| Redis系列 | 您所在的位置:网站首页 › 空间均衡性是什么意思 › Redis系列 |
Redis系列
|
目录
1. 数据分片1.1. 哈希算法1.1.1. 优点1.1.2. 缺点
1.2. 一致性哈希算法1.2.1. 优点1.2.2. 缺点
1.3. 范围算法1.3.1. 优点1.3.2. 应用场景
1.4. 虚拟哈希槽算法1.4.1. 优点1.4.2. 缺点
1.5. 总述
2. 架构演进2.1. Replication+Sentinel2.1.1. 架构图2.1.2. 工作原理2.1.3. 缺点
2.2. Proxy+Replication+Sentinel2.2.1. 架构图2.2.2 工作原理2.2.3. 缺点
2.3 Redis Cluster2.3.1 架构图2.3.2. 工作原理2.3.3. 优点2.3.4. 缺点
3. 面试问题3.1. 懂Redis事务么?3.2. Redis的多数据库机制3.3. Redis集群机制中,你觉得有什么不足的地方吗?3.4. 懂Redis的批量操作么?3.5. 那在Redis集群模式下,如何进行批量操作?3.6. 你们有对Redis做读写分离么?3.7. Redis Cluster间的节点怎么通信?3.8. 为什么Redis Cluster的hash slot为16384个?
1. 数据分片
集群的本质其实就是数据分片,也就是所谓的 Sharding。为了使得集群能够水平扩展,首要解决的问题就是如何将整个数据集按照一定的规则分配到多个节点上,常用的数据分片的方法有:范围分片,哈希分片,一致性哈希算法和虚拟哈希槽等。 1.1. 哈希算法hash算法分片最为简单,是通过hash函数对key进行处理,然后分配在某个partition中,partition 最终又会通过一定的映射规则最终落在machine上。因此当需要查询一个key的value时,要经过key-partition的映射表和partition-machine的映射表去两次寻址,从而实现路由寻址。 一句话概括就是利用hashcode进行简单寻址和存储 1.1.1. 优点 精准查询性能极高,查询效率我O(1)因此常用在分布式系统的路由寻址中 1.1.2. 缺点 范围查询很慢,因为每个key都需要单独寻址无法用在存储系统中,因为用做存储系统时,增删节点困难,可用性低。假设我们有三台缓存服务器,用于缓存图片,我们为这三台缓存服务器编号为 0号、1号、2号,现在有3万张图片需要缓存,我们希望这些图片被均匀的缓存到这3台服务器上,以便它们能够分摊缓存的压力。也就是说,我们希望每台服务器能够缓存1万张左右的图片,那么我们应该怎样做呢?常见的做法是对缓存项的键进行哈希,将hash后的结果对缓存服务器的数量进行取模操作,通过取模后的结果,决定缓存项将会缓存在哪一台服务器上 hash(图片名称)% N 当我们对同一个图片名称做相同的哈希计算时,得出的结果应该是不变的,如果我们有3台服务器,使用哈希后的结果对3求余,那么余数一定是0、1或者2;如果求余的结果为0, 就把当前图片缓存在0号服务器上,如果余数为1,就缓存在1号服务器上,以此类推;同理,当我们访问任意图片时,只要再次对图片名称进行上述运算,即可得出图片应该存放在哪一台缓存服务器上,我们只要在这一台服务器上查找图片即可,如果图片在对应的服务器上不存在,则证明对应的图片没有被缓存,也不用再去遍历其他缓存服务器了,通过这样的方法,即可将3万张图片随机的分布到3台缓存服务器上了,而且下次访问某张图片时,直接能够判断出该图片应该存在于哪台缓存服务器上。 