的某个位置分配给了某个数据名,则在目标程序的整个运行过程中,此位置(地址)就属于该数据名。 特点:简单,易于实现通常参数传递有哪些主要方式?每种方式是如何实现的? 传值 传地址 传名中间代码通常有哪些类型?各有什么特点? 逆波兰记号:运算对象写在前面,运算符写在后面,易于计算机处理。 三元式 四元式:普遍 比三元式更便于优化 四元式对生成目标代码有利 树形表示:二目运算对应二叉子树,朵目运算对应多叉子树。什么叫语法制导翻译法? 在语法分析过程中,随着分析的步步进展,每当使用一条产生式进行推导(对于自上而下分析)或归约(对于自下而上分析),就执行该产生式所对应的语义动作,完成相应的翻译工作。试述赋值语句、布尔表达式、IF语句、WHILE语句、REPEAT语句的文法、语义、翻译目标? 中间代码优化分哪几类?每一类有哪些主要优化技术? 局部优化:在只有一个入口、一个出口的基本块上进行优化。(用DAG) 删除多余运算(删除公共子表达式) 合并已知量与复写传播 删除无用赋值 循环优化:对循环中的代码进行优化(用流图) 代码外提 强度削弱 变换循环控制条件(删除归纳变量) 全局优化:在整个程序范围内进行的优化什么叫基本块?如何把中间代码程序划分成基本块? 基本块是指程序中一顺序执行的语句序列,其中只有一个入口语句和一个出口语句。执行试时,只能从入口语句进入,从其出口语句退出。 入口语句: 程序的第一个语句 条件转移或者无条件转移语句的转移目标语句 紧跟在条件转移语句后面的语句基本块优化的算法 借助DAG进行基本块的优化 |



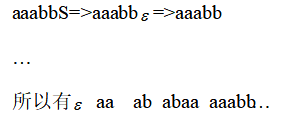


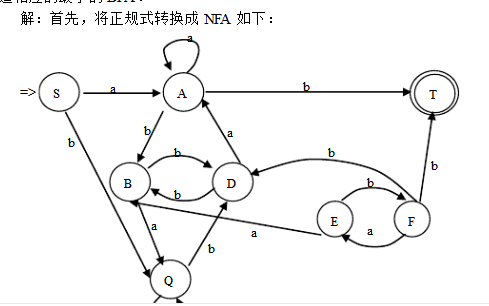
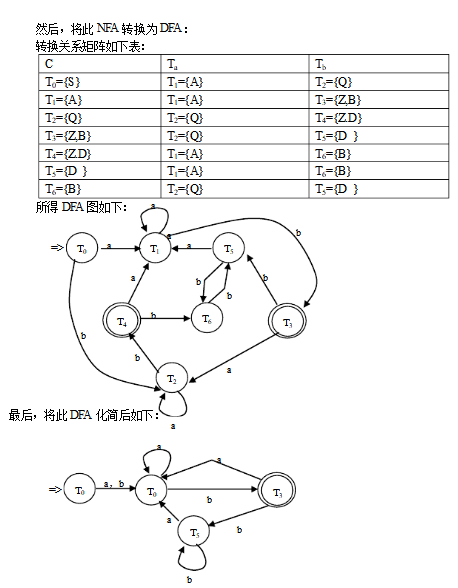

【本文地址】