| Python爬虫要违法了?放心的告诉大家:守住规则,大胆去爬 | 您所在的位置:网站首页 › 站点抓取违法吗现在 › Python爬虫要违法了?放心的告诉大家:守住规则,大胆去爬 |
Python爬虫要违法了?放心的告诉大家:守住规则,大胆去爬
|
最近我学习和实践网络爬虫,总想着在这儿抓点数据在那儿抓点数据。 但不知为什么,抓取别人网站数据时,总会产生莫名恐慌生怕自己一不小心就侵权了,然后被关在监狱摩擦
所以我想现在这个时候,非常有必要仔细研究一下有关网络爬虫的规则和底线。 我们生活中几乎每天都在爬虫应用,如百度,你在百度中搜索到的内容几乎都是爬虫采集下来的(百度自营的产品除外,如百度知道、百科等),所以网络爬虫作为一门技术,技术本身是不违法的。 哪些情况下网络爬虫采集数据后具备法律风险? 当采集的站点有声明禁止爬虫采集或者转载商业化时;比如淘宝网,大家来看淘宝的声明。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉爬虫哪些页面可以抓取,哪些页面不能抓取。 robots.txt文件是一个文本文件,使用任何一个常见的文本编辑器,比如Windows系统自带的Notepad,就可以创建和编辑它。robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 如何查看采集的内容是的有rebots协议? 其实方法很简单。你想查看的话就在IE上打http://你的网址/robots.txt要是说查看分析robots的话有专业的相关工具 站长工具就可以! 爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁止,但是利用爬虫技术获取数据这一行为是具有违法甚至是犯罪的风险的。
