| 用RDMA重新思考有状态流处理 | 您所在的位置:网站首页 › 稻草人背景介绍 › 用RDMA重新思考有状态流处理 |
用RDMA重新思考有状态流处理
|
摘要
远程直接内存访问 (RDMA) 硬件弥合了网络和主要内存速度之间的差距,从而验证了网络通常是分布式数据处理系统中的瓶颈的常见假设。然而,高速网络并没有提供“即插即用”的性能(例如,使用 IP-overInfiniBand),并且需要仔细共同设计系统和应用逻辑。因此,系统设计者需要重新思考其数据管理系统的架构,以从 DMA 加速中受益。 在本文中,我们专注于加速流处理引擎,这受到实时约束和状态一致性保证的挑战。为此,我们提出了 Slash,这是一种新颖的流处理引擎,它使用高速网络和 RDMA 来有效地执行分布式流计算。Slash 包含一个适用于 RDMA 加速的处理模型,并通过省略大规模 SPE 的昂贵数据重新分区需求来进行扩展。虽然 scale-out SPE 依赖于数据重新分区来执行对许多节点的查询,但 Slash 使用 RST 在节点之间共享可更改状态。总体而言,与部署在不定式网络上的现有系统相比,Slash 实现了高达两个数量级的吞吐量改进。此外,它比依赖基于 RST 的数据重新分区以扩展查询处理的自开发解决方案快 22 倍。 1 介绍在过去的十年中,数据中心网络技术的进步弥合了网络和主要内存数据率之间的差距 [9, 25]。事实上,今天可以购买或租提供超级计算机级网络带宽的服务器 [ 45]。例如,高速网络接口控制器 (NIC) 支持高达 25 GB/s 作为网络吞吐量和每个端口 600 ns 延迟,而现代开关支持多达 40 TB/s 作为整体网络吞吐量 [44]。双数据速率 4 (DDR4) 模块支持每个通道高达 19.2 GB/s 和 13 个 CAS 延迟,而主要内存带宽高达 24.8 GB/s [ 3 ]。这种改进是由于远程直接内存访问 (RDMA):可以实现高吞吐量数据传输的高速网络的功能微秒延迟。因此,网络通常是分布式设置中的瓶颈的常见假设不再成立[60]。研究表明,RDMA硬件不能为现有的数据管理系统[9]提供“即插即用”的性能增益。因此,有必要修改他们的架构来使用全带宽[9]。最近的研究提出了许多架构修订来加速 OLAP [9, 40]、OLTP [69]、索引 [74] 和键值存储 [19, 31],在机架级部署中使用 RDMA。在本文中,我们使得流处理引擎 (SPE) 也需要架构更改才能真正受益于 RDMA 硬件的情况。为此,我们表明当前的向外扩展 SPE 没有准备好用于 RDMA 加速,并且现有的 RDMA 解决方案不适合流处理范式。因此,我们提出了一种与 RDMA 本地集成的 SPE 架构,以有效地摄取和处理机架级部署中的数据。 当前 SPE,例如 Apache Flink [ 11 ]、Storm [58 ]、TimelyDataflow [47) 和 Spark [68 ],不能完全受益于 RDMA 硬件。由于以下原因,他们的设计选择从根本上阻止他们以全数据中心网络速度处理数据。首先,RDMA-unfriendly,当前的 SPE 依赖于基于套接字的网络,例如 CP/IP,摄取和交换数据流。尽管基于套接字的网络在 RST 硬件上运行,但它无法充分利用其潜力,例如,使用 IP-over-InfiniBand (IPoIB) [9]。其次,昂贵的消息传递,当前的 SPE 依赖于消息传递来处理遵循类似 Map/Reduce 的范式 [16 ] 的数据。这导致了性能回归,因此在由次优数据和代码局部性引起的低效执行 [ 70, 71]。特别是,消息传递在网络和数据处理线程之间引入了昂贵的基于队列的同步 [30]。此外,在考虑数据密集型工作负载时,类似 Map/Reduce 的范式是基于相对较慢的基于插槽的连接的网络绑定。然而,它们在存在快速网络的情况下成为计算界限 [9, 60]。因此,它们不会从高速网络的数据率中受益。最后,昂贵的大规模执行,当前的缩放 SPE 依赖于算子裂变 [27 ] 来实现数据并行计算。这使每个 SPE 执行器能够处理流的不相交分区并管理本地状态。然而,裂变涉及连续数据重新分区,它以高成本 [17]。 此外,上述问题无法通过以前的数据密集型系统的 RST 解决方案来解决。事实上,SPE 需要对航班内记录进行状态分析,并对操作员状态进行点更新和范围扫描。然而,在不可变数据集上加速 OLAP 系统加速批量分析 [7, 20, 40,5}。对于包括点查找和插入 [1, 31] 在内的事务工作负载,基于 RST 的键值存储是设计的。因此,SPE 的数据访问模式和处理模型需要专门的 RD-加速解决方案。 为了在延迟非常低的全网络带宽上实现有状态流处理,我们提出了Slash,这是我们用于机架级部署的RDMA加速SPE。我们设计了一个新的架构来实现一种省略数据重新分区的处理模型,并在摄取的流上应用有状态查询逻辑。Slash 包括以下构建块:RDMA Channel、有状态查询执行器和 Slasash State Backend (SSB)。首先,我们设计了一个 RDMA 友好的协议,通过专用的 RDMA 数据通道支持节点之间的流。这使得Slash能够利用所有NIC的聚合带宽,以完整的RDMA网络速度在节点之间执行数据摄取和数据交换。其次,我们设计了一个有状态执行器,它省略了消息传递,并在后期合并技术[70]之后运行查询。最后,我们用 SSB 替换重新分区,从而实现跨分布式节点的一致状态共享。这使得多个节点能够同时更新状态的相同键值对(例如,一组窗口聚合)。为了确保一致性,我们引入了一个基于 epoch 的协议来懒惰地使用 RDMA 同步状态更新。 总体而言,Slash 执行器通过在数据流上急切应用有状态运算符来计算部分状态来扩展计算。为此,执行器将部分状态存储到SSB中,这确保了所有Slash执行器的状态一致视图。我们对常见流工作负载的评估表明,Slash 优于基于数据重新分区的基线方法,并且与偏斜无关。特别是,我们将 Slasash 与 IPoIB 网络上的 scale-out SPE (Apache Flink) 进行比较,IPoIB 网络上的 scale-up SPE 称为 LightSaber 的 scale-up SPE 和一个名为 RDMA UpPar 的自行开发的稻草人解决方案,它通过基于 RDMA 的数据重新分区扩展查询执行。Slash 的吞吐量分别比 RDMA UpPar 和 LightSaber high 25 倍和 11.6 倍。此外,Slash 通过实现一个数量级的吞吐量优于 Flink。总体而言,这表明仅 RDMA 不能在不重新设计 SPE 内部的情况下实现峰值性能。 在本文中,我们做出了以下贡献: 为了原生集成高速 RDMA 网络,我们提出了 Slasash,这是一种新颖的 RDMA 加速 SPE。我们设计了一个有状态查询执行器,以在 RDMA 网络上进行 Slasash 向外扩展数据流处理。我们为 Slasash 定义了一个 RDMA 流协议,以使用 RDMA 通道以线速率传输数据。我们构建了 SSB,可以在 RDMA 互连上实现分布式一致状态。我们在高端 RDMA 集群上的公共流基准上验证了 Slasash 的设计,并表明比我们最强的基线提高了 25 倍的吞吐量。我们将本文的结构如下。在第 2 节中,我们介绍了有关 RDMA 和数据流处理的背景概念。在第 3 节中,我们对 SPE 进行了 RDMA 加速的情况,并列出了挑战和机遇。在第 4 节中,我们介绍了 Slasash 的系统架构,并提供了每个组件的概述。之后,我们描述了有状态执行器(第 5 节)、RDMA 通道(第 6 节)和 SSB(第 7 节)。然后,我们在第8节中对Slash进行了广泛的评估。我们在第9节中描述了SPEs和支持rdma的数据库系统领域的相关工作。最后,我们总结了本文的研究结果,并讨论了第10节中未来工作的想法。 2 背景在本节中,我们将为我们的论文提供背景。我们在第2.1节中描述了RDMA,并在第2.2节中概述了流处理的当前方法。 2.1 远程直接内存访问 RDMARDMA是由Infiniband (IB)、RoCE (RDMA在收敛以太网上)和iWarp (Internet广域RDMA协议)网络[32]提供的通信堆栈。RDMA 能够以最少的远程 CPU 参与访问远程节点的主要内存。因此,RDMA 实现了高带宽(每个端口 [43] 高达 200 Gbps)和低延迟(每轮往返 [32] 高达 2μs)。RDMA 通过零拷贝提供双向数据传输,绕过了内核网络堆栈。相比之下,基于套接字的协议,如TCP,涉及用户和内核空间[9]之间昂贵的系统调用和数据副本。RDMA 支持的 NIC 还通过 IP-over-InfiniBand (IPoIB) 支持基于套接字的通信。然而,这种方法会导致较低的效率[9]。RDMA 为通信提供了两个 API(所谓的动词):单边和双边动词 API [32]。此外,RDMA 提供了可靠、不可靠和数据报连接。