缺陷:如果服务器已经不能满足缓存需求,就需要增加服务器数量,假设我们增加了一台缓存服务器,此时如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,最终导致所有缓存的位置都要发生改变,也就是说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据;同理,假设突然有一台缓存服务器出现了故障,那么我们则需要将故障机器移除,那么缓存服务器数量从3台变为2台,同样会导致大量缓存在同一时间失效,造成了缓存的雪崩,后端服务器将会承受巨大的压力,整个系统很有可能被压垮。为了解决这种情况,就有了一致性哈希算法。 1.2. 一致性哈希算法hash算法就是为了精准查询,所以精准查询不是优化方向,可优化的方向就是如何优雅的增删节点。即一致性哈希算法。 一致性哈希算法也是使用取模的方法,但是取模算法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模(之所以是2 ^ 32是因为hashcode最多是2 ^ 32),具体步骤如下: 步骤一:哈希环的组织,一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环; 我们将 2 ^ 32 想象成一个圆,像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由2 ^ 32个点组成的圆,示意图如下: 步骤二:确定服务器在哈希环的位置,接着将各个服务器使用 Hash 函数进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置 哈希算法:hash(服务器的IP) % 2^32 上述公式的计算结果一定是 0 到 2^32-1 之间的整数,那么上图中的 hash 环上必定有一个点与这个整数对应,所以我们可以使用这个整数代表服务器,也就是服务器就可以映射到这个环上,假设我们有 ABC 三台服务器,那么它们在哈希环上的示意图如下: 步骤三:将数据映射到哈希环上,最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器 我们还是使用图片的名称作为 key,所以我们使用下面算法将图片映射在哈希环上:hash(图片名称) % 2^32,假设我们有4张图片,映射后的示意图如下,其中橘黄色的点表示图片: 总结起来,其实就是将写入不再直接与hash算法绑定,而是引入顺序查找的方法,损失部分写入性能,换取优雅增删节点。 1.2.1. 优点优雅的增删节点 如果简单对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存的雪崩,从而很有可能导致系统崩溃,而使用一致性哈希算法就可以很好的解决这个问题,因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性。 假设服务器B出现了故障,需要将服务器B移除,那么移除前后的示意图如下图所示: hash环的倾斜与虚拟节点 一致性哈希算法在服务节点太少的情况下,容易因为节点分部不均匀而造成数据倾斜问题,也就是被缓存的对象大部分集中缓存在某一台服务器上,从而出现数据分布不均匀的情况,这种情况就称为 hash 环的倾斜。如下图所示: 理解点查询和范围查询 为点查询和范围查询增加分片层 在hash分片中,通过hash函数处理后,一般有序的多个Key,会被存放在多个分片中,尤其是相邻的Key大概率不在同一分片中。 