| 【开源项目】MaxKB+Ollama:构建私有化知识库问答系统 | 您所在的位置:网站首页 › 知识问答下载app › 【开源项目】MaxKB+Ollama:构建私有化知识库问答系统 |
【开源项目】MaxKB+Ollama:构建私有化知识库问答系统
|
点击上方“AI搞事情”关注我们 MaxKB:开源知识库问答系统
MaxKB 是一款基于 LLM 大语言模型的知识库问答系统。MaxKB = Max Knowledge Base,旨在成为企业的最强大脑。 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好; 无缝嵌入:支持零编码快速嵌入到第三方业务系统; 多模型支持:支持对接主流的大模型,包括 Ollama 本地私有大模型(如 Llama 2、Llama 3、qwen)、通义千问、OpenAI、Azure OpenAI、Kimi、智谱 AI、讯飞星火和百度千帆大模型等。 快速开始 方式一:docker部署 docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data --privileged=true 1panel/maxkb # 用户名: admin # 密码: MaxKB@123..从运行命令可以看到,服务依赖postgresql数据库,所以提前需要安装postgresql数据库。docker一键部署postgresql $ docker run -itd --name postgres -e POSTGRES_PASSWORD=连接PostgreSQL的密码 -e ALLOW_IP_RANGE=0.0.0.0/0 -p 5432:5432 -v /postgres/data:/var/lib/postgresql/data postgres:latest不然日志会报: waiting for postgres 127.0.0.1:5432 - no response最后,通过IP:8080端口就可以访问maxkb页面了 
接着,创建自己的应用了,不过依赖大模型,这里我们接入开源Ollama LLM模型 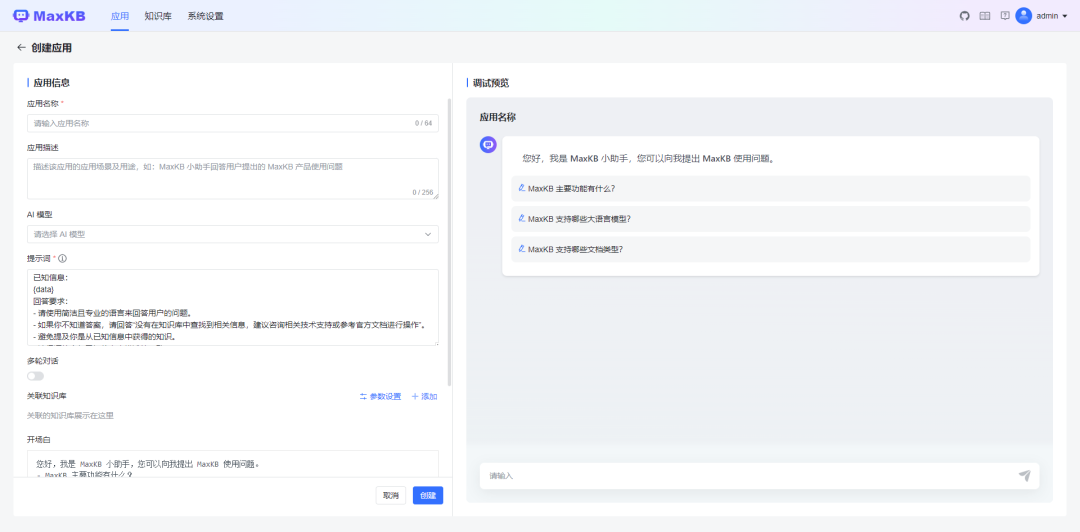 方式二:1Panel 应用商店
方式二:1Panel 应用商店
你也可以通过 1Panel 应用商店 快速部署 MaxKB + Ollama + Llama 2,30 分钟内即可上线基于本地大模型的知识库问答系统,并嵌入到第三方业务系统中。 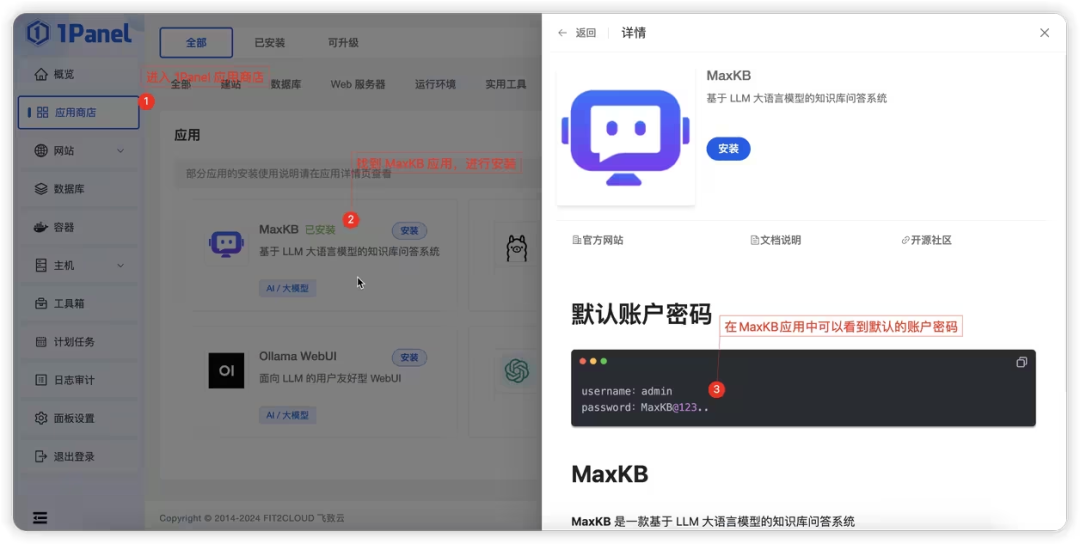 方式三:本地部署
方式三:本地部署
下载源码并运行python程序入口: git clone https://github.com/1Panel-dev/MaxKB.git cd MaxKB python main.py 在线体验你也可以在线体验:DataEase 小助手,它是基于 MaxKB 搭建的智能问答系统,已经嵌入到 DataEase 产品及在线文档中。 如你有更多问题,可以查看使用手册,或者通过论坛与我们交流。 使用手册 演示视频 论坛求助 技术交流群 UI 展示