可靠的连接使单边动词和有序数据包传递成为可能,而不可靠和数据报连接可能会丢弃数据包。使用双边动词(Send-Recv),发送方和接收方积极参与通信。接收方轮询传入消息,这需要 CPU 参与。相比之下,单边动词涉及一个主动发送者和一个被动接收者(RDMA WRITE)或被动发送者和一个主动接收者(RDMA READ)。它们可以实现更有效的数据传输,但需要同步来检测入站的消息。 RDMA 提供了两个主要好处:它 1) 可以实现快速数据传输,以及 2) 在节点之间共享内存区域 []。但是,启用 DMA 的系统需要仔细设计,因为 RST 不提供本地内存和远程内存之间的连贯性。相反,这转移到了应用程序中。此外,NIC 内存、主要内存和 CPU 之间的一致性取决于供应商 [ 9]。动词和参数的选择,例如消息大小,是应用程序敏感的,需要仔细调整 [32]。 2.2 有状态流处理引擎最近的 SPE(流处理引擎)使用放大或缩小的处理模型。Scaleup SPE 专注于单节点效率,而 scale-out SPE 的目标是集群可扩展性。放大spe,如LightSaber[56]、BriskStream[72]和Grizly[23],针对多套接字多核cpu的单节点部署。向外扩展 SPE,例如 Flink [11]、Storm [58]、Spark Streaming [68]、Millwheel [4]、Google Dataflow [5] 和 TimelyDataflow [47],对无共享架构并行化查询。Scale-up 和 scale-out SPE 假设公共数据和查询模型,但它们以不同的方式执行查询。我们在下面总结了它们的数据、查询和处理模型。 数据和查询模型。我们遵循 Fernandez 等人介绍的定义。[ 12 ] 并假设数据流由不可变、无界的记录组成。记录包含时间戳 t、主要密钥 k 和一组属性。时间戳是严格单调递增的,用于窗口相关操作以及进度跟踪。流查询被建模为有向无环图,其中有状态运算符作为顶点,数据流为边缘。流运算符的输出取决于输入记录的内容、时间戳或到达顺序及其中间状态。一般来说,运算符必须在时间戳 𝑡 处输出没有结果,该时间戳是使用时间戳大于 𝑡 的记录计算的。 大规模执行。Scale-up SPE 依赖于基于任务的并行化、基于编译的算子融合 [ 27 ] 和后期合并 [ 70 ] 来充分利用可用的硬件资源。逻辑运算符合并在一起并编译到机器代码中,SPE 使用基于任务的并行化在绑定数据缓冲区上执行。任务可以同时更新全局运算符状态或急切更新本地状态,SPE 最终合并并确保其一致性。 向外扩展执行。Scale-out SPE 使用操作员到线程的并行性和数据重新分区 [27] 来向外扩展。每个逻辑运算符由 Jordan 物理运算符组成,其中 SPE 在一组节点上并行运行。Scale-out SPE 重新分区输入流,以便每个物理运算符对数据的不相交分区应用有状态转换。这可以通过局部可变状态[10]实现一致的状态计算。并行实例通过遵循交换模式的内存或基于网络的数据通道从上游操作符接收记录。 3 RD-ACCELERATED STATEFUTURE 流程案例在本节中,我们将针对基于 RDMA 的有状态流处理工作负载加速的情况。为此,我们分析了使用 RDMA 网络(第 3.1 节)共同设计 SPE 的选项,并得出了需要解决的设计挑战(第 3.2 节)。之后,由我们的分析驱动,我们提出了 Slasash 的系统架构(第 4 节)。 3.1 RDMA 集成先前的研究提出了将 RDMA 集成到通用数据管理系统中的三种通用方法 [ 9]。在下文中,我们分析了它们对 SPE 的适用性以及这些设计决策背后的暗示。 即插即用的集成。在这种方法中,无共享系统的部署发生在 IPoIB 网络上。先前的研究表明,它不一定会导致性能改进[9]。特别是,IPoIB不会饱和网络带宽,并为小消息[9]引入CPU开销。在我们的评估中,我们表明当前 SPE 的查询执行仅使用 IPoIB 略有改进。 轻量级集成。这种方法涉及用 RDMA 动词替换基于套接字的网络。虽然它受益于高网络带宽,但它仍然受到原始设计中存在的瓶颈[9,32,70]。我们通过构建一个实现轻量级方法的稻草人解决方案来验证这一主张。特别是,我们实施和评估使用 RDMA QP 而不是sockets[40]。请注意,一些 SPE,例如 Apache Flink 和 TimelyDataflow,利用数据重新分区来并行化运算符,从而扩展计算。我们将本文其余部分的方法称为 RDMA UpPar。请注意,轻量级集成引起的性能回归不依赖于底层的运行时或语言。因此,我们在 C++ 中实现 RDMA UpPar 以省略托管的运行时开销,并表明性能回归是由于整体 SPE 设计。 原生整合。先前的研究表明,集成最有效的选择是与 RDMA 协同设计软件组件 [9, 32, 69 , 74]。对于数据管理系统,这种方法涉及重新设计其内部,例如存储管理和查询处理,以消除网络瓶颈。值得注意的是,在存在高数据速率和慢速网络[60]的情况下,向外扩展SPE的数据重新分区组件是网络界。此外,最近的研究表明,在高带宽存在的情况下,数据重新分区由于其次优的CPU利用率,在向外扩展spe中负责性能回归[70]。这表明 SPE 必须重新考虑其向外扩展计算模型并评估数据重新分区的替代方案,以完全受益于 RDMA 加速。我们将本文其余部分的方法称为 Slasash。 在本文中,我们专注于原生方法,并在设计 RST 加速 SPE 时讨论必要的架构和算法变化。此外,我们针对即插即用和轻量级集成评估本地解决方案的性能。 在上一节中,我们制作了本地 RDMA 集成的情况,它承诺峰值性能,但需要更改向外扩展 SPE。在本节中,我们分析了本地 RDMA 加速带来的设计挑战和影响。 C1:高效的流计算。除了高通量的数据传输外,基于 RST 的系统还实现了高效的解耦处理模型:存储和计算节点以字节级粒度相互访问的内存 [ 9 , 31 , 40 , 69, 74]。在这个模型中,不需要为数据并行处理进行昂贵的数据重新分区,因为每个节点都可以访问来自任何远程内存位置的数据。因此,我们确定第一个设计挑战,以支持分布式流计算的高效处理模型,该模型受益于字节级粒度的内存访问。这涉及用性能友好、基于 RST 的处理策略替换重新分区策略。 C2:高效的数据传输。在 SPE 中,数据通道必须在网络上运算符之间进行有效的数据传输。但是,DMA 提供了几种网络传输功能,这些功能在吞吐量和延迟之间引入了许多设计选择和权衡。例如,单边动词实现了比双边动词更低的网络延迟,尤其是在最近的 NIC 上 [ 19 , 30 ,48)。Rama READ 涉及一个完整的网络往返,因此比 DMA WRITE [ 32] 具有更高的延迟。此外,巨大的页面、流水线、仅头消息和选择性信号等技术进一步提高了性能 [ 9 , 32]。据我们所知,在流处理工作负载 [65, 70] 上没有对 RST 功能进行全面分析。结果,我们确定作为第二个设计挑战,选择 DMA 能力以低延迟实现高通量的流处理。 C3:一致的状态计算。SPE需要确保一致的有状态计算。因此,RDMA 加速 SPE 必须始终管理状态,同时处理传入的记录。这涉及跟踪分布式计算,同时确保完全一次的状态更新。因此,我们确定了第三个设计挑战,以实现使用 RDMA 访问共享数据结构的有状态流算子的一致性保证。 总体而言,没有系统可以完全解决上述设计挑战,以 DMA 速度实现有状态流处理。因此,我们将在下一节中提出 Slash 作为弥合 RST 加速和流处理之间差距的解决方案。
图 2:Slash 将包含过滤器的查询和基于时间的窗口运算符转换为管道(绿色和紫色形状)。Slash 在其实例上执行每个管道。左管道更新分布式窗口状态。右管道触发窗口并读取分布式状态。 C2。最后,Slash 的分布式状态后端通过为 RDMA 量身定制的一致性协议通过一致的状态管理来解决 C3。 4 系统设计Slasash 的架构包括三个组件,以实现稳健的流处理:有状态执行器 1、RDMA 通道 2 和 Slasash State 后端 3。图 1 显示每个节点执行 Slasash 有状态执行器的一个实例 (a 过程),它使用 RDMA 通道读取和写入流记录,应用运算符逻辑并将中间状态存储到状态后端。 有状态的执行程序。Slasash(第 5 节)有状态执行器的指导原则是在利用 RDMA 加速时使常见情况快速。为此,Slash 执行器遵循基于急切计算部分状态的惰性合并的松弛处理模型。这类似于基于后期合并的放大 SPE 的执行模型。但是,Slash 使用 RDMA 在集群级别执行合并。为了避免昂贵的数据重新分区,Slash 执行器急切地计算流物理数据流上的部分状态此外,Slash 执行器使用我们的基于 RDMA 的组件懒惰地合并部分、分布式状态和输出一致结果:SSB 和 RDMA 通道。我们使用 RDMA 加速来设计高效的分布式算法和数据结构,可以在字节级粒度上实现快速、连贯的内存访问。 RDMA 通道。