此时会发现查询涉及到的Key越多,查询分片也会越多,如果此时能减少查询分片的数量,在key-parititon映射的效率也会变高 将已有的三个分片进行重组 将3个分片按照Key的顺序进行拆分重组,分片a(包含Key1、Key(n-1))、分片h(包含Key2)、分片m (包含Keyn)重组为分片a(包含Key(n-1))、分片m(包含Keyn)、新分片x(包含Key1和Key2),当然这里如果所有Key都是连续,合并成一个分片当然是最理想的情况。我们在这个示例的基础上向外延伸,分片拆分合并有什么好处? 无序变有序,针对原本多个无序的分片,按照一定规则,将相近的Key进行合并,之前连续的Key需要在多个分片中查找,而现在可以减少查找的范围,只需要在少量分片中进行查找,提升查询的效率。 优化路由表 将Key-Partition由4条元数据(Key1->分片a,Key2 ->分片h,Key(n-1)->分片a,Keyn ->分片m)缩减为3条(Key1->新分片x),Key(n-1)->分片a,Keyn-分片m),原来4条元数据缩减成3条,由密集索引转化为稀疏索引。什么是密集索引和稀疏索引呢? 同样的将每个Key的分片位置都记录路由表中进行索引的方式叫做密集索引,而路由表优化后,由于Key是有序的,因此只需要记录Key1->新分片x即可,此时在新分片x中就可以找到Key2。这种索引类型叫做稀疏索引。 上面我们针对分片层进行拆分合并,并且对路由表的元数据进行索引类型转换,更适合于连续Key的范围查询,所以在范围数据寻址效率上,点查询相比于范围查询,可以简单理解成达到了1+1 |
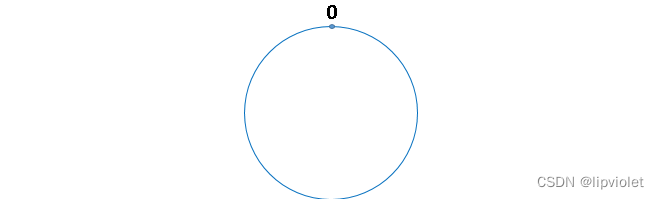 圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2 ^ 32-1,也就是说0点左侧的第一个点代表2 ^ 32-1,我们把这个由 2 ^ 32 个点组成的圆环称为hash环。
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2 ^ 32-1,也就是说0点左侧的第一个点代表2 ^ 32-1,我们把这个由 2 ^ 32 个点组成的圆环称为hash环。
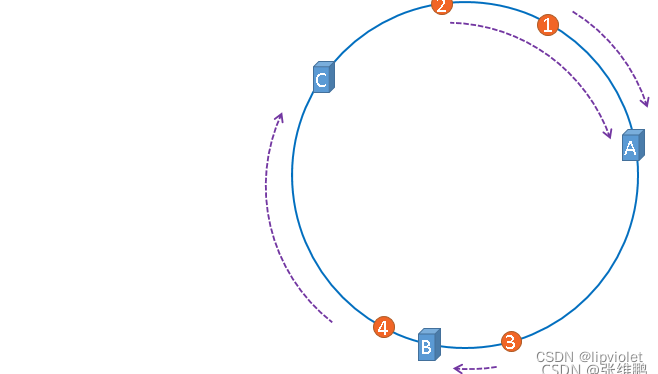 那么,怎么算出上图中的图片应该被缓存到哪一台服务上面呢?我们只要从图片的位置开始,沿顺时针方向遇到的第一个服务器就是图片存放的服务器了。最终,1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
那么,怎么算出上图中的图片应该被缓存到哪一台服务上面呢?我们只要从图片的位置开始,沿顺时针方向遇到的第一个服务器就是图片存放的服务器了。最终,1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。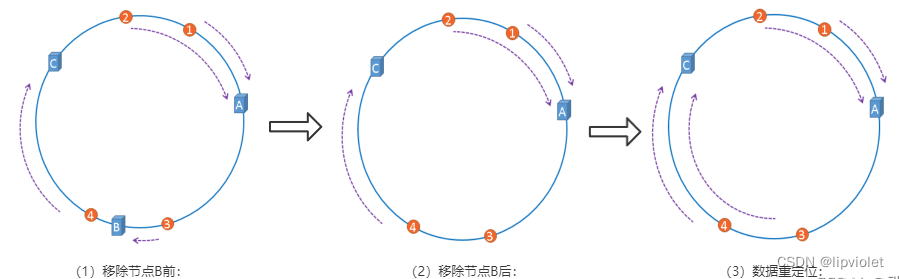 在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变,但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点。
