| 词法分析☞正则表达式 | 您所在的位置:网站首页 › 编译原理闭包运算法则 › 词法分析☞正则表达式 |
词法分析☞正则表达式
|
正则表达式
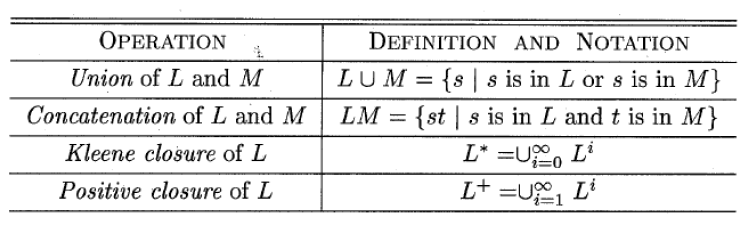
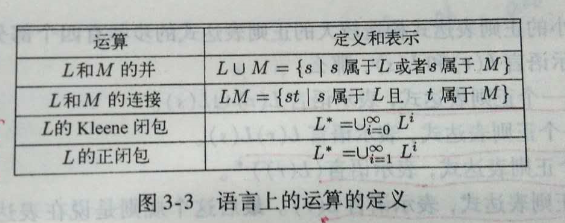
正则表达式是一种用来描述词素模式的重要表示方法。 值得注意的是,虽然正则表达式无法表达出所有可能的模式,但是它们可以很高效地描述自处理词法单元时要用到的模式类型 首先 先看几个基本定义 字母表(alphabet)是一个有限的符号集合Σ。符号的典型例子包括字母、数字和标点符号。 例如Σ= {0,1}是二进制字母表(binary alphabet)。 串(string)是该字母表中符号的一个有穷序列。串s的长度通常记作 |s|,指串中符号出现的次数。例如 teach 这个串的长度为5. 长度为0的串称为空串(empty string),用符号ε表示。 语言(language)是某个给定字母表上一个任意的可数的串的集合。(该定义并不要求语言中的串一定具有某种含义)。例如,100, 001, 000是二进制字母表上定义的语言 如果x和y是串,则x和y的连接(concatenation)(记作xy)是把y附加到x后面而形成的串。例如x=aaa,y=bbb,那么xy=aaabbb。值得注意的是,空串是连接运算的单位元也就是说 xy=xεy。而对于任意的串,有sε=εs=s。 如果把两个串的连接看成是这两个串的乘积,可以定义“指数”运算s^0=ε, s^1=s, s^2=ss…. 语言的运算(并、连接、闭包)其中,闭包包括Kleene闭包和正闭包 正则语言的优点 * 容易理解 * 能高效实现 * 具有坚实的理论基础 正则表达式可以由较小的正则表达式递归构建 正则表达式的递归定义(1) ε是一个正则表达式,L(ε)={ε}, 即该语言只包含空串。 (2) 如果a是Σ上的一个符号,那么a是一个正则表达式,并且L(a)={a}。也就是说,这个语言仅包含一个 长度为1的符号串a 归纳步骤:由较小的正则表达式构造出较大的正则表达式有四个步骤,假设r和s都是正则表达式,对应的语言分别为L(s)和L(r). 1) (r)|(s)是一个正则表达式,表示语言L(r)⋃L(s). 2) (r)(s)是一个正则表达式,表示语言L(r)L(s). 3) (r)*是一个正则表达式,表示语言(L(r))* 4) (r)是一个正则表达式,表示语言L(r)。这个规则是为了说明在表达式两边加上括号不影响表达式表示的语言。 由于上面的定义,正则表达式有时会出现一些不必要的括号。为了去掉一些括号,我们有如下规定 (1) 一元运算符*具有最高的优先级,并且是左结合的 (2) 连接具有次高优先级,并且也是左结合的 (3) | 的优先级最低,并且也是左结合的 例子 令Σ = {a, b} 正则表达式 a|b 表示语言 {a, b}. 正则表达式 (a|b)(a|b)表示语言 aa|bb|ab|ba 正则表达式 a* 表示所有由零个或多个a组成的串的集合 即{ε, a, aa, aaa, aaaa….} 可以用一个正则表达式定义的语言叫做正则集合(regular set)如果两个正则表达式r和s表示同样的语言,则称r和s**等价(equivalent)**,记作r=s. 下面给出正则表达式的代数定律。 有时,对一个正则表达式,一个表示部分可能会重复出现多次,为了方便,我们希望能够给某些正则表达式命名,并在之后的正则表达式中使用,即正则定义。 以C语言标识符为例,表示标识符的正则表达式如下 (a|b|c…|z|A|B….|Z|_)( (a|b..|z|A|B…|Z|_)|(0|1|2…|9) )* 该表达式看起来很冗长,当引入正则定义后,有: letter_ → a|b|c…|z|A|B….|Z|_ digit → 0|1|2…|9 id → letter_(letter_|digit)* 正则表达式的扩展一个或多个实例: r*表示的是0个或多个r的串,而 r+ == rr*即 去掉了空串的情况 零或一个实例: 使用单目运算符?,意思是出现0次或1次。a? 表示的语言为{a, ε}. ?运算符与+运算符和*运算符具有同样的优先级和结合性。 字符类: 一个正则表达式 a1|a2|a3…|an(ai是字母表中的各个符号) 可以缩写为[a1a2a3…an],当其是连续的时候,可以表示为[a1-an],例如a|b|c…|z 可以表示为[a-z] 练习下面的正则表达式描述了什么语言 a(a|b)*a 所有以a开始和结束,并且中间有0个或多个a或b的串 (a|b)*a(a|b)(a|b) 所有以 aaa或aab或aba或abb结尾的只含有ab的串 a*ba*ba*ba* 所有有且只有三个b的含有ab的串 ((ε|a)b*)* 等价于 (ab*)*即 包含任意个a和b的串(???) b*(ab*ab*)* 所有含有偶数个a的由a和b组成的字符串 c*a(a|c)*b(a|b|c)*|c*b(b|c)*a(a|b|c)* 表示至少存在一个a和一个b的由abc三个字符组成的串 设字母表∑={a,b},用正则表达式(只使用a,b,,|,*,+,?)描述下列语言: 1. 不包含子串ab的所有字符串. b*a* 2. 不包含子串abb的所有字符串. b*(ab?)* 3. 不包含子序列abb的所有字符串. b*a*b?a* 补充关于串的部分术语 1) 串s的前缀(prefix)是从s的尾部删除0个或多个符号后得到的串。例如 ban,banana和ε是banana的前缀 2) 串s的后缀(suffix)是指从s的开始处删除0个或多个符号后得到的串。例如nana,banana和ε是banana的后缀 3)串s的子串(substring)是指删除s的某个前缀和某个后缀后得到的串。例如 ana是banana的子串 4) 串s的真(true)前缀、真后缀、真子串分别是s的既不等于ε,也不等于本身的前缀、后缀和子串 5) 串s的子序列(subsequence)是指从s中删除-个或者多个符号后得到的串,这些被删除的符号可能不相邻。例如,baaa是banana的一个子序列 |

【本文地址】