Slash RDMA 通道(第 6 节)是通过 RDMA 共享循环队列以亚毫秒延迟的全线速率发送和接收记录的数据通道。使用 RDMA 语义从/写入发送方和接收方读取/写入队列。与基于套接字的 RDMA 通道相比,我们的 RDMA 通道可以实现更高的吞吐量传输和零拷贝语义。我们使用 RDMA 通道在 RDMA UpPar 中实现数据重新分区以及 Slasash 的通信原语。 斜杠状态后端。SSB 是一个分布式状态后端(第 7 节),它在多个节点的聚合内存中维护操作员状态。我们为常见的流处理用例设计了分布式状态后端:更新密集型工作负载,以及快速触发和后处理飞行窗口[13]。与允许与输入流共分区的局部可变状态的传统方法相比,我们的状态后端可以使用 RDMA 实现分布式可变状态。因此,Slash 执行器可以一致且同时更新分布式状态的键值对,进而启用惰性执行。 总体而言,Slash stateful 执行器处理 C1,并使用基于 RST 的构建块实现高效但一致的处理模型。DMA 通道支持快速网络传输和地址 5 Slash 有状态的执行者在本节中,我们将介绍Slash处理模型(第5.1节),并讨论与执行相关的方面:支持的流操作符(第5.2节)和并行执行(第5.3节)。 5.1 处理模型Slash 的有状态执行器将数据并行转换应用于数据流的物理分区数据流。因此,Slash 在集群的节点上并行运行同一运算符的多个实例。Slash 不假设数据流在逻辑上被划分为主键,因此键可能出现在多个数据流中。 图 2 描述了 Slasash 的有状态处理模型。Slasash支持无状态和有状态的连续操作符作为操作符管道,这与最近的流处理扩展方法[23,36,56,70]一致。每个管道都使用软管道断路器终止,例如窗口触发算子 [23, 56],如图 2 所示。然而,Slash 扩展了后期合并的放大方法以支持向外扩展。为此,Slash 在一组节点(通过 RDMA)之间共享运算符状态,并省略数据重新分区。Slash 不执行数据重新分区,例如,没有基于散列的重新分区。因此,运算符立即更新共享的可变状态,这在 SSB 的 Slasash 实例中保持一致。此外,管道的并行程度由其输入数据流的数量绑定。 状态和计算一致性涉及两个属性。P1)Slash 不得在时间戳 푡 处输出任何结果,该结果是使用时间戳大于 푡 的记录计算的。P2) Slash 中数据流 ¢ 的分布式计算必须在顺序计算将产生处理 ¢ 的相同输出中懒惰合并后产生。下面我们将讨论我们如何实现这些属性。 进度跟踪。Scale-out SPE依赖于重新分区和带内或带外进度跟踪,以关键为基础触发事件时间窗口[10,47]。Slash 省略了数据重新分区,这给整体分布式计算的进展跟踪带来了挑战。事实上,省略数据重新分区的向外扩展SPE的实例必须协调以检测窗口终止并合并部分窗口。为了满足P1,Slash依赖于矢量时钟[39]。每个Slash执行程序푡跟踪每个窗口푝的最低水印푡,푡:更新窗口的记录的最大事件时间时间戳。在惰性合并后,Slash 执行器通过 RDMA 相互共享它们的低水印以构建向量时钟𝑉𝑤 = 𝑙1,𝑤,…,𝑙𝑚,𝑤,𝑤 ,其中𝑚 是斜杠执行器的数量。通过向量时钟,执行器观察了彼此在事件时间触发的进度和坐标窗口。当 Slash 执行器确定向量时钟中的时间戳条目大于待处理窗口的结束时间戳时,就会发生触发。 一致性。Slash使用基于epoch的一致性协议[14,22]和无冲突复制数据类型(CRDTs)[54]确保计算一致性。虽然我们将在第7.2.2节讨论我们的一致性协议,但我们将在下面描述crdt相关的方面。 状态后端将窗口的部分状态表示为 CRDT。因此,Slash 中的窗口桶(或窗口切片)需要表示为 CRDT。CRDT 能够在保证一致结果的同时合并部分状态。用于非整体窗口计算的 CRDT,例如聚合,依赖于聚合的交换性。用于整体窗口计算的CRDT,如连接,依赖于连接半格和增量更新[64]。例如,基于总和的窗口的 CRDT 存储每个并行求和的部分和。合并后,CRDT 将最终结果计算为所有部分值的总和。 5.2 有状态操作符Slash 提供了两个常见的有状态运算符:基于散列的聚合和基于散列的事件时间窗口的连接。Slash假设窗口技术依赖于窗口桶[38]或一般切片[59],并进行了以下修改。 加窗。Slash 作为由窗口桶(或切片)分配器和窗口触发器组成的运算符管道的一部分执行加窗运算符。窗口分配器确定记录所属的桶(或切片),并相应地对其进行更新。在 Slash 中,窗口分配器不假设预先划分的数据,而是将状态一致性转移到状态后端。窗口触发根据事件时间输出窗口内容。在 Slash 中,窗口触发器需要一个向量时钟来评估触发条件并依靠状态后端来提供一致的状态。 加窗聚合。Slash 提供基于哈希的聚合,遵循后期合并方法 [ 70]。每个 Slash 执行器线程急切地计算自己的本地状态,即每个 flight 窗口的部分基于哈希的聚合。在 Slash 中,我们使用 RM 加速和基于分布式 CRDT 的聚合来缩放后期合并。 窗口连接。Slash 提供了基于哈希连接的窗口流连接。对于每个飞行中的窗口,Slash 急切地根据传入记录的关键和事件时间为两个流构建一个哈希表。当窗口终止时,Slash 探测哈希表以输出存储记录的每个键成对组合。Slash 确保状态一致性,因为底层分布式哈希表懒惰地连接具有相同键的所有部分值。
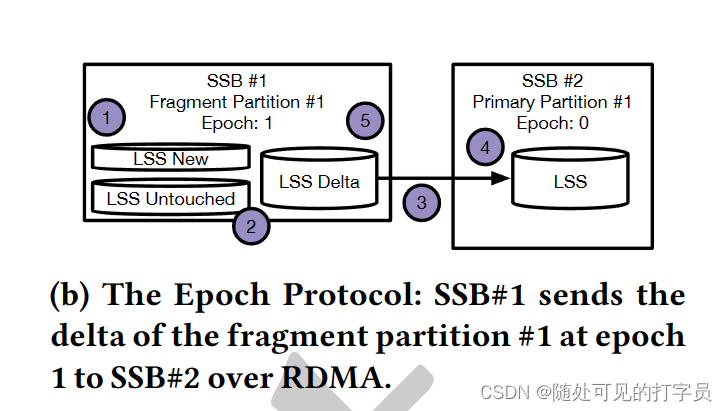
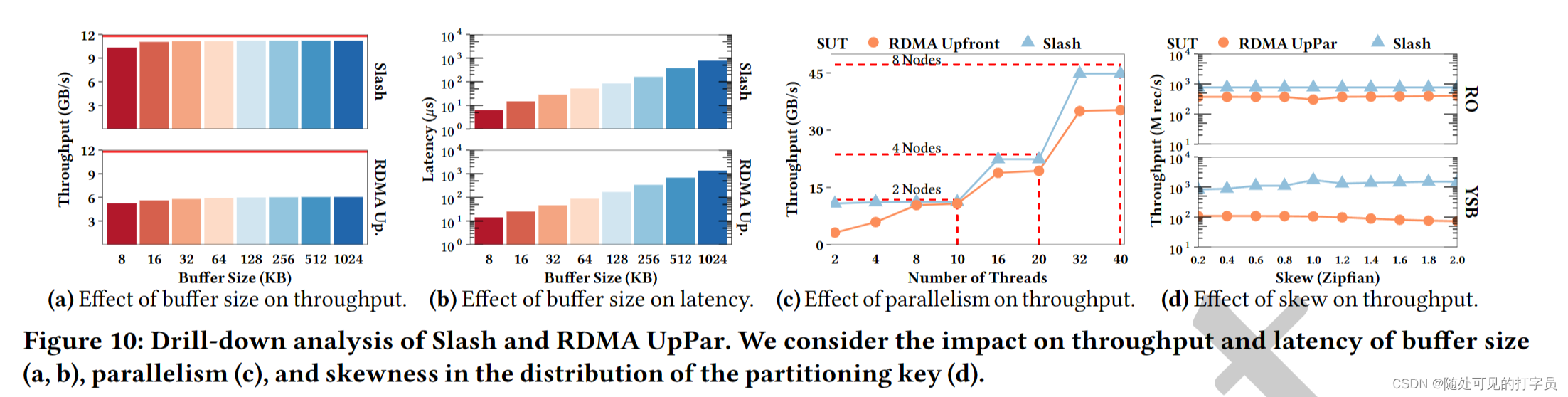
Slash 执行器使用跨多个节点的工作人员线程并行化运算符。对于每个物理运算符,Slash 将其 RDMA 通道分配给工作线程。每个线程轮询传入数据缓冲区的每个通道以处理。Slasash使用基于协程和基于推的处理模型的事件驱动调度器(图3)。协程是启用协作多任务的轻量级线程[46]。Slash 调度程序将计算协例程与 RDMA 协例程交错。RDMA 协程序执行与 RDMA 相关的任务,例如来自 RDMA 通道的轮询缓冲区。计算协程对轮询缓冲区执行基于推送的处理。在空 RDMA 信道的情况下,调度程序将相关的 RDMA 协例程链接并执行可用的现成计算任务。因此,空 RDMA 通道不会阻止挂起的计算协例程的执行。 我们选择联合程序,因为它们启用了与 10-20 ns 延迟 [31] 的上下文切换以及计算和 I/O 任务的交织 2)。当前 SPE 在专用线程 [10 , 23 , 56 , 72 ] 上执行与网络相关的操作。然而,在专用线程上执行 RST 操作需要与处理线程同步,这在常见的 x86 CPU 上浪费多达 400 个循环。Slash 调度程序通过执行计算任务来隐藏网络延迟,而 RST 包在飞行中。这可以对 RD 和计算操作进行细粒度控制,从而提高 CPU 效率。 总体而言,Slash 的处理模型受到 LightSaber [56] 和 Grizzly [23) 的启发,因为它依赖于基于任务的并行性和部分状态的后期合并。但是,它与它们的不同之处在于如下。首先,Slash 将上述系统的处理模型扩展到目标缩放执行。为此,它引入了通过 DMA 对部分结果及其惰性合并的渴望、分布式计算。其次,它使用联合程序扩展了基于任务的并行性,以将 RST 相关的操作与处理任务交织在一起。最后,它与执行策略无关,因为它支持基于编译和基于解释的策略。Slash 的工人线程有自己的共同程序队列来执行,而 LightSaber 和 Grizzly 在其工作人员线程中共享单个任务队列,并专注于基于编译的执行。 6 用于数据流的 RDMA在本节中,我们将介绍我们基于 RST 的传输协议,该协议使 Slash 能够以高吞吐量和低延迟流传输数据。我们概述了我们的协议(第 6.1 节),描述了它的阶段(第 6.2 节),并讨论了我们的 RD 通道的细节(第 6.3 节)。 6.1 RDMA 数据传输协议该协议通过 RST 通道确定生产者和消费者之间的记录交换。具体来说,它定义了对具有 RD 能力的循环队列的流水线访问,以保证记录的 FIFO 交付。我们的协议是消费者驱动的:消费者(基于其处理能力),要求生产者调整其发送率以避免压力。此外,我们的协议定义了一个连贯模型来访问队列:制片人不能覆盖消费者内存中的未读取缓冲区。为此,我们通过基于信用的流控制 (CFC) 335 ] 将/读取写入/从队列中。CFC 广泛用于 DMA 协议,以确保基于 RST 的数据结构的连贯性 [ 30 , 31]。在这项工作中,我们使用 CFC 来确保记录的 FIFO 交付并避免背压。 6.2 协议阶段该协议有两个阶段:设置阶段和传输阶段。设置阶段定义了 RST 通道的初始化,而传输阶段定义了在运行时对数据传输的处理。 设置阶段。该阶段包括 1) 在发送方和接收方初始化具有 RDMA 的内存的循环队列,以及 2) 设置两方之间可靠的 RDMA 连接。循环队列有 푡 个插槽,这是信用的初始数量。每个槽都是一个支持 RDMA 的固定大小的缓冲区,在这个阶段分配。