前端:Vue.js 后端:Python / Django LangChain:LangChain 向量数据库:PostgreSQL / pgvector 大模型:Azure OpenAI、OpenAI、百度千帆大模型、Ollama、通义千问、Kimi、智谱 AI、讯飞星火 Star History Star History Chart
ollama:开源大语言模型服务工具
Star History Chart
ollama:开源大语言模型服务工具
 部署安装
docker安装
# 拉取镜像
docker pull ollama/ollama
# 运行镜像
docker run -it -v ollama:/root/.ollama -p 11434:11434 --privileged=true --name ollama ollama/ollama
部署安装
docker安装
# 拉取镜像
docker pull ollama/ollama
# 运行镜像
docker run -it -v ollama:/root/.ollama -p 11434:11434 --privileged=true --name ollama ollama/ollama
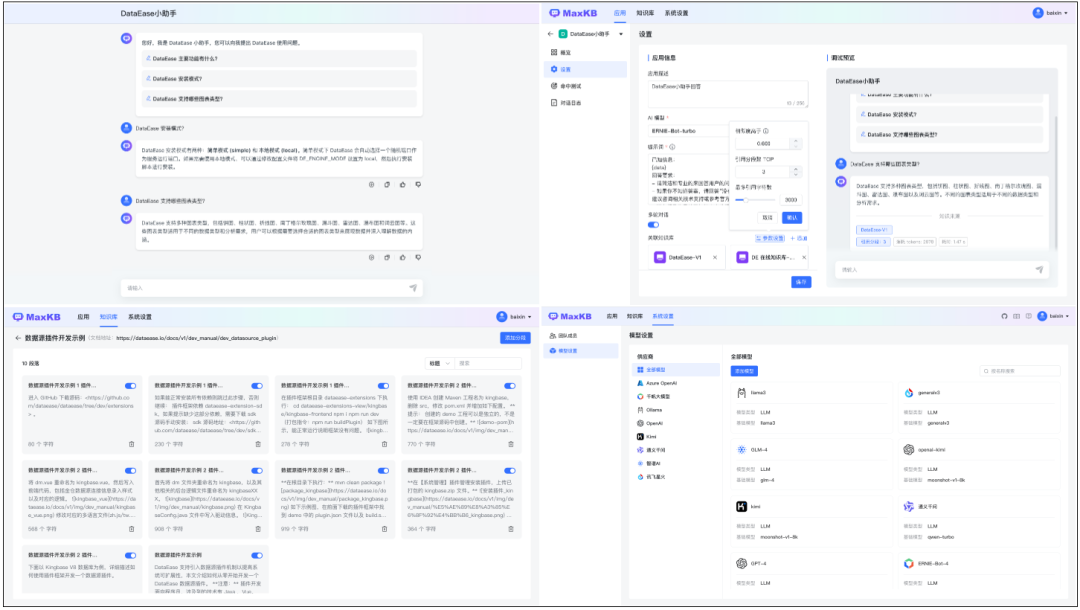
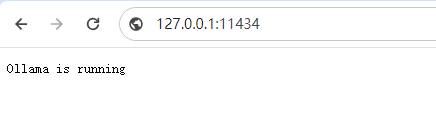
