| 机器学习题5:请简述ID3算法的实现步骤,并利用ID3算法构建天气数据集的决策树模型,实现决策树的可视化。 | 您所在的位置:网站首页 › 简述决策树法的基本步骤 › 机器学习题5:请简述ID3算法的实现步骤,并利用ID3算法构建天气数据集的决策树模型,实现决策树的可视化。 |
机器学习题5:请简述ID3算法的实现步骤,并利用ID3算法构建天气数据集的决策树模型,实现决策树的可视化。
|
ID3算法的实现步骤: 输入:数据集(训练集)S及属性A 输出:属性A对训练数据集S的信息增益 ① 先将S作为根节点,其目标属性y有c个类别属性。假设S中
② 假设属性A有k个不同取值,因此将S划分为k个子集
③ 计算按照属性A划分S的信息增益
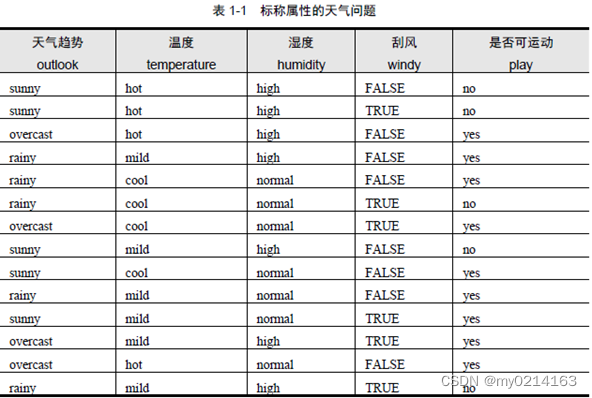
④ 信息增益 利用ID3算法构建天气数据集的决策树模型: 天气数据集:
① 计算数据集S的信息熵 该天气数据集的样本数为14,目标属性play有{yes,no}两个取值,取值为yes的有9个,取值为no的有5个,因此对应的
② 计算各个属性A对数据集S的信息熵 属性outlook:有三个取值{sunny,overcast,rainy}分别为 sunny-----5个:其中目标属性yes:2个,no:3个 overcast—4个:其中目标属性yes:4个,no:0个 rainy—---5个:其中目标属性yes:3个,no:2个 因此
按照属性outlook来划分S后的熵及信息增益为:
同理按照属性temperature、humidity 和windy 来划分S 后的熵和信息增益分别为:
③ 比较以上几个属性的信息增益可知,按outlook 属性来划分获得的信息增益最大,因此选择outlook 属性作为树的根节点的划分属性。 ④ 按照其他三个属性对outlook中的sunny进行划分,计算步骤同①②两步。计算过程如下:H(S1)=0.9710
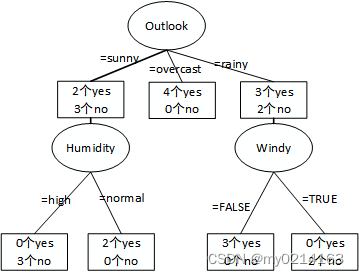
由此可见sunny分支中按照humidity 属性进行划分的信息增益最大,所以outlook的sunny分支选择humidity 作为划分属性,并且不再需要继续划分节点。 ⑤ 对outlook中overcast分支划分后的子节点已经是纯的,因此不再需要继续划分节点。 ⑥ 按照④中同样的方式对outlook中rainy分支进行划分。最后计算得出按照windy 属性划分得到的子节点完全是纯的,因此,对outlook中rainy分支选择windy 作为划分属性,并且不再需要继续划分节点。 ⑦ 最终得到的决策树如下图所示:
实现决策树的可视化: 首先加载天气数据集,将训练数据集属性与目标属性从数据集中分别用train与traintargets存储,接着调用ID3函数构建决策树模型,然后对测试样本进行分类,最后算出预测天气问题结果的正确率。其中ID3函数中先用buildTree函数构建决策树,再用plotTree函数绘制决策树,最后用classifyTree函数使用训练好的决策树对未知样本分类。 代码如下: load('weatherNominal.mat'); train = table(weather.(1), weather.(2), weather.(3), weather.(4), 'VariableNames', {'outlook' 'temperature' 'humidity' 'windy'}); traintargets = weather.(5); test = train; testtargets = traintargets; canplay = ID3(train, traintargets, test); disp('天气问题结果'); correct = sum(canplay == testtargets ) / length(canplay); fprintf('正确率为:%3.1f%%\n', correct * 100);实验结果如下:
|
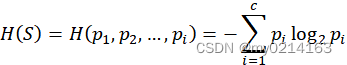
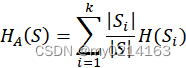


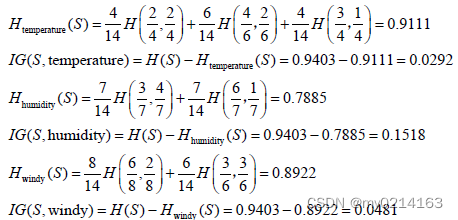



【本文地址】