푡 的值在整个查询执行过程中都是固定的,因为它的选择是硬件敏感的,并决定了流水线级别,这取决于 NIC 能力 [32]。 转移阶段。我们在图 4 中展示了转移阶段的步骤。在传输阶段,允许生产者:1从循环队列中获取下一个缓冲区并写入它,2 将缓冲区的写入请求发布到 DMA NIC,3 个从消费者那里扣除信用。相比之下,消费者被允许:1 个传入数据缓冲区的民意调查,2 标记缓冲区以处理,3 个将信用发送给生产者。 使用流水线,遵循我们的协议的生产者可以在必须等待信用[30]之前将其发送到 푡 缓冲区。特别是,写请求不会相互过度获取,并导致数据缓冲区在完成时在消费者上可读。为了保证生产者不会覆盖未读取的数据,消费者必须通知生产者关于其队列中的可写缓冲区。 属性。基于上述操作,我们的协议确保三个不变。首先,制片人在写请求后逐一减少其学分数。其次,消费者在处理缓冲区后将信用转移到生产者。这给缓冲区是可写性的生产者。最后,没有信用的制片人无法从队列中选择缓冲区。因此,它不能推动进一步编写请求,并且必须等待接收者的新信用。总体而言,遵循该协议的制片人和消费者保证始终以 FIFO 顺序交换记录,以自调整数据速率。 6.3 RDMA 管道RDMA 通道由一个 QP、一个循环队列和一个信用计数器组成。RDMA 通道使用 RDMA 实现缓冲区的零拷贝传输和接收。该组件背后的基本选择是循环队列的平面内存布局和通过 RDMA WRITE 的基于推送的传输模型。选择会影响关于数据结构、RDMA 动词和消息布局的设计。 数据结构。循环队列由一个具有 c ×m 字节的 DMA 能力的内存区域组成,其中 c 作为信用的数量,m 作为单个缓冲区的大小(见图 5)。因此,缓冲区是连续存储的,这会导致平面内存布局。每个缓冲区都包含连续的有效载荷和元数据,例如投票的标志。由于三个原因,平面布局是有益的。首先,它避免了昂贵的指针追操作 [70]。其次,连续存储的有效载荷和元数据通过单个 RST 请求启用数据传输,而解耦数据区域和元数据将需要两个 RD 请求。最后,它允许缓存对齐和巨大页面分配,减少 CPU 缓存未命中和 NIC TTLB 漏掉 [32]。 RDMA 动词。出于以下原因,我们使用 RST WRITE 而不是 DMA READ 选择了基于推送的传输方法。首先,RM READ 涉及每条消息的往返,这导致更高的延迟和 CPU 利用率 [31]。相比之下,RST WRITE 需要每条消息进行一次旅行。其次,DMA WRITE 支持基于推送的传输:生产者写入消费者的内存,从而调查其本地内存。相比之下,DMA READ 允许基于拉的传输:消费者不断读取生产者的远程内存,直到请求的数据可用。因此,基于 DMA 拉的模型会导致额外的网络流量,因为投票发生在 RD 上。总体而言,我们基于推送的方法每条消息只需要一个网络访问,并有效地民意调查本地内存。 消息布局。Slash 通过 RDMA WRITE 将缓冲区传输为消息。这需要检测接收器处入站消息的机制。为此,我们将缓冲区划分为有效载荷的数据区域和元数据的脚步。我们使用 Footer 的最终字节进行轮询,与对头进行轮询相比有两个好处。脚架上的轮询保证了完整的数据传输,因为 RDMA WRITE 将缓冲区从较低的内存地址转移到更高的内存地址。报头上的轮询并不能保证缓冲区的完全接收,因为传输可能仍在进行中。当消费者检测到最终字节的变化时,可以安全地处理数据区域。 7 SLASH 状态后门Slash State Backend (SSB) 是用于内存运算符状态的并发键值存储。它提供状态管理技术来构建使用 RST 在多个节点之间共享的全局运算符状态。在本节中,我们将描述我们的 RD 加速状态管理方法(第 7.1 节)和我们的 SSB 的组成部分(第 7.2 节)。 7.1 RDMA 加速状态管理在本节中,我们将描述我们使用 RDMA 加速向外 SPE 状态管理的方法。我们的状态管理利用 RDMA 使 SPE 的节点能够以高带宽和低延迟一致地读取和写入彼此的状态。为此,我们首先对状态管理组件(第 7.1.1 节)提出要求,然后讨论 SSB 的设计(第 7.1.2 节)。 7.1.1 要求状态管理定义了操作员如何访问和修改状态。我们的目标是通过 DMA 加速状态访问,并使运行运算符同时修改共享状态。因此,我们分析了对工作负载和 RST 语义的要求。 工作负载。SPE的状态后端有三个严格的设计要求[13]。首先,状态后端必须支持更新密集型工作负载,其中有状态操作符在记录的基础上同时执行状态点更新。点更新由readmodify-write (RMW)操作组成,该操作根据前一个值和记录内容更改键值对。其次,状态后端必须能够对其内容进行有效的扫描,例如及时触发和后处理窗口。最后,它必须允许任意状态大小,这可能超过单节点内存边界。 RDMA 语义。状态后端必须有效地处理节点之间的并发更新。多个节点可以同时更新相同的键值对,因此状态后端必须确保一致的更新语义。这是一个双重挑战,因为它 1) 在节点之间需要一个一致性协议来实现一致性,2) 涉及从本地 CPU 和远程 RDMA NIC 中仔细设计内存访问模式,因为它们不连贯。 7.1.2 斜杠状态后端的设计基于上述要求,我们考虑以下设计选择来实现一致状态管理的 RDMA 加速。如第 5 节所述,Slash 不执行重新分区,而是为有状态运算符使用共享的可变状态。共享可变状态可以在相同的键值对上并发读取和写入。然而,这需要读者和作家之间的昂贵协调,正如我们下面所示的那样,我们避免我们的 SSB。 部分状态。SSB 为每个局部运行运算符维护一个部分状态(图 6)。操作员在本地急切更新部分状态,符合常见的放大原则 [ 23 , 56 , 70]。使用我们的方法,公共操作是部分状态的每次记录更新,它们都在运算符之间引发排队,并且存在斜敏感哈希分区 [70]。相比之下,传统 SPE 的常见操作是每个记录分区和共同分区状态的更新(图 7)。 连贯协议。SSB 延迟使用基于 epoch 的一致性协议在领导者和帮助执行者之间同步分区。一个 epoch 是两个同步点之间的时间跨度。在 epoch 结束时,分区的帮助节点将其内容发送到合并键值对的头节点。此外,这可以实现任意大小的状态,因为它分散在集群的聚合内存中,并且仅在一个 epoch 结束时进行具体化。 更新冲突。SSB 需要支持来自多个执行器的相同键值对的并发更新。为此,Slash依赖于CRDT来合并冲突的键值对,如第5.2节所述。总的来说,我们的SSB实现了一个处理模型,省略了数据重新分区,并使常见的情况操作快速。Slasash 的常见情况操作是部分状态的急切计算,而当前的 SPE 在更新状态之前划分记录。 7.2 斜线状态后端组件SSB是Slash的状态存储层,它提供分布式哈希表来一致地管理操作符状态。在下文中,我们描述了我们 SSB 背后的技术:我们的分布式哈希表(第 7.2.1 节)和基于时期的一致性协议(第 7.2.2 节)。 7.2.1 分布式哈希表SSB 使用基于单独链接和日志结构的分布式哈希表。哈希表由每个分区的键值对的散列索引和日志结构存储 (LSS) [37, 49, 50] 组成。在下文中,我们首先提供我们整体设计背后的基本原理,然后描述 LSS。我们在图 8a 中展示了分布式哈希表的整体架构。 理性的。键值对的更新需要在哈希索引中找到该对在 LSS 之一中的位置。与开放寻址等技术相比,将索引与存储解耦有两个优点 [52]。首先,它为指向多个 LSS 1 的每个分区启用一个索引。其次,log-structure 会导致更新的时间局部性,即经常访问的键值对在 log 的同一部分。这使得快速检测 LSS 中的更改成为可能,以便帮助者可以使用 RST 将它们发送给领导者,而无需涉及指针追。因此,帮助者只向领导者移动最后一个修改对以避免冗余网络传输。相比之下,开放寻址诱导出一个分散的内存布局,需要完全扫描来检测更新。最后,我们不假设哈希索引的特定设计。相反,我们在本文的其余部分使用了 FASTER [13] 的哈希索引。 日志结构的存储。我们的 LSS 是一个具有 RD 能力的循环缓冲区,用于存储密集的键值对。我们部分遵循 FASTER [13] 的设计,并考虑其内存不足功能。但是,我们跳过磁盘溢出,因为它超出了我们的范围并扩展了其设计,以便在分布式环境中实现 DMA 加速。LSS 充当混合日志,可以在键值对 2 上进行并发附加和就地更新操作。我们将 FASTER 的设计扩展如下。首先,我们重新考虑其对分布式执行的设计,并介绍领导者和辅助节点。辅助节点使用专用 RD 通道将增量转换为块中的领导者执行器。Slash 将增量变化的接收和合并与查询处理交织在一起。其次,由于关键分布的频率变化,我们自适应地调整循环缓冲区的大小会随着时间的推移而变化。因此,我们的状态后端适应工作负载大小的变化。总体而言,我们的状态后端允许通过基于 epoch 的一致性协议 3 进行增量状态同步。
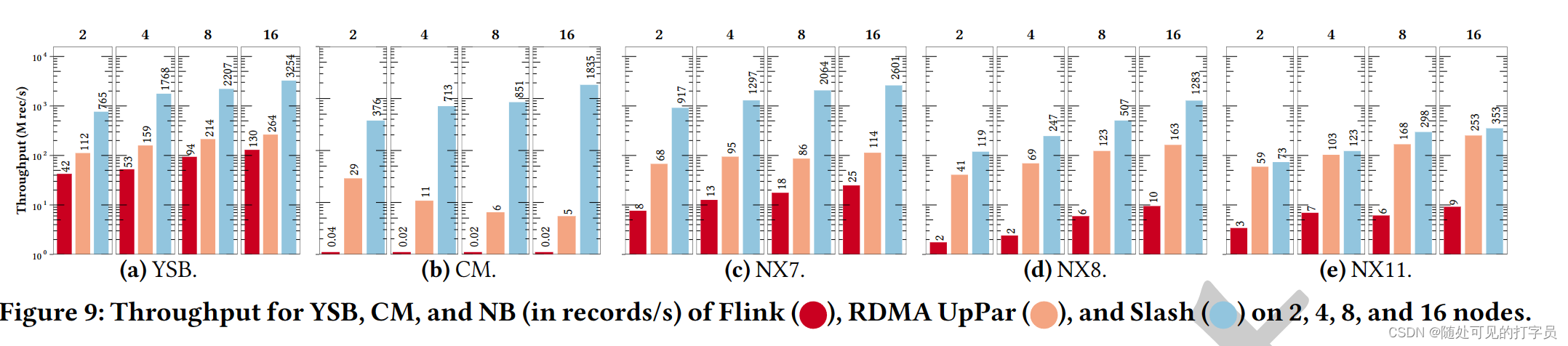
