| 探索性数据分析与可视化 | 您所在的位置:网站首页 › 简述数据报表与可视化的实施思路及方法论文 › 探索性数据分析与可视化 |
探索性数据分析与可视化
|
世界如此大,我想去看看;数据如此丰富,怎么能看完。 面对未知,人类是富有探索精神的,可以不畏艰险,可以排除万难,正是这种探索精神使得人类不断进步不断创造一个又一个奇迹。对于纷繁复杂的数据世界,我们如何进行探索性分析呢? 探索性数据分析之前的一些模型是假定数据服从某种分布,然后用样本去调整假设分布的参数,比如贝叶斯模型,GMM等。如果面临错综复杂的数据,我们想去直接看到数据最原始的特点,比如,某个属性是什么分布特点,某些属性的关系,哪些因素具有最大量的信息,某些不确定关系的研究等等。这个时候,假设模型的方法就不那么好使了,这时候就较为考验一个综合能力了。 所谓探索性数据分析,是在没有头绪的情况下,对数据进行的基本分析,可以从中挖出更具有含金量的信息,为进一步的研究指明方向。探索性数据分析相当于做了个全身体检,重点部位重点检查,后续发现的问题不归其管,自己去找专家去搞定。 与可视化的关系探索性的数据分析,侧重于原始数据本身的展示,故此与数据可视化具有相当紧密的联系,并且图形展示更直观且有利于发现有价值的信息。 可视化能够帮助我们搞定以下几个问题: 1. 了解数据基本特征 2. 发现数据潜在的模式 3. 指导建模策略 4. 为工程提供参考信息和必要的更正 探索内容与实现虽说是探索,但也得有点目标才好,不能啥都不知道就愣头愣脑地往上冲,那岂不是自我证明非二即傻。手段要灵活,快捷。 Python2.7+ubuntu14.0 我们采取一个先分后总的研究顺序来探索。 分别看看各个属性的数据特征,大体分布时什么样子的(即可能会服从什么样子的分布),哪些值的数据最多,数据的均值方差最大最小各是多少,是否自相关等等。 大体分布最直观的就是直方图了,这个最易于实现。 import matplotlib.pyplot as plt data1 = [2,2,2,2,3,3,3,4,4,4,4,4,4] data2 = [2.3,2.4,3.4,2,1,3.4,2,5.6] plt.xlabel('Smarts') plt.ylabel('Probability') plt.title(r'$\mathrm{Histogram\ of\ IQ:}\ \mu=100,\ \sigma=15$') plt.axis([1, 6, 0, 6]) # 横纵范围 plt.grid(True) plt.show(plt.hist(data2, bins=4, facecolor='green'))#分成四份 # plt.subplot()用来分子图 plt.hist(data1, bins = 4, facecolor = 'green', alpha = 0.5) plt.hist(data2, bins = 4, facecolor = 'blue', alpha = 0.5) plt.show()上面的代码得到的两个图如下: 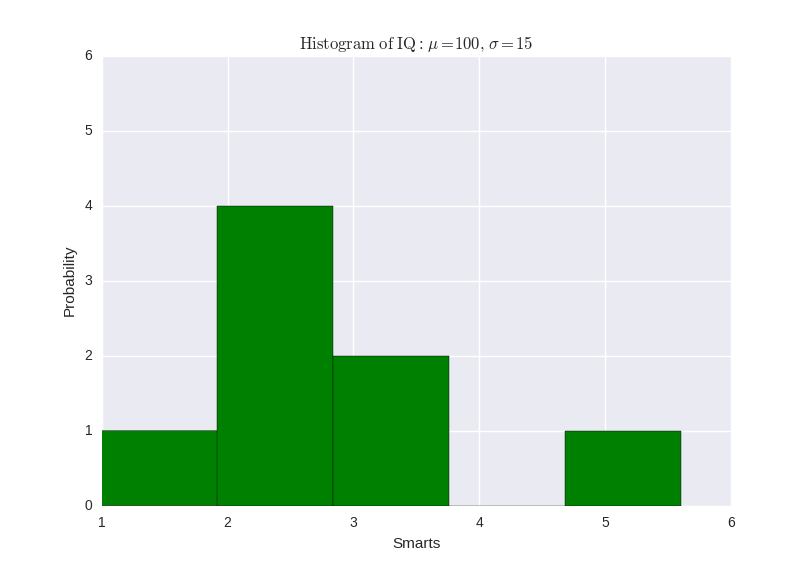
