| 双侧检验的p值和单侧检验 | 您所在的位置:网站首页 › 统计学z值计算p值 › 双侧检验的p值和单侧检验 |
双侧检验的p值和单侧检验
|
我们都知道p值是用来说明数据间显著性差别的统计值,p值的由来以及计算方法可谓是非常有意思,所以在这里介绍给大家。 我们从一个经典的例子开始: 小明闲的蛋疼抛硬币玩,他连续抛出一枚硬币5次,并得到了(正 正 正 正 反)的结果,这时小明就想了:“这枚硬币的质量分布一定不均匀!否则我不会抛出4次正面!” 小明想完就去做作业了,但是他的猜想到底是不是对的呢? 为了验证他的的猜想,我们提出了原假设:这枚硬币和普通的硬币并没有区别(要注意,无论你的猜想是怎样的,原假设总是猜想你的抽样和整体内的其他没有区别)。 想要说明小明的硬币是不是有区别的硬币,我们首先得知道正常的硬币是什么样子的,所以我们也开始抛硬币,经过多次试验后,我们发现如果不在乎顺序的投掷5次硬币,我们只会得到6种结果:全部正面、全部反面、四正一反、四反一正、三正二反、三反二正。这种结果出现的概率分别是:全部正面(1/32)、全部反面(1/32)、四正一反(5/32)、四反一正(5/32)、三正二反(10/32)、三反二正(10/32)。容易看出,我们得到四正一反的概率是5/32,从概率上讲,这的确不是很高,但是概率是用来说明出现该情况的可能性的值,因此,我们不能因为它的概率不高就认为它的出现是不正常的情况。为了说明这个问题,我们引入了p值这个概念。 官方的计算方法是: 将①所观测到的情况出现的概率 以及②和它出现的概率相同情况的概率 以及③比它出现概率低的情况的概率 三种概率相加,所得到的值即为p值。 因此在小明这个例子中,p值等于: 5/32+5/32+1/32+1/32=12/32=0.375 为了统一标准,我们一般选择p=0.05作为判断是否拒绝原假设的阈值,0.375显然大于0.05,因此我们无法拒绝我们的原假设,也就是说,我们仍然认为这是一枚普通的硬币。 但是,为什么要把这些值加起来呢?在数学上自然有它的表达形式,那有没有一种通俗易懂的解释呢? 有的。 网上查找的一些解释,我觉得都不够直观,所以我提出了一个自认为直观的解释: 正常情况下,我们认为这样的叫做狗:
好,现在我们有10只狗。 但是,现在有2只小动物不服气了,它说:
现在我们有2只自称自己是狗的小动物,它仅占2/12,因此我们可能仍会认为,只有上图的动物叫做狗。 然后同样的怪事出现了,又有2只小动物不服气了,它们说:
现在奇怪的小动物占整体的4/14了,我们仍可以认为它的占比太小了,因此拒绝认为它们是狗。 但是更怪的事出现了:
。。。。。。 忽略掉怎么看它都是坨屎的事实,现在怪异的东西已经占1/3了,我们已经没办法再说:只有这样的才叫狗。
这样就很直白了:为了通过某次观测来说明这个总体是否和另一个总体有差异,我们需要把所有的比这次观测更怪异的情形都相加起来,只有这样,才能说明总体间的差别。 我们在做抽样检验的时候不可能总是针对一个对象,很多时候我们会对很多对象进行相同的检验,这样就会给我们带来一些问题,我们称它为多重检验。在进行多重检验的时候,我们更容易获得假的阳性结果,所以我们倾向于用更严格的筛选方式来获得我们需要的阳性检验结果(positive)。 为什么?
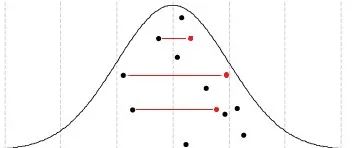