根据时期将无限流分割成有限的记录块。一般来说,基于 epoch 的并发系统可以安全地执行全局操作。许多系统依赖于基于 epoch 的同步来实现不同的目标,例如检查点 [10, 13]。在 Slasash 中,我们扩展了 epoch 的概念,将分布式共享分区懒惰(存储在辅助节点上)合并到它们各自的主要分区中。SSB 遵循基于 epoch 的一致性协议,该协议使节点能够同步状态并确保一致性。下面,我们将介绍设置和同步阶段以及协议的属性。 设置阶段。考虑一个夹斜杠执行器和管主分区的Slash部署,其中푡是节点数。每个分区都有一个 epoch 计数器来版本其内容。在设置阶段,每个leader执行器连接到所有可能的执行器。总体而言,Slash 在此过程中为状态同步创建了 푡2 RDMA 通道。请注意,我们的用于状态传输的 RDMA 通道使用 LSS 内存而不是专用的循环队列来避免数据副本。Slash 假设 epoch 持续时间与窗口大小无关。然而,Slash 实例表示窗口触发时 epoch 的提前终止。 同步阶段。我们假设每个有状态运算符接收记录以及通知系统范围事件的标记,例如标点符号。这是几个 SPE 中使用的通用技术,使运算符执行操作,例如触发器窗口或采取状态快照 [10]。在 Slash 中,同步令牌到运算符的出现使帮助者执行以下步骤,如图 8b 所示。 为每个共享分区调整 epoch 计数器。确定循环缓冲区的一部分,其中包含每个修改分区的 LSS 中最新变化。在传输之前,将更改标记为仅读取以防止 DMA 读取和 CPU 写入之间的不一致。通过 DMA 通道传输循环缓冲区的变化。增量合并本地 LSS 中的传输内容。转移后,使传输部分存储的内容无效,以便它可以进行进一步的 RMW 操作。属性。根据上述步骤,领导者执行者会延迟收到他们管理的状态更新。我们使用状态更新启动向量时钟更新,以便领导者执行器可以观察助手的进步。只有当向量时钟保证没有记录的出现或带有小于 𝑡 的事件时间时间戳的状态更新时,领导者节点才能在时间戳 𝑡 处触发每个键窗口。请注意,本地 epoch 计数器会导致到达更新的顺序,以便状态更新不能跳过每个其他。此外,丢弃传输的内容是安全的,因为 RMW 操作从零值重新启动。 遵循该协议的 SSB 的分布式实例保证在每个 epoch 结束时收敛到一致状态。窗口运算符受益于这种方法,因为窗口的触发发生在 epoch 的末尾。结果,窗口状态在触发时变得一致,这确保了正确的结果。 8 评价在本节中,我们通过一组端到端的实验和微基准通过实验验证 Slash 的系统设计。首先,我们在第 2 节中描述了我们评估的设置。8.1。其次,我们在端到端查询上将 Slash 与 RST UpPar、LightSaber 和 Apache Flink 进行比较(参见第 8.2 节)。第三,我们对 Slash 和 RST UpPar 进行了深入分析,以了解我们的设计选择背后的含义(参见第 8.2 节)。最后,我们在第 8.4 节中总结了我们评估的关键发现。 8.1 实验设置在下文中,我们将介绍我们的硬件和软件配置(第 8.1.1 节)以及选定的工作负载(第 8.1.2 节)。 8.1.1 硬件和软件在我们的实验中,我们使用以下硬件和软件配置。 硬件配置。我们在内部 16 节点集群上运行实验。每个节点配备 10 核、2.4 Ghz Intel Xeon Gold 5115 CPU、96 GB 的主存和单端口 Mellanox Connect-X4 EDR 100Gb/s NIC。每个 NIC 都连接到 Mellanox 的 100 Gbits InfiniB 和 EDR 开关。每个节点运行Ubuntu Server 16.04。我们禁用超线程并将每个线程放入专用核心。除非另有说明,否则每个硬件组件都配置为工厂设置。 软件配置。在我们的评估中,我们使用Slash、RDMA UpPar、LightSaber[56]和Apache Flink 1.9[11]作为测试(SUTs)下的系统。我们选择 Apache Flink 作为基于托管运行时的生产就绪、向外扩展 SPE 的代表,而我们选择 LightSaber 作为放大 SPE 的代表。Flink 提供基于队列的分区来扩展查询处理。为了配置Flink,我们遵循其配置指南[6]。在每个节点上,我们分配一半的核心进行处理,另一半分配网络 I/O。我们将 50% 的 OS 内存保留到 Flink 中,并分配剩余的内存来存储我们通过主内存流的输入数据集。我们配置Flink在我们的RDMA集群上使用IPoIB。 我们使用 gcc 9.3 使用 O3 编译器优化和本地 CPU 支持构建 Slasash。我们配置 Slasash 以使用所有物理内核和 48 GB 的内存(使用 2MB 巨大的页面)进行 RDMA 相关操作。除非另有说明,否则我们使用我们在第 2 节中介绍的最佳配置参数运行 Slash。8.3 并将 SSB 的 epoch 配置为每 64 MB 的数据结束。我们遵循 LightSaber 和 Rama UpPar 的类似配置步骤。请注意,我们使用 Slash 的 RST 通道来实现 RST UpPar。 8.1.2 工作量为了通过实验验证我们的系统设计,我们选择了 Yahoo! Streaming Benchmark (YSB) [ 70 ]、NEXMark 基准套件 (NB) [61 ] 和集群监控基准 (CM) [63 ]。我们选择 YSB 和 NB,因为它们是代表现实世界场景的常用基准 [ 17 , 70]。我们选择 CM,因为它基于 Google 提供的公开可用的真实世界数据集。此外,我们为我们的练习分析引入了一个自开发的 Read-Only (RO) 基准。 YSB。YSB 评估窗口聚合算子的性能。记录很大 78 字节,存储了 8 字节的主要密钥和 8 字节的创建时间戳。YSB 由一个过滤器、投影和一个基于时间的每键窗口组成。在 YSB 规范之后,我们使用 10m 事件时间、兄弟计数窗口。 NB。NB 模拟了一个具有三个逻辑流的实时拍卖平台:拍卖流、双向流和卖家事件流。记录是 206 (eller)、269 (auction) 和 32 (bid) 字节。每条记录都存储了一个 8 字节的主键和一个 8 字节的创建时间戳。NB 包含带有无状态运算符和有状态运算符的查询。 我们使用查询 7 (NB7)、8 (NB8) 和 11 (NB11) 来涵盖广泛的场景。基于这些查询,我们定义了三个工作负载来评估我们的 SUT。NB7 包含一个窗口聚合,在双向流上窗口为 60s。我们选择 NB7,因为它具有较小的状态大小和 RMW 状态更新模式。NB8 由拍卖和卖家流的事件时间上的 12 小时冒泡窗口加入组成。我们选择 NB8,因为它达到了很大的状态大小,因为它的附加模式用于状态更新和大型元组大小。NB11 由会话窗口加入双向和卖家流的事件时间组成。我们选择 NB11 来评估小元组大小对连接实现的影响。我们在套件中省略了其他查询,因为它们是无状态的 (NB1-2) 或评估聚合和连接 (NBQ3-14),我们已经用选定的查询覆盖这些查询。 CM。CM基准测试在时间戳记录流上执行有状态聚合,该记录包含来自谷歌12.5Knodes集群的跟踪。每条记录都大 64 字节,存储 8 字节的主密钥和 8 字节的时间戳。有状态聚合是一个 2s 翻滚窗口,用于计算每个执行作业的平均 CPU 利用率。 RO。RO 基准是一个有状态的查询,用于计算流中项目的出现次数。我们实现了 RO 来研究 I/O 瓶颈,因为数据在整个系统中流动而没有任何昂贵的计算。每条记录都存储了一个 8 字节的主键和一个 8 字节的创建时间戳。有状态运算符维护每个键的出现次数。关键是从 100M 范围内范围内的均匀分布中得出的。 实验概述。我们将评估构建如下。首先,我们执行端到端查询来比较 Slash、RST UpPar、LightSaber 和 Flink(第 8.2 节)。为此,我们将输入数据大小设置为节点数,以执行弱缩放实验 [24]。其次,我们进行了一系列微实验,以详细推理 Slash 组件的性能行为(第 8.3 节)。具体来说,我们细分了 Slash 和 RST 的执行时间UpPar 执行微架构分析 [66 ] 以揭示 Slash 使用硬件资源的程度。最后,我们总结了我们评估的关键发现(第 8.4 节)。 8.2 端到端查询在本节中,我们关注 SUT 的端到端查询的执行。我们在 Sec. 2.2.1 中展示了我们的评估方法。之后,我们将端到端查询分为两个类。首先,我们使用窗口聚合评估查询:YSB 和 NB7(第 8.2.2 节)。其次,我们使用加窗连接评估查询:NB8 和 NB11(第 8.2.3 节)。对于每个类,我们提供实验的描述,分析其结果,并讨论关键的见解。最后,我们在第二节中进行。8.2.4 一个 COST(优于单个线程的配置)分析 [42 ],并将斜线与 LightSaber [56 ] 进行比较,这是一个针对单节点执行优化的 SPE。 