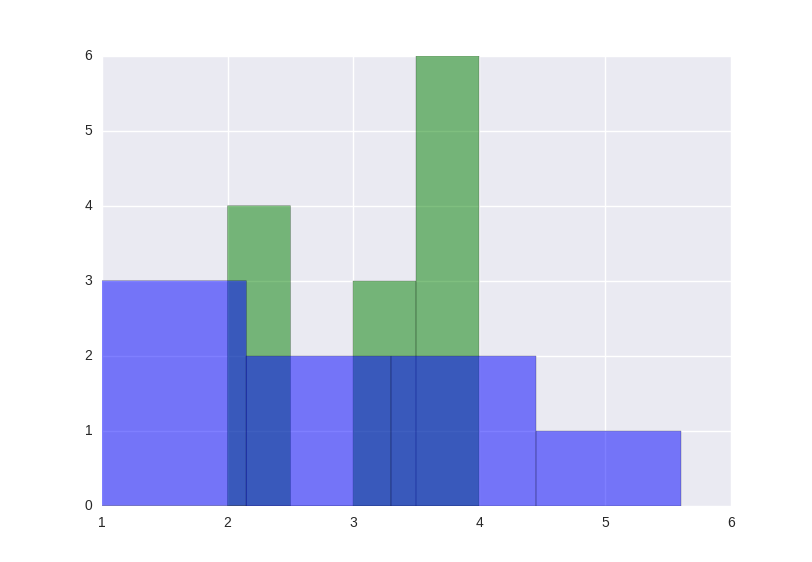 图中的横纵坐标的名称和标题只是为了展示如何给图配置,而不是真实情况。
稍微进阶一下,将多个图放到同一个图中展示(添加标题之类的操作和单个图时是一样的)。
import matplotlib.pyplot as plt
data1 = [2,2,2,2,3,3,3,4,4,4,4,4,4]
data2 = [2.3,2.4,3.4,2,1,3.4,2,5.6]
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1) # 2*2 的 第一个,及左上侧
ax1.hist(data1, bins=5, facecolor='green')#分成5份
ax2 = fig.add_subplot(222) # 2*2 的 第二个,及右上侧
ax2.hist(data2, bins=5, facecolor='green')#分成5份
ax3 = fig.add_subplot(212) # 2*1 的 第3个, 及下侧一整个
ax3.hist(data1, bins = 4, facecolor =
图中的横纵坐标的名称和标题只是为了展示如何给图配置,而不是真实情况。
稍微进阶一下,将多个图放到同一个图中展示(添加标题之类的操作和单个图时是一样的)。
import matplotlib.pyplot as plt
data1 = [2,2,2,2,3,3,3,4,4,4,4,4,4]
data2 = [2.3,2.4,3.4,2,1,3.4,2,5.6]
fig = plt.figure()
ax1 = fig.add_subplot(2, 2, 1) # 2*2 的 第一个,及左上侧
ax1.hist(data1, bins=5, facecolor='green')#分成5份
ax2 = fig.add_subplot(222) # 2*2 的 第二个,及右上侧
ax2.hist(data2, bins=5, facecolor='green')#分成5份
ax3 = fig.add_subplot(212) # 2*1 的 第3个, 及下侧一整个
ax3.hist(data1, bins = 4, facecolor =
|
【本文地址】