不加--privileged=true,报错: runtime/cgo: pthread_create failed: Operation not permitted访问测试,提示正在运行 进容器进行模型下载,不然后面添加模型会报NoneType docker exec -it ollama ollama run qwen MaxKB + Ollama智能问答系统 添加模型依次点击系统设置->模型设置->Ollama->添加模型 模型名称填写自定义的名称即可 模型类型选择 大语言模型 基础模型不能随意填写,只能使用ollma模型库中已有的模型,这里我们用的是qwen:1.8b API域名填写前面ollama起服务的机器ip和端口(11434) API Key随便填 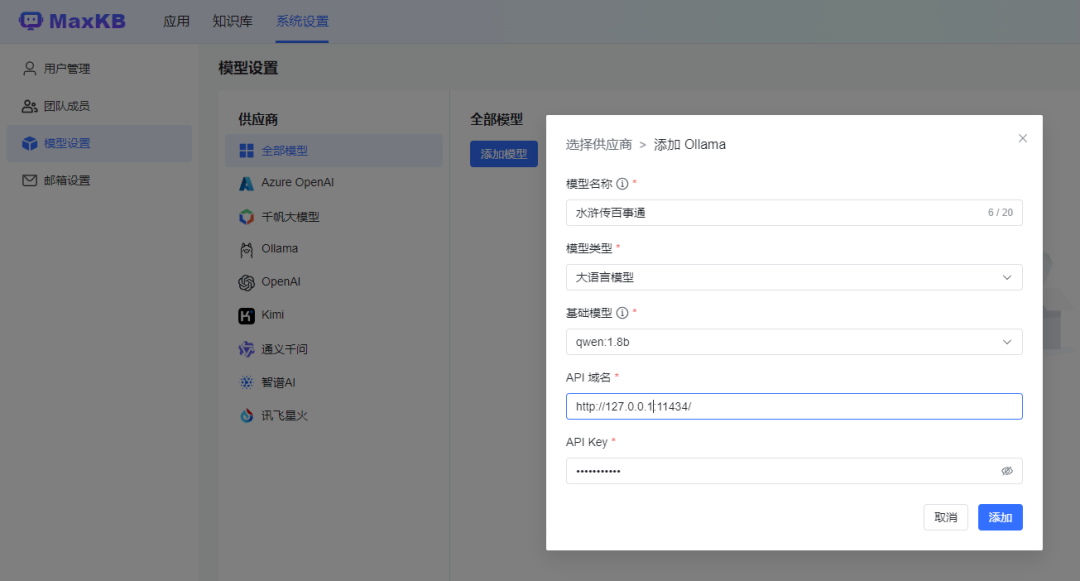
点击添加后开始下载模型, 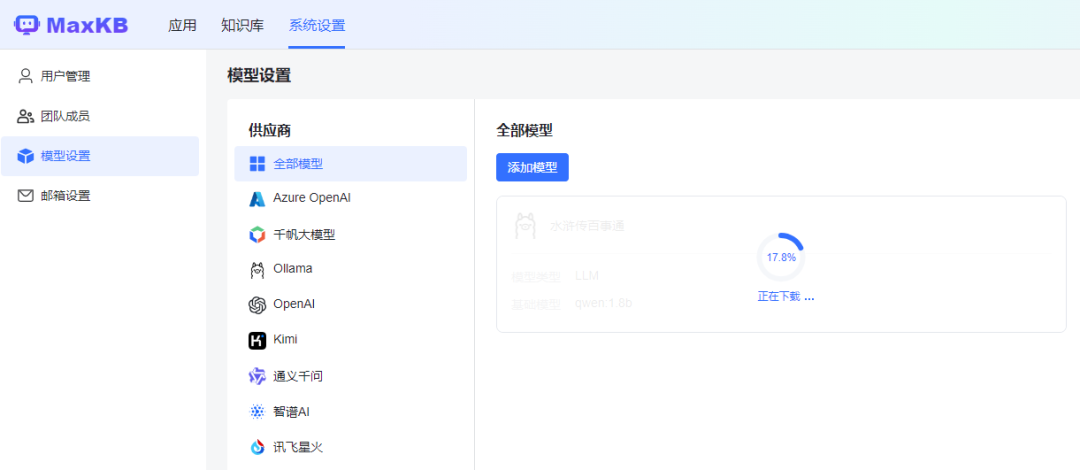 创建知识库
创建知识库
企业私有的专业知识库,包含各种类型的数据,是问答对话中回答用户问题的知识来源。 MaxKB 知识库分为:通用型知识库和Web 站点知识库两种类型。通用型知识库:对离线文档上传管理,支持的文档类型为 Markdown、TXT、PDF、DOCX 类型的文本数据。 Web 站点知识库:用于获取在线静态文本数据管理,输入 Web 根地址后自动同步根地址及子级地址的文本数据。 我们以水浒传来创建知识库,可以从网上下载点击【知识库】菜单,进入知识库列表页面,该页面支持知识库创建、编辑、同步、删除、查询等功能。 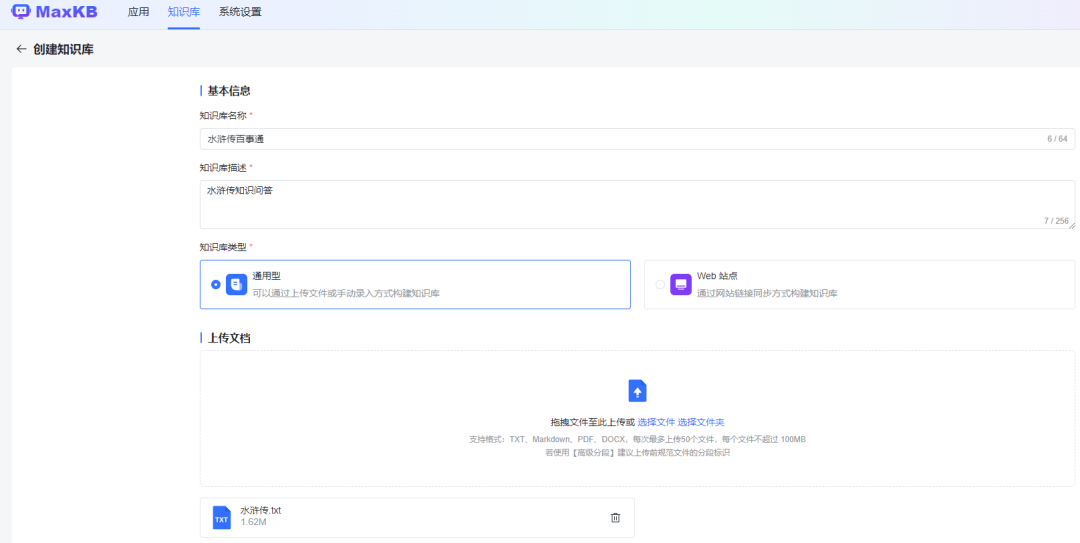