8.2.1 方法在我们的端到端评估中,我们遵循早期研究[70]中提出的基准方法。我们预先生成数据集以从主内存中流数据,以省略记录创建和摄取开销。因此,输入速率的上限是主内存带宽。每次运行中,源运算符都会实时消耗数据,SUTs 过程。在执行过程中,我们测量查询处理吞吐量,我们将其定义为SUT每秒可以处理的记录数量。我们多次重复每个实验并计算平均测量值。通过我们的实验,我们评估了 SUT 在执行查询时的效率。 8.2.2 带窗口聚合的查询在本节中,我们专注于 SUT 的性能比较,同时使用 YSB、CM 和 NB7 执行窗口聚合。 工作负载。在 YSB 和 NB7 中,每个执行器线程处理 1 GB 输入数据的分区。在 CM 中,每个执行器线程处理提供的输入数据集的分区。每个 YSB 分区都包含从 10M 范围内均匀绘制的主要密钥的记录。每个NB7分区包含投标记录,主密钥按照帕累托分布生成,由于重击者而导致长尾。YSB、NB7 和 CM 的分区是非不相交的:同一个键可以在多个分区中出现多次。此外,我们扩展了执行器线程和节点的数量。我们配置每个SUT使用每个节点的10个线程,最多16个节点。但是,RDMA UpPar 和 Flink 需要在窗口运算符之前划分输入流。因此,他们使用一半的线程来执行过滤器和投影,另一半用于窗口运算符。相反,Slash 在所有线程上运行过滤器、投影和窗口。 结果。在所有 YSB、CM 和 NQB7 实验中,Slash 优于所有 SUT(图 9a、9b 和 9c)。与 RST UpPar 和 Flink 相比,它在 YSB 上实现了高达 12 倍和 25 倍的吞吐量。与 RST UpPar 和 Flink 相比,Slash 在 NQB7 上分别获得了高达 22x 和 104 倍的吞吐量。同样,在执行 CM 时,Slash 比 RST UpPar 和 Flink 实现了高达两个数量级的吞吐量。 讨论。总体而言,Slash 是唯一实现最多 20 亿条记录/秒和 YSB、CM 和 NB7 中几乎线性弱缩放的 SUT。在这个实验中,Slash 实现了几乎线性弱缩放,而其他 SUT 导致性能欠佳。这种卓越的性能在窗口聚合中的原因是两方面的。首先,如之前的研究[70]所示,基于队列的输入记录的分区在单节点设置中引入了一个重大瓶颈。这也适用于分布式情况,因为网络传输由软件队列介导。因此,无论网络硬件如何,使用基于队列的分区来向外扩展SUTs都会产生固有的瓶颈。其次,Slash 有效地计算局部部分状态,并使用节点之间的点对点 RDMA 传输一致地合并它们。相比之下,在处理分区键分布偏斜的工作负载时,Slash 不受性能回归的影响。总体而言,由于更好地利用底层硬件资源,Slash 获得了更高的吞吐量,正如我们在第 2 节中进一步解释的那样。8.3。 在本节中,我们关注我们的SUTs的性能,因为它们运行NB8-11的窗口连接。 工作负载。我们遵循 NB7 的相同设置,除了以下方面。每个执行器线程处理 1 GB 输入流的分区,其中拍卖和卖方之间的比率以及投标和卖方之间的比率为 4 到 1,根据基准。请注意,每个出价总是一个有效的卖方。 结果。在所有 NQB8 和 NB11 运行中,与其他 SUT 相比,Slash 实现了更高的吞吐量(图 9d 和 9e)。在 NQB8 中,它的吞吐量分别比 RDMA UpPar 和 Flink 高 8 倍和 128 倍。在 NQB11 中,它的吞吐量分别比 RDMA UpPar 和 Flink 高 1.7 倍和 40 倍。 在这组实验中,我们观察到三个方面。首先,Slash 在包含连接运算符的查询上实现了几乎线性弱缩放,类似于窗口聚合。其次,Apache Flink 和 Rama UpPar 在吞吐量方面表现出严重损失。最后,Slash 没有达到与聚合情况相同的性能提升,尽管它优于其他 SUT。 讨论。SUTs之间加窗连接的主要性能差异可以用以下特征来解释。首先,加窗连接算子比加窗聚合的内存更密集。基于散列的流连接运算符将每个记录附加到中间状态,包括尚未匹配连接伙伴的记录。因此,Slash 中的附加操作不会受益于 CPU 缓存,因为即使对于相同的键,两个连续追加之间没有关系。相比之下,基于 RMW 的聚合受益于 CPU 缓存,因为 RMW 操作会导致时间关系缓存访问。其次,RDMA UpPar 和 Flink 中的分区会导致性能回归,就像窗口聚合的情况一样。这在增加扇出时变得更加严重,即节点数量。在这种情况下,使用队列的SUTs与节点数量呈次线性缩放。相比之下,Slash 在向外扩展时没有表现出性能回归。 总之,基于哈希的流连接不会显示与窗口聚合相同的性能提升,因为连接受到计算资源的限制。我们计划在未来的工作中进一步研究基于 RD 的流连接加速。 8.2.4 COST 分析在本实验中,我们按照 McSherry 等人提出的 COST 指标,将 Slasash 的处理性能与放大 SPE 进行了比较。[42]。我们选择LightSaber作为最近提出的放大SPE,它不运行在托管运行时(如BriskStream[72])。我们选择 CM、NB7 和 YSB 作为两个 SUTs 支持的工作负载,因为 LightSaber 不支持连接。在图11中,我们展示了LightSaber (L)和Slash(在2、4、8和16个节点上)在所选工作负载上的吞吐量。 我们观察到,Slash 每次运行都优于 LightSaber,因为它在将节点数量加倍时提高了性能。此外,与 LightSaber 相比,Slash 在 YSB 和 CM 上实现了几乎线性的加速(使用 16 个节点的吞吐量增量高达 11.6 倍)和 NB7 上的次线性缩放(使用 16 个节点的吞吐量增量高达 4.4 倍)。与 RDMA UpPar 的增益相比,Slash 相对于 LightSaber 的改进较小,因为 LightSaber 的执行与数据重新分区无关。总体而言,该实验的关键见解是,只要工作负载 1) 在单个节点上可持续,LightSaber 提供了对依赖于数据重新分区的 SPE 的有效替代方案,2) 不需要 RDMA 摄取,3) 不涉及连接操作。对于要求很高的工作负载,Slash 提供了稳健的向外扩展性能,因为我们的评估显示。 8.3 万亿次性能在上一节中,我们分析了 Slash 和 Flink 在端到端查询上的性能结果。在本节中,我们揭示了 Slasash 在 RDMA UpPar 上的性能提高背后的原因。我们在本次评估中省略了Flink,因为它的分区方法存在运行时和IPoIB开销[70]。在下文中,我们首先描述我们在第8.2.1节中进行向下钻评估的方法。之后,我们在第8.3.2节中评估RDMA UpPar和Slash在我们的RDMA评估设置中的最大可实现吞吐量。在此设置中,我们考虑与应用程序相关的方面,例如并行性和数据偏度。在第8.3.3节中,我们分解两个SUT的执行时间,以识别消耗大部分执行时间的CPU组件。最后,在第8.4.3节中,我们使用硬件性能计数器分析了每个SUT在有状态工作负载上的资源利用率。 8.3.1 方法在我们的性能向下钻中,我们分析了 Slasash 和 RDMA UpPar 的工作负载相关和硬件相关方面。与工作负载相关的方面提供了瓶颈的高级识别,包括数据特性和应用程序设置。硬件相关方面由硬件性能组成我们使用的计数器进行微架构分析。这些指标使我们能够推导出阻碍 RDMA 链路执行和饱和点的 CPU 组件。在下文中,我们考虑 RO 和 YSB 基准,并为每一类实验提供采样指标的简要描述。 8.9.2 与工作负载相关的方面分析在本节中,我们将 RDMA UpPar 和 Slasash 的性能与基于 RDMA 的数据传输的重点进行比较。我们考虑主要是 I/O 边界的 RO 查询来评估对数据重新分区性能的影响。我们分析了应用程序相关旋钮的查询处理(例如并行性和缓冲区大小)以及数据特征(即偏度)期间对吞吐量和延迟的影响。 工作负载。我们在由单个 RDMA NIC 连接的两个服务器上设置两个 Slasash 实例,以衡量缓冲区大小对吞吐量和延迟的影响。第一个实例通过我们的 RDMA 通道将输入数据流为第二个实例的缓冲区。第二个实例轮询 RDMA 通道并根据基准应用有状态运算符逻辑。每个实例对执行器使用多达 10 个线程。第一个节点上的每个生产者线程通过 RDMA 将记录的缓冲区发送到 Slasash 中其他节点上的一个消费者线程。在 RDMA UpPar 中,每个生产者线程根据散列分区将记录的缓冲区发送给任何消费者。我们跳过单线程配置,因为它们可以防止分区,这需要至少两个消费者线程。为了衡量并行性对吞吐量的影响,我们使用了多达 8 个节点。 结果。在这个实验中,我们评估了应用程序相关方面对两个 SUT 的性能的影响。首先,我们展示了缓冲区大小对SUTs(图10a)和延迟吞吐量的影响(图10b)。其次,我们通过缩放线程和节点的数量来衡量并行性的影响(图 10c)。最后,我们分析了分区键整个倾斜分布的影响(图 10d)。为此,我们使用以下 Zipfian 分布生成分区键,使用 푡 = 0.2…2.0。