举个例子:像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是像抢票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不觉得很开心,这种就被定义为“恶意爬虫”。 爬虫所带来风险主要体现在以下3个方面: 违反网站意愿,例如网站采取反爬措施后,强行突破其反爬措施;爬虫干扰了被访问网站的正常运营;爬虫抓取了受到法律保护的特定类型的数据或信息。解释一下爬虫的定义:网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。 网络爬虫抓取的数据有如下规则: 数据完全公开不存在也无法做到越权访问爬取常见错误观点:认为爬虫就是用来抓取个人信息的,与信用基础数据相关的。 总的来说,技术本无罪,但是你利用技术爬取别人隐私、商业数据,那你就是蔑视法律了 最后为了帮助大家更好的学习Python,小编给大家准备了一份Python学习资料,里面的内容都是适合零基础小白的笔记和资料,不懂编程也能听懂、看懂,需要获取方式:扫描下方即可获取。
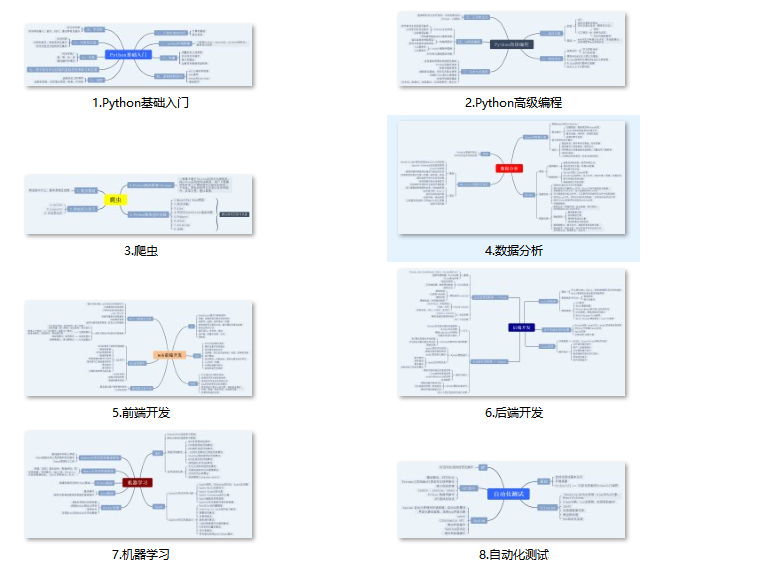
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
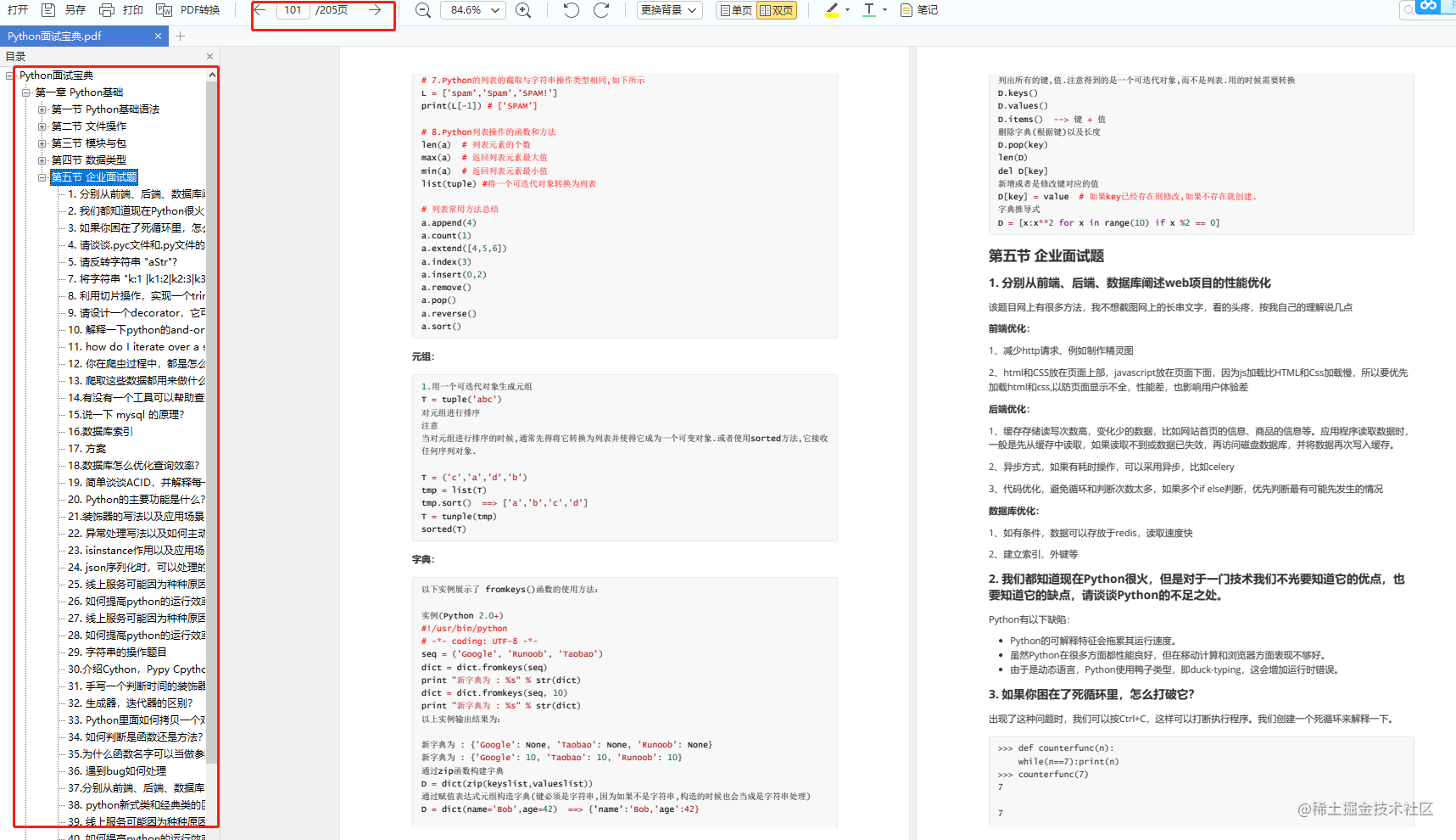
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。 温馨提示:篇幅有限,已打包文件夹,获取方式:点击这里【 Python全套资料】 或扫描下方即可获取。 👉Python学习视频600合集👈观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
获取方式:点击这里【 Python全套资料】 或扫描下方即可获取。
|





【本文地址】