在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变,但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点。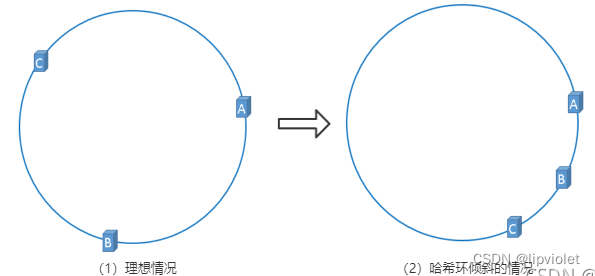 hash 环的倾斜在极端情况下,仍然有可能引起系统的崩溃,为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。具体做法可以在服务器ip或主机名的后面增加编号来实现,加入虚拟节点以后的hash环如下:
hash 环的倾斜在极端情况下,仍然有可能引起系统的崩溃,为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,一个实际物理节点可以对应多个虚拟节点,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,hash环倾斜所带来的影响就越小,同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射。具体做法可以在服务器ip或主机名的后面增加编号来实现,加入虚拟节点以后的hash环如下: 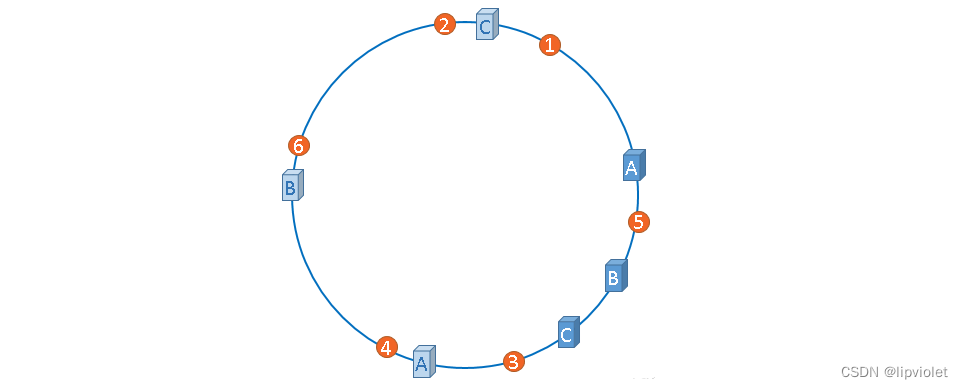
 如上图所示,点查询和范围查询的关系一句话概括,多个有序的点查询约等于范围查询 之所以说是“约等于”,在这种理解上,范围查询只是点查询的封装,每次范围查询,依然会进行多次寻址,因此并没有本质的变化,如果每次Key查询计数为1(实际上每次key查询代表两次寻址)的话,点查询和范围查询可以解释成1+1=2的关系。
如上图所示,点查询和范围查询的关系一句话概括,多个有序的点查询约等于范围查询 之所以说是“约等于”,在这种理解上,范围查询只是点查询的封装,每次范围查询,依然会进行多次寻址,因此并没有本质的变化,如果每次Key查询计数为1(实际上每次key查询代表两次寻址)的话,点查询和范围查询可以解释成1+1=2的关系。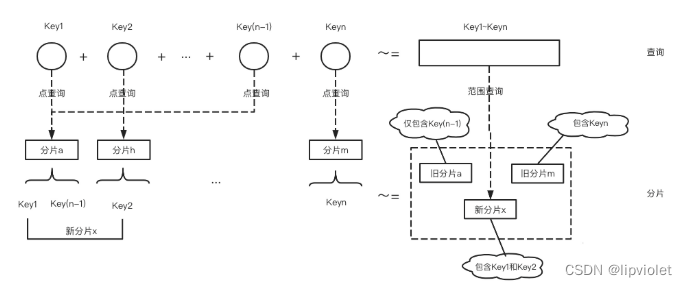 我们将Key1对应的分片定为分片a,Key2对应的分片定为分片h,Key(n) 对应分片m,在hash分片模型中会存在多个Key通过hash函数存放于同一个分片中的情况,这里以Key(n-1)对应分片a 进行举例。4个Key在hash分片进行Key-Partition查询时,实际上会路由到3个分片中。此时我们进行两个操作:
我们将Key1对应的分片定为分片a,Key2对应的分片定为分片h,Key(n) 对应分片m,在hash分片模型中会存在多个Key通过hash函数存放于同一个分片中的情况,这里以Key(n-1)对应分片a 进行举例。4个Key在hash分片进行Key-Partition查询时,实际上会路由到3个分片中。此时我们进行两个操作: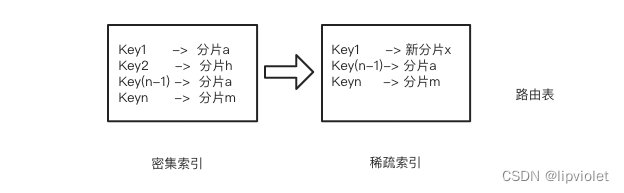 在路由分片模型中,KeyPartition映射一般是通过路由表来实现的(实际上一致性hash也是另类的路由表,只不过没有固化成index的结构,需要每次计算),在路由表中每个Key都会有其路由到分片的位置,即Key1 ->分片a,Key2->分片h,Key(n-1) ->分片a等。
在路由分片模型中,KeyPartition映射一般是通过路由表来实现的(实际上一致性hash也是另类的路由表,只不过没有固化成index的结构,需要每次计算),在路由表中每个Key都会有其路由到分片的位置,即Key1 ->分片a,Key2->分片h,Key(n-1) ->分片a等。【本文地址】