在图 10a 和 10c 中,我们以红色标记最大可实现网络带宽(11.8 GB/s),我们使用 ib_write_bw 基准测试工具 [33] 进行测量。请注意,在接下来的实验中,我们配置我们的 RDMA 通道以使用 푤 = 8(信用)。其他配置,例如 푡 = 8 和 푡 = 16 将吞吐量降低了高达 3%,而 푡 = 64 导致性能回归高达 10%。 输出。我们观察到 Slash 在所有配置上都优于 RST UpPar,因为它使用两个线程最多利用了 95% 的可用网络带宽(11.2 GB/s 中的 11.8 GB/s)。Slash 使用两个线程和 32 KB 缓冲区大小几乎饱和了一个 RST NIC 的理论带宽限制。相比之下,RST UpPar 利用多达 50% 的可用网络带宽,即 5.9 GB/s。 延迟。对于低于 128 KB 的缓冲区大小,Slash 实现了低于 100 毫秒的延迟,而它使用 1 MB 缓冲区大小及以上实现了高达 1 毫秒的延迟。相比之下,每个缓冲区大小的 DMA UpPar 延迟比 Slash 高约 10%。 并行性。Slash 实现了查询处理的最高聚合吞吐量(图 10c)。Slash 使用两个线程在 RO 基准测试中实现了 11.2 GB/s。相比之下,RDMA UpPar 需要 10 个线程才能饱和高达 91% 的可用网络吞吐量。 数据偏度。在存在分区键偏斜分布的情况下,Slash 表现出稳健的性能。有趣的是,我们观察到,当数据流中的分区键高度倾斜时,Slash的吞吐量会增加。相比之下,RDMA UpPar 的吞吐量下降高达 68% (RO) 和 110% (YSB),而分布中的偏度增加。 讨论。总体而言,我们的实验显示了三个有趣的方面。首先,与 RST UpPar(即 2 对 10)相比,Slash 成为线程数量较少的网络边界。这带来了一个重要的好处:增加每个节点的线程数和 RST NIC 会导致更高的处理吞吐量。我们无法为 RST UpPar 得出相同的结论,因为它需要更多线程才能达到几乎完全的行率。因此,与 RST UpPar 相比,Slash 表现出更高的多线程效率。其次,缓冲区大小对于 RST 硬件的数据流处理也起着重要作用。它支持基于工作负载和服务约束的最高(或最低)吞吐量(或延迟)。特别是,两个 SUT 都实现了微秒延迟,这比在 Flink 上测量的延迟低一个数量级(图中未显示)。最后,在存在偏斜数据的情况下,Slash 提供了比 DMA UpPar 更稳健的性能。特别是,DMA UpPar 遭受性能回归,因为由于数据偏度引起的消费者的数据相关选择,哈希分区会导致负载不平衡。相比之下,无论偏度如何,Slash 在 RO 上实现了恒定吞吐量,因为 RM 通道的传输性能不依赖于数据。在执行有状态的查询时,例如 YSB,偏度会导致 Slash 的吞吐量更高,因为它减少了 SSB 需要在节点之间合并(通过 DMA 和 CRDT)的状态键值对的数量。 8.3.3 执行细分在上一节中,我们分析了与应用程序相关的旋钮对查询处理的吞吐量和延迟的影响。特别是,我们已经证明与 Slash 相比,RST UpPar 提供的效率较低。在本节中,我们执行执行细分以揭示 RST UpPar 与 Slash 相比次优性能背后的原因。为此,我们在 RO 基准上对 Slash 和 RST UpPar 进行了微架构分析。 指标。在深入研究我们的分析之前,我们简要描述了所考虑的指标。在高层次上,最近的 x86 个 CPU 由两个流水线组件组成:前端和一个后端。前端将指令解码为哎呀,每个循环最多提供四个哎呀,后端。后端通过分配执行单元并从内存中加载数据来处理乱序。完成哎呀,雏形被定义为退休 (R),构成了 CPU 执行的有用工作。前端停顿、后端停顿和分支错误预测是 CPU 效率低下的根源。前端停顿后,后端没有血脉络,因此,应用是前端绑定(FeB)。后端停止后,需要等待来自内存子系统的数据或执行单元。在前一种情况下,执行是内存绑定(MemB),而在后一种情况下,它是核心绑定(Coref)。最后,由于分支错误预测导致退休之前取消哎呀,糟糕的推测(BadS)。 工作量。我们使用我们在先前实验中得出的 SUT 的最佳配置执行 RO 基准,并将节点称为发送者和接收者。具体来说,我们选择 64 KB 作为缓冲区大小,并使用两个和十个线程重复测量值,因为它们会导致最高的吞吐量。 讨论。该实验揭示了 RDMA UpPar 的低效率来源,我们将其与 Slasash 进行比较。关键发现是 RDMA UpPar 由于应用程序逻辑更复杂,不能有效地使用 CPU 资源。这对执行有两个影响。首先,与 Slasash 相比,分区背后的复杂逻辑导致代码占用很大,因此退休人数众多。较大的代码占用会导致前端停顿减慢发送方,进而接收方需要花费更多的时间等待。此外,分区的实现需要分支,这导致分支错误预测的情况下前端停顿。 其次,DMA UpPar 的接收者需要根据扇出对多个 RD 通道(以及内存位置)进行民意调查,这主要执行核心绑定。核心绑定执行是由 RST 通道用于投票的暂停指令 [15] 引起的(参见第 6 节)。当 DMA 缓冲区没有完全从远程传输到本地内存时,就会出现这种情况。相比之下,Slash 表现出与 RST UpPar 不同的行为。它的发送者是核心绑定的,因为它们饱和网络,因此必须等待通过暂停指令进行数据传输 (15)]。它的接收者主要是内存绑定的,这是等待航班内数据在寄存器中进行具体化的结果。它的接收者也是核心绑定的,因为它们必须等待发件人。但是,这与 Rama UpPar 的执行不同。事实上,当网络饱和时,Slash 的发件人不能发送,而 Slash 的发件人由于停顿而无法发送。总之,上面的讨论表明 Slash 的主要瓶颈是网络,这与我们在第 3.3.2 节的发现一致。 8.3.4 状态执行的资源利用在下文中,我们进一步分析了 Slasash 和 RDMA UpPar 的 CPU 资源的使用,以了解我们的设计选择对有状态查询的影响。我们使用第8.3.3节中性能最好的配置对Slash上的YSB和RDMA UpPar的发送方和接收方进行微架构分析。我们收集与执行相关的硬件性能计数器来分析以下三个方面。 微架构分析。在图 13 中,我们考虑了 CPU 微架构的资源利用,并观察到 Slash 主要是内存绑定的,而 DMA UpPar 的发送者和接收者是核心绑定的。Rama UpPar 的发件人存在前端停顿,这与之前的发现 [70 ] 一致,而 Slash 最小存在分支错误预测。最后,我们注意到 Slash 花了大约 20% 的时间执行退休,而 DMA UpPar 的接收者 - 计算结果 - 花 10% 的时间退出指令。 上述观察背后的原因如下。在 RDMA UpPar 的发送者端,分区逻辑导致前端停顿。此外,对扇出 RDMA 缓冲区的数据依赖写入会导致后端停顿(内存绑定分数)。总共有大约 30% 的执行时间,这会减慢分区速度。RDMA UpPar 的接收器线程在多个绑定的 RDMA 通道上轮询,这些通道依赖于暂停指令,因此执行成为核心绑定并减慢接收器的速度。请注意,发送方将其速度调整为接收方的处理率,这导致等待使发送方核心绑定。相比之下,Slash 表现出比 RDMA UpPar 更有效的执行,因为它本质上将 RMW 执行到 SSB 的内存中区域。由于原子指令的延迟,例如 compare-and-swap,RMW 会导致主要的内存绑定执行。Slash 的基于 epoch 的状态同步导致流线型 RDMA 访问,对性能的影响可以忽略不计。 指令流分析。我们在选项卡中显示。1 与 RDMA UpPar 相比,Slash 需要更少的指令和最多 5 倍的循环来处理每个单独的记录。此外,Slash 每个周期执行接近一条指令 (IPC)。RDMA UpPar 在发送方和接收方分别需要高达 0.4 和 0.6 IPC。请注意,最佳执行每个周期退役 4 条指令 [67]。 这两个SUT之间的差异在于RDMA UpPar的更复杂的分区逻辑,这需要每条记录更多的指令。因此,RDMA UpPar 的限制因素变为分区,这会减慢接收器的速度。因此,消费者基本上等待入站数据进行处理,因此是核心绑定的。相比之下,Slash 在记录的基础上执行一个简单的处理逻辑,但依赖于状态同步的更复杂的逻辑。 数据局部性分析。我们在 Tab 最右边的部分观察到。1 Slash 的执行在每个缓存级别上导致每条记录大约 1.5 次未命中。相比之下,DMA UpPar 的生产者在每个缓存级别上显示大约 1.3 个未命中,而其接收者则受到 LLC 未命中的影响最小。此外,Slash 诱导聚合内存吞吐量为 70.2 GB/s,大约是两个节点的聚合内存带宽的 52%。相比之下,RST UpPar 的内存访问率为 4.1(发送者)和 4.2(接收者)GB/s。RM UpPar 的发件人漏报是由于 DMA 扇出缓冲区中的数据相关写入。由于依赖原子操作的 SSB 更新,Slash 受到缓存未命中的影响。