创建并导入,由于文档本身通过换行符进行了分段,我们通过高级分段,并选择分段标识为回车,然后点击生成预览,可以简单预览下分段的效果: 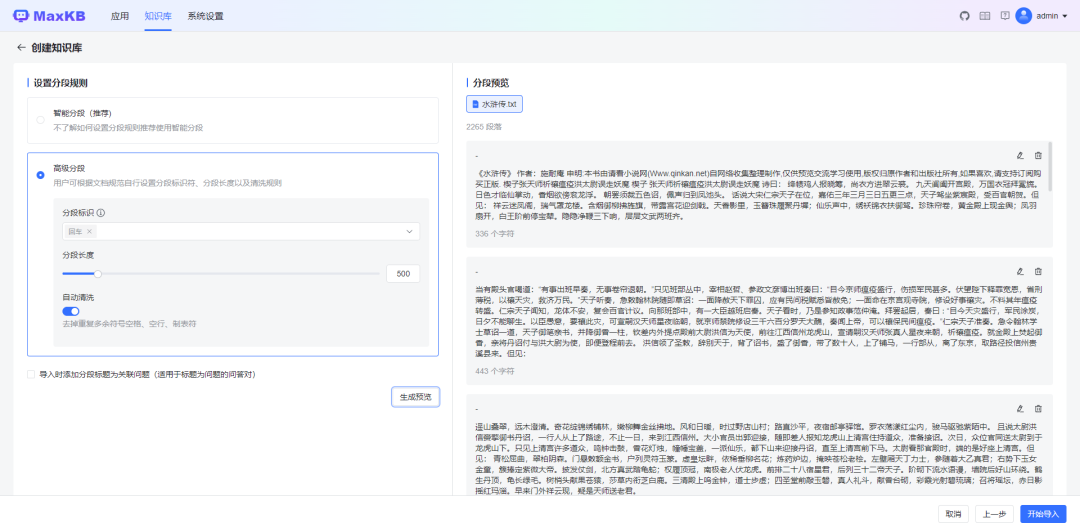
开始导入,显示 知识库创建成功,但是文档还在持续导入中... 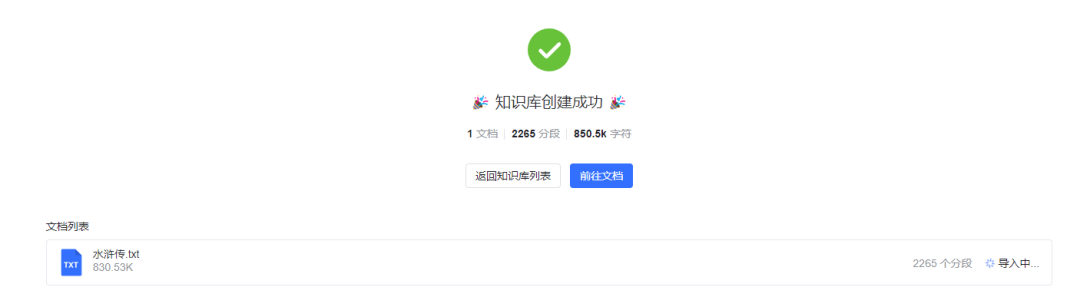
从日志看,这里主要是将文档进行向量化,一般也需要比较长的时间。 2024-05-13 17:26:32 [listener_manage INFO] 开始--->向量化数据集:e22b6526-110a-11ef-9017-0242ac110011 2024-05-13 17:26:32 [basehttp INFO] "POST /api/dataset HTTP/1.1" 200 714 2024-05-13 17:26:32 [listener_manage INFO] 数据集文档:['水浒传.txt'] 2024-05-13 17:26:32 [listener_manage INFO] 结束--->向量化数据集:e22b6526-110a-11ef-9017-0242ac110011 2024-05-13 17:26:32 [listener_manage INFO] 开始--->向量化文档:e22bc2e6-110a-11ef-9017-0242ac110011 2024-05-13 17:29:37.318 CST [66] LOG: checkpoint starting: time 2024-05-13 17:31:52.298 