我们都知道,在正态分布中,取得根据均值对称的两个值的概率是相等的,因此,虽然在多次抽样中,我们的样本大概率分散于均值的两侧,但是具体到某一次抽样时,取得某种有偏好性的分布的概率和散乱分布其实是一样的(图中红点和黑点的变换)。 所以,在多次假设检验中,我们总会抽到样本均值偏小和样本均值偏大的两组样本,并导致它们直接的p值足够小,小到我们可以拒绝零假设,但是这样的结果显然是虚假的阳性结果。 因此,基于FDR的多重检验校正应运而生,本次介绍的假设检验方法叫做:benjamini -hochberg矫正,为了理解这个方法,我们首先要知道的是: 当原假设(H0)为真时,p值符合 [0,1]上的均匀分布。
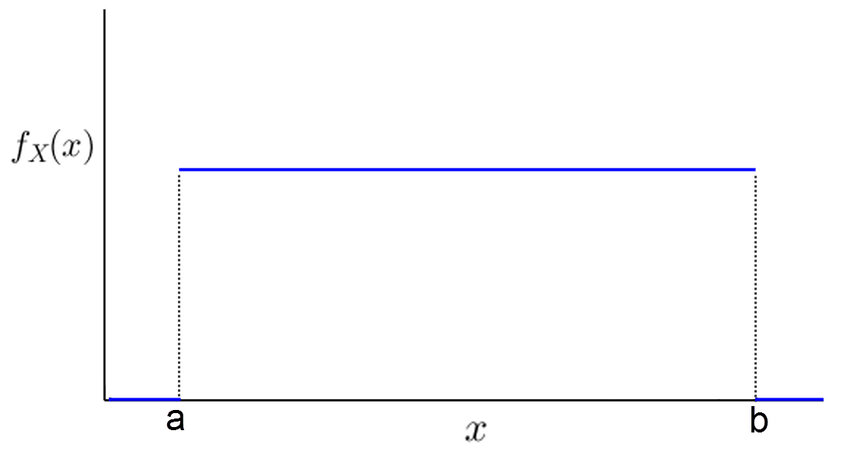
图为均匀分布的函数图形 针对这个分布,我们有数学解释: 假设PP是代表p值的随机变量,要证明P服从[0, 1]均匀分布,只需要证明Pr(P≤z)=z。假定我们假设检验中的统计量是T,那么根据p值的定义,我们有P=F(T)P=F(T),其中F是统计量T的概率累积函数。 那么:
相信大家都不愿意看数学解释,我在网络上也没有找到通俗的解释,所以不如就让我来解释解释 当两次抽样来自同一样本的时候,误差是随机产生的,误差的大小也是随机的,因此,我们对两次抽样进行假设检验的时候,p值会随机的在[0,1]之间产生,因此我们取得任意p值的概率其实是相等的。所以在多重检验矫正中,有一种最简单也最严格的矫正方法: Bonferroni校正:如果在同一数据集上同时检验n个独立的假设,那么用于每一假设的统计显著水平,应为仅检验一个假设时的显著水平的1/n。 另外就是我们之前提到的benjamini -hochberg矫正了,它的大致方法如下:将总计m次检验的结果按由小到大进行排序,k为其中一次检验结果的P值所对应的排名,新得到的p值为p = p*(m/k)。 如果通过图表来看的话,当我们的两个样本来自同一整体的时候,它们的分布大概是这样的:
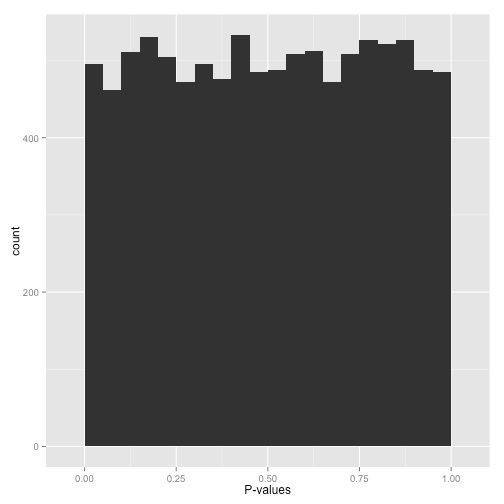
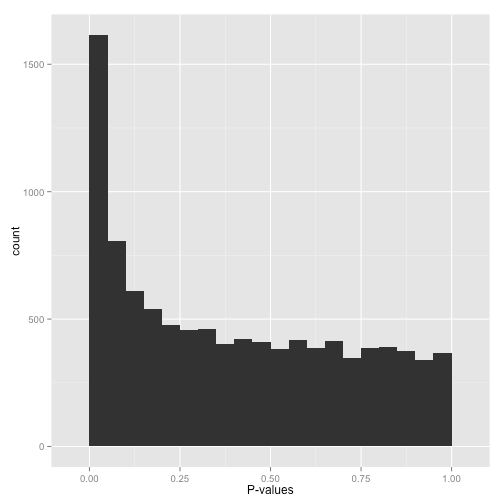
而大部分时候,我们得到的p值分布直方图大概是这样的:
在这种情况下,我们需要对p值做一些矫正,剪掉一些我们不想要的数据:
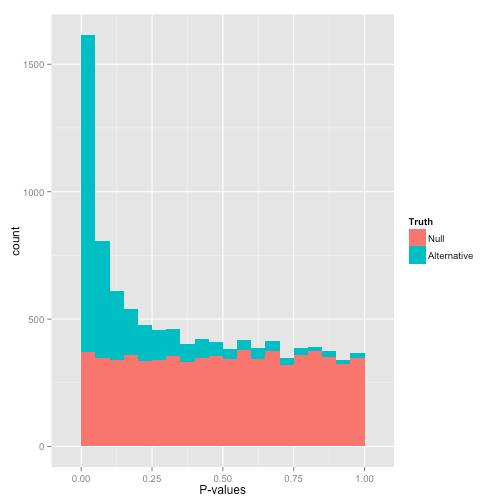
事实上,经过多重检验矫正后,我们希望得到青色部分的p值数据。 当然你还可能会得到这样的结果:
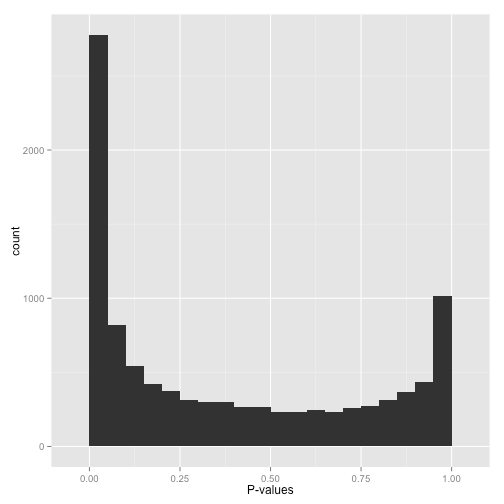
在末端的p值畸变往往是因为错误用双尾检验的方法对应该用单尾检验的数据进行了检验,比如某个药的疗效,我们只想知道它能不能缩短病人的被治愈时间,而往往那些久久不能痊愈的病人并非是因为服用了这种药物。 另外,要注意的是,真正的阳性测试并不永远拥有最显著的p值,因此我们仍然有可能在某些检验的时候错误的删去它们,因此我们不应该迷信p值,而需要用多种手段来说明假设的正确性。 今天就到这里了, 那么朋友们,再见
|





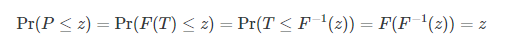
 。
。


【本文地址】