分区吞吐量会导致 DMA UpPar 的内存访问率较低,而 Slash 主要内存绑定。 讨论。该实验阐明了在执行有状态计算时 Slash SUT 的不同性能。这是由于 Slash 的 SSB 与 RST UpPar 的数据分区方法的更有效的资源利用。总之,RST UpPar 通过划分吞吐量并最终通过网络带宽来限制,而 Slash 主要受到内存性能的限制。这验证了我们的处理模型,基于部分结果的渴望计算及其惰性合并是最先进的 SPE 的数据重新分区的替代策略。 8.4 总结总之,我们的实验结果验证了我们的设计选择。在此基础上,我们推导出以下系统构建器指南,他们寻求通过 RDMA 加速他们的流处理工作负载。 应用本地 RST 加速。原生 Rama 加速使系统设计与节点数成比例,并在常见的流工作负载上实现比基于分区的方法更高的吞吐量。特别是,我们的 Slash 原型在窗口聚合和连接上分别比最强的扩展基线高 25 倍和 8 倍。此外,斜线在窗口聚合方面优于称为 LightSaber 的最先进的缩放 SPE 因子 11.6。避免数据重新分区。数据重新分区会导致性能回归,因为它使 SPE 受到分区吞吐量的限制。为了了解这种性能回归,我们运行了 Slash 和 RST UpPar 的性能练习。我们表明,Slash 使用 RST 和最小 CPU 资源在 RO 基准上实现了完整的行率。相比之下,RST UpPar 需要更高程度达到高吞吐量的并行性,因为它主要是由于昂贵的数据重新分区而绑定CPU。此外,我们证明了 Slasash 不受数据分布偏斜的影响。使用惰性合并。我们表明,在我们的评估中,基于急切计算的部分结果的惰性合并的处理模型获得了最高的吞吐量。然而,懒惰合并需要节点之间仔细的同步,以避免开销和不一致。我们证明了我们的 SSB 实现了惰性合并,与偏斜无关,并且在查询处理上引入了最小开销,正如我们的微架构分析所表明的那样。 9 相关工作在下文中,我们将讨论 RDMA 应用于数据库系统以及我们的方法和现有 SPE 之间的差异。 数据库系统的 RDMA。数据库社区采用 RST 来加速 OLAP 和 OLTP 工作负载。我们确定了三个采用领域:分布式交易、批量分析查询处理和键值存储。分布式交易技术,例如快照隔离 [8],从 DMA 中获益,以大规模部署 [69]。将 RST 用于 OLTP 的系统是 Oracle RAC [1]、IBM 纯Scale[2]、NAMDDB [ 9、69 ] 和 FaRM [18、19]。OLAP 运算符,尤其是连接,受益于 DMA 来加速分区 [7, 9, 20 , 21, 57]。大数据框架通过 DMA [ 28, 41, 62] 加速批处理工作负载,而键值存储使用 DMA 来提高吞吐量并减少值访问的延迟 [20, 51]。 我们的工作与上述研究是正交的,因为流处理比传统的数据库系统或键值存储有不同的要求 [ 29 , 55]。SPE 需要对入站数据流进行快速、有状态的处理。他们的关键要求涉及状态管理组件,该组件必须支持快速、并发点更新和范围扫描,以便在窗口中分析状态。基于 RST 的键值存储(例如 FaRM)不适合存储状态,因为它针对具有点查找和更新的事务工作负载。因此,系统设计者需要设计算法和协议,以使用 RST 原生加速 SPE。通过斜线,我们填补了这一空白,因为我们提供了通过设计解决 RST 加速的 SPE 组件。 流处理引擎。我们区分两类 SPE。Scale-out SPE 专注于可扩展性,并依靠基于套接字的通信将查询执行分布在大量节点上 [11, 12, 47, 58 , 68]。最近的原型为 Apache Storm [73] 提供了轻量级的 RDMA 集成,因此等效于 RDMA UpPar。Scale-up SPE 针对单节点性能,而忽略了网络相关方面 [23,34, 56, 70, 2]。使用 Slasash,我们结合了两全其美。我们的目标是使用 RDMA 加速进行向外扩展流处理,同时考虑最近的 SPE 放大技术以实现最大性能和机架规模。为此,我们提出了一种从放大技术中获益的系统设计,例如省略分区、后期合并、共享可变状态和硬件意识执行。然而,我们重新思考了上述技术,以使用 RDMA 将它们应用于分布式状态计算,并在多个节点上扩展处理。在这项工作中,我们展示了如何使用 RDMA 改进后期合并的性能,并在节点之间启用一致的共享可变状态。总体而言,我们的方法比基于 RDMA 的数据获得了更高的性能与 LightSaber 等放大 SPE 相比,重新分区方法,例如 RDMA UpPar 和几乎线性弱缩放。 10 结论在本文中,我们提出了 Slasash,这是我们具有原生 RDMA 加速的新型 SPE,它为高速网络的新型 SPE 铺平了道路。Slasash 实现了基于对分布式、部分状态及其惰性合并的急切计算的处理模型,以一致的全局状态。为此,Slash 的系统设计由三个构建块组成,可以在完整的 RDMA 网络速度下实现有状态处理。我们已经针对 RDMA UpPar 验证了我们的原型,它使用基于 RDMA 的数据重新分区、启用 IPoIB 的 Apache Flink 和称为 LightSaber [56] 的放大 SPE。总体而言,我们已经证明我们的方法在比 Apache Flink(最多两个数量级)和 LightSaber(高达 11.6 倍)更高的通用流工作负载上实现了比 RDMA UpPar(高达 22 倍)更高的吞吐量。 |
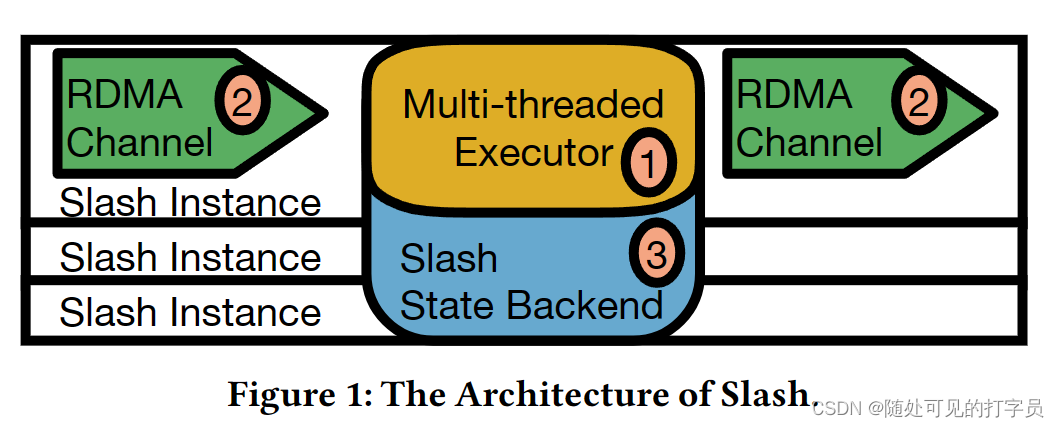
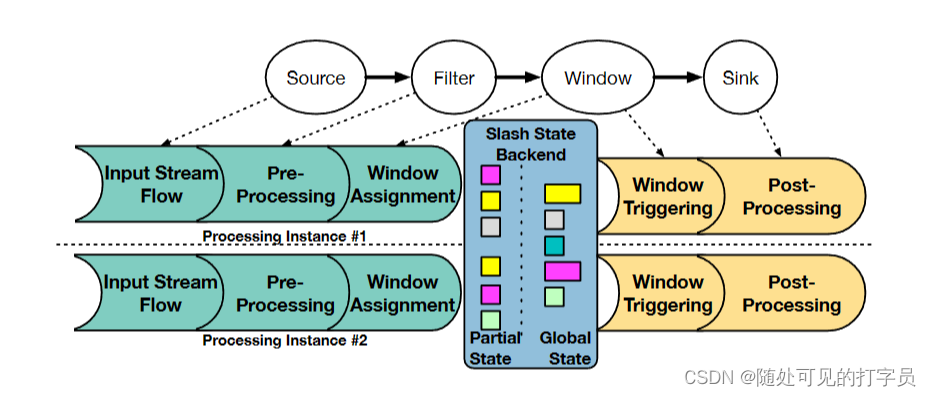
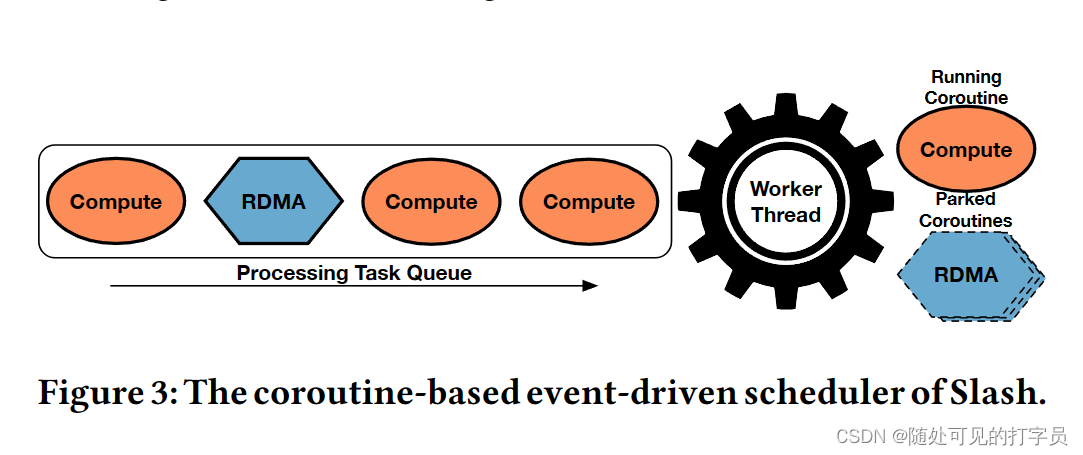 图 3:Slash 的基于协例程的事件驱动调度器。
图 3:Slash 的基于协例程的事件驱动调度器。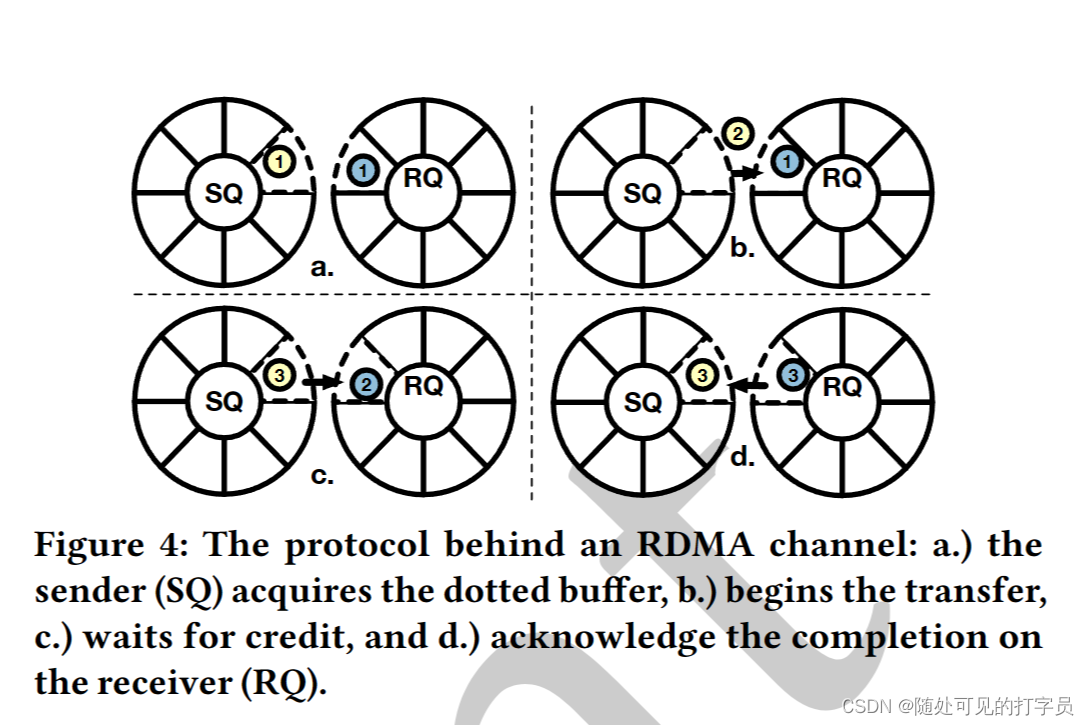 图 4:RD 通道背后的协议:a.)发件人 (SQ) 获取虚线缓冲区,b.)开始传输,c.)等待信用,d.)承认接收者 (RQ) 的完成。
图 4:RD 通道背后的协议:a.)发件人 (SQ) 获取虚线缓冲区,b.)开始传输,c.)等待信用,d.)承认接收者 (RQ) 的完成。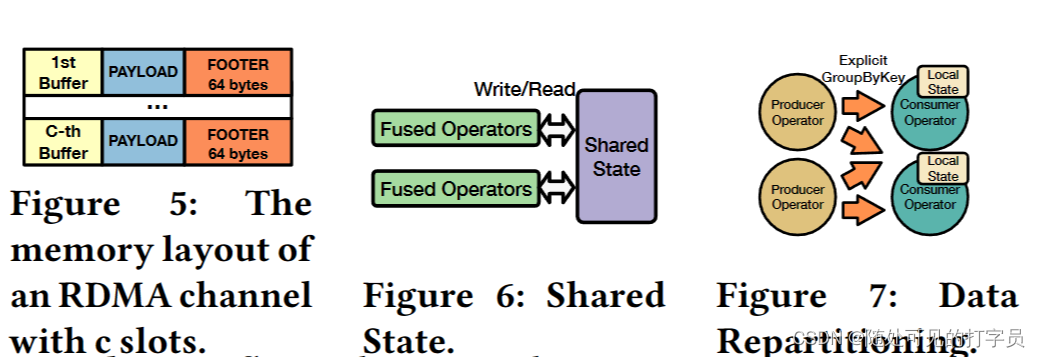 状态维护。SSB将键值空间划分为不相交的分区,并将每个分区分配给执行器。每个执行器都是一个分区的领导者,我们称之为主分区。Slash 不执行重新分区,因此每个执行器可能会维护属于另一个领导者分区的状态。因此,执行器存储每个远程主分区的片段,并成为它们各自的leader执行器的助手。对于每个分区,其领导者和助手根据以下一致性协议同步其内容。这导致键值对的空间放大与节点数量成正比。但是,值大小取决于窗口计算的语义。因此,非整体窗口会导致每个节点的聚合,而整体窗口会导致每个节点的值集不相交。
状态维护。SSB将键值空间划分为不相交的分区,并将每个分区分配给执行器。每个执行器都是一个分区的领导者,我们称之为主分区。Slash 不执行重新分区,因此每个执行器可能会维护属于另一个领导者分区的状态。因此,执行器存储每个远程主分区的片段,并成为它们各自的leader执行器的助手。对于每个分区,其领导者和助手根据以下一致性协议同步其内容。这导致键值对的空间放大与节点数量成正比。但是,值大小取决于窗口计算的语义。因此,非整体窗口会导致每个节点的聚合,而整体窗口会导致每个节点的值集不相交。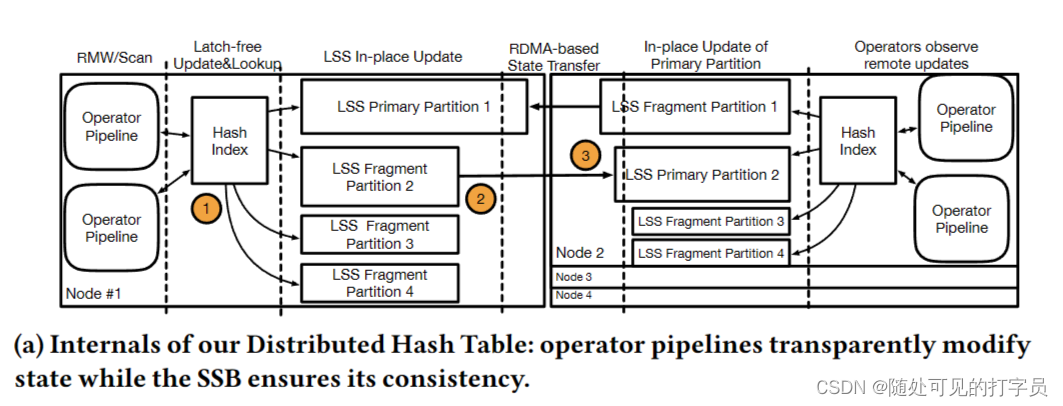
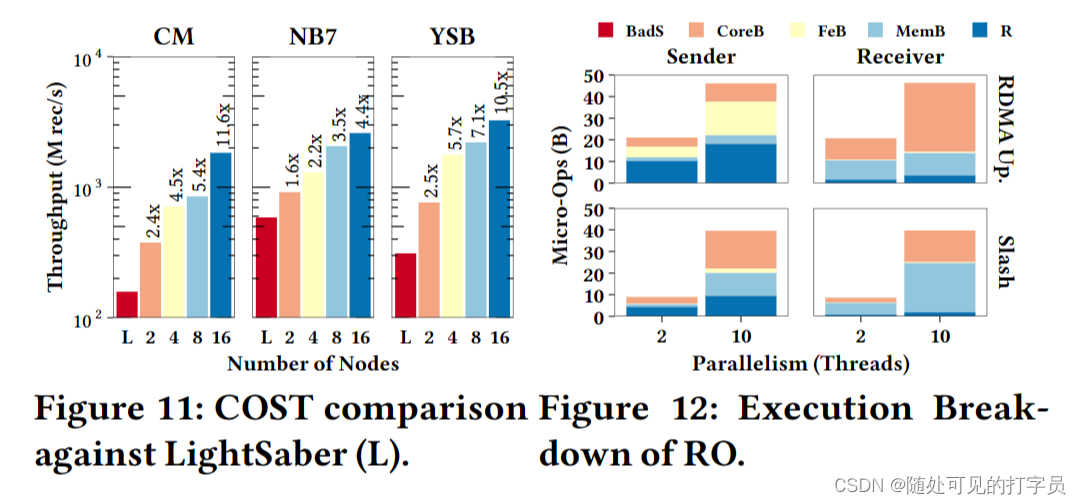 结果。在图 12 中,我们展示了 RO 基准测试的概要中的执行细分。我们注意到 RDMA UpPar 需要比 Slasash 执行 RO 基准测试的提升最多两倍。它的发送者产生的前端停顿比Slash的发送者多7倍。事实上,其具有两个和十个线程的发送者的执行是前端边界(总共 CPU 周期分别为 22 和 33%)。相比之下,Slash 表现出不同的行为,因为它的发送者本质上是核心绑定的,它的接收者是内存绑定的。
结果。在图 12 中,我们展示了 RO 基准测试的概要中的执行细分。我们注意到 RDMA UpPar 需要比 Slasash 执行 RO 基准测试的提升最多两倍。它的发送者产生的前端停顿比Slash的发送者多7倍。事实上,其具有两个和十个线程的发送者的执行是前端边界(总共 CPU 周期分别为 22 和 33%)。相比之下,Slash 表现出不同的行为,因为它的发送者本质上是核心绑定的,它的接收者是内存绑定的。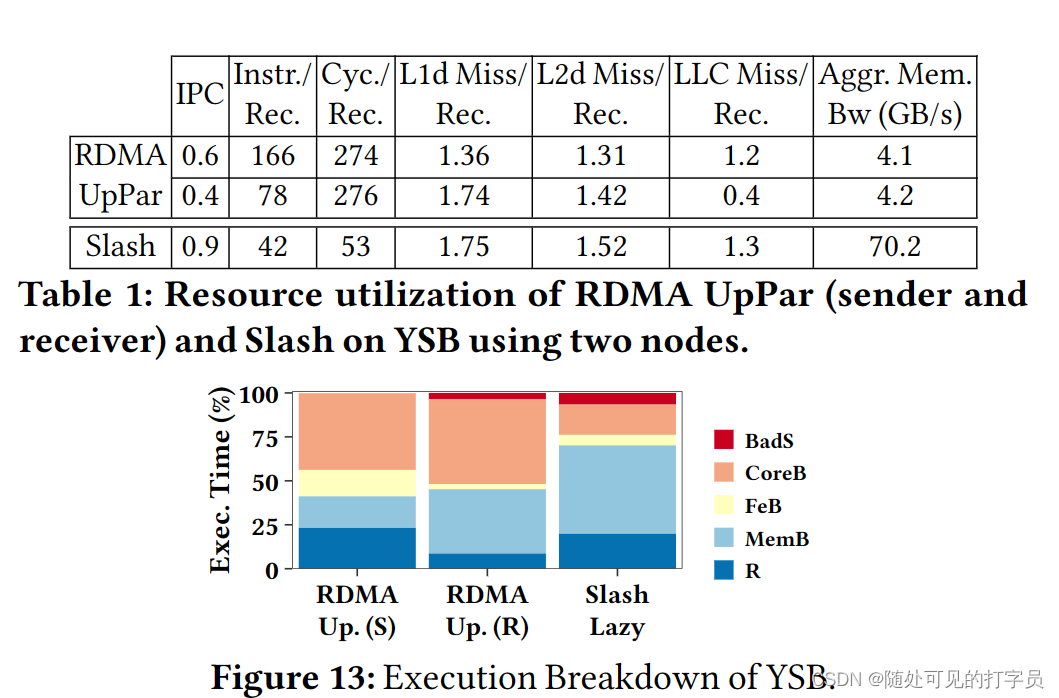 通过这种权衡,Slash 在通用代码路径上实现了快速执行,并在同步时引入了可忽略的开销。
通过这种权衡,Slash 在通用代码路径上实现了快速执行,并在同步时引入了可忽略的开销。【本文地址】