CST [66] LOG: checkpoint complete: wrote 1329 buffers (8.1%); 0 WAL file(s) added, 0 removed, 0 recycled; write=134.975 s, sync=0.004 s, total=134.980 s; sync files=40, longest=0.001 s, average=0.001 s; distance=9868 kB, estimate=9868 kB 2024-05-13 17:32:21 [listener_manage INFO] 结束--->向量化文档:e22bc2e6-110a-11ef-9017-0242ac110011 2024-05-13 17:34:37.377 CST [66] LOG: checkpoint starting: time 创建应用基于前面两步创建的AI模型和关联知识库创建AI应用,点击应用->创建应用,填入应用名称和应用描述,修改开场白。 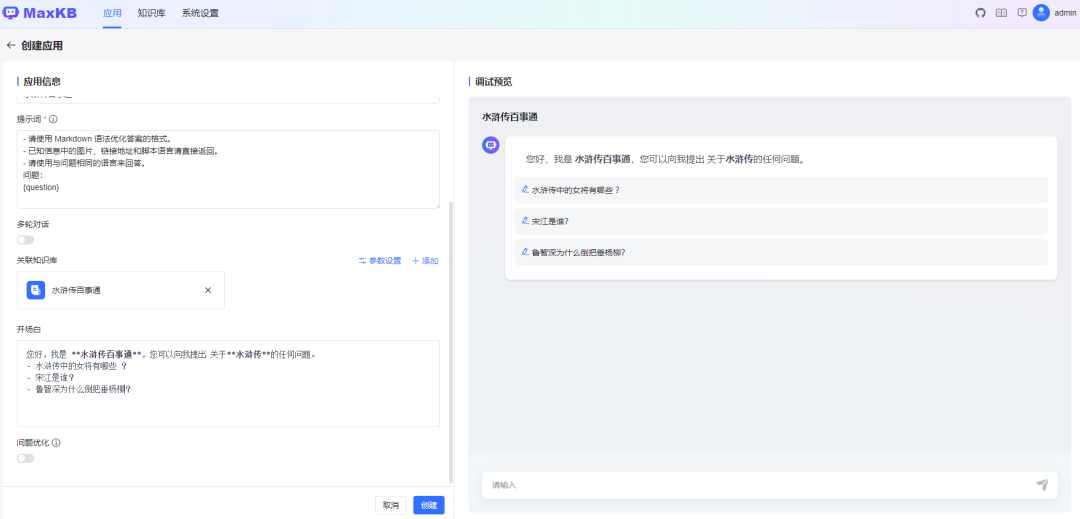
点击创建,智能问答机器人便创建成功了,右侧调试预览页面可以体验我们创建的问答机器人,不过这答案着实让人有点想哭/(ㄒoㄒ)/~~,我们可以使用更大的模型或者优化提示词,优化回答效果。 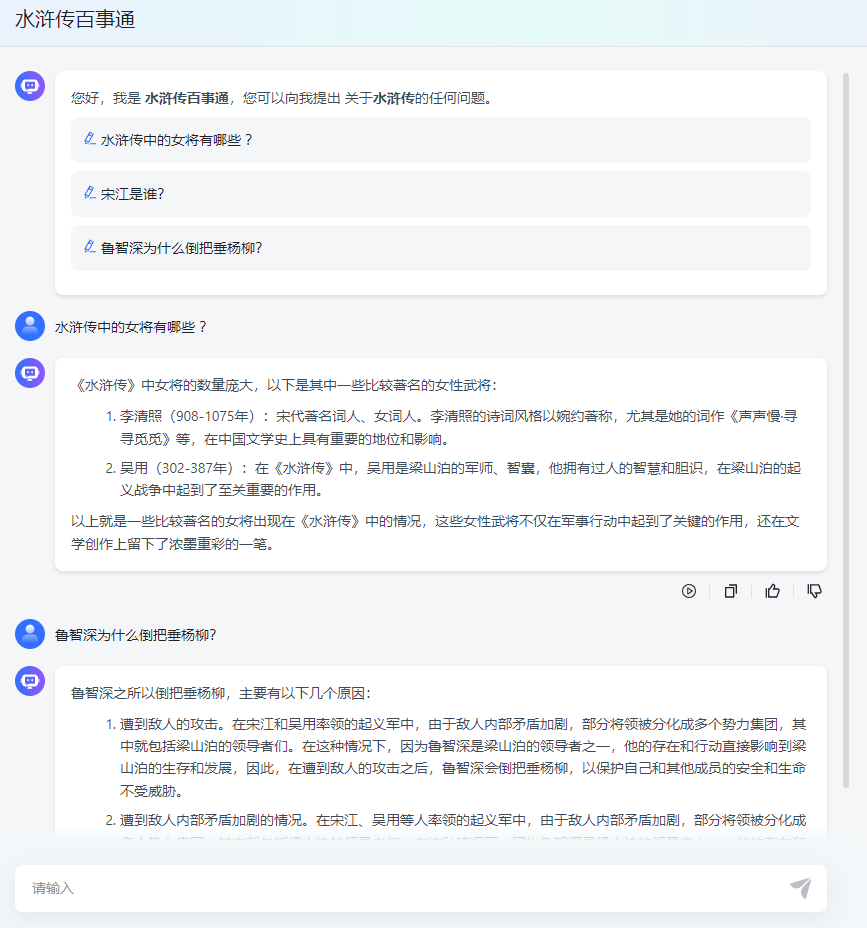
同时,由于服务器没有GPU,回答相对比较耗时。若有GPU的话,部署加上ollma服务时,加上--gpus all docker run -it -v ollama:/root/.ollama -p 11434:11434 --privileged=true --name ollama --gpus all ollama/ollama 参考:MaxKB: https://github.com/1Panel-dev/MaxKB 操作教程丨MaxKB+Ollama:快速构建基于大语言模型的本地知识库问答系统https://www.bilibili.com/read/cv33865421/ 使用手册: https://github.com/1Panel-dev/MaxKB/wiki/1-%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2 演示视频: https://www.bilibili.com/video/BV1BE421M7YM/ 论坛求助: https://bbs.fit2cloud.com/c/mk/11 Ollama: https://github.com/ollama/ollama ollama模型库:https://ollama.com/library Llama3 中文版整合MaxKB打造私有化知识库问答系统 https://www.bilibili.com/read/cv34130344/ 基于Ollama+MaxKB快速搭建企业级RAG系统 https://zhuanlan.zhihu.com/p/694850029
长按二维码关注我们 有趣的灵魂在等你
|






【本文地址】