| 知网根据作者及单位检索文献汇总到Excel(2021.6.9) | 您所在的位置:网站首页 › 知网怎么看摘要内容 › 知网根据作者及单位检索文献汇总到Excel(2021.6.9) |
知网根据作者及单位检索文献汇总到Excel(2021.6.9)
|
依据作者及单位在知网检索文献汇总至Excel 实践(2021.6.9)
1、知网依据作者及单位检索文献1.1 检索实例(29条结果)1.1.1 20个页面每页显示20条检索结果1.1.2 1个页面每页显示50条结果
2、将检索文献结果汇总至Excel2.1 纯手工复制粘贴(针对检索结果少且页数不多 较为可行)2.2 Python解析检索结果所在的HTML页面(操作性强)2.2.1 获取1个页面对应的HTML页面代码2.2.2 HTML页面代码格式化2.2.3 Python解析各个格式化后的HTML页面获取检索结果
1、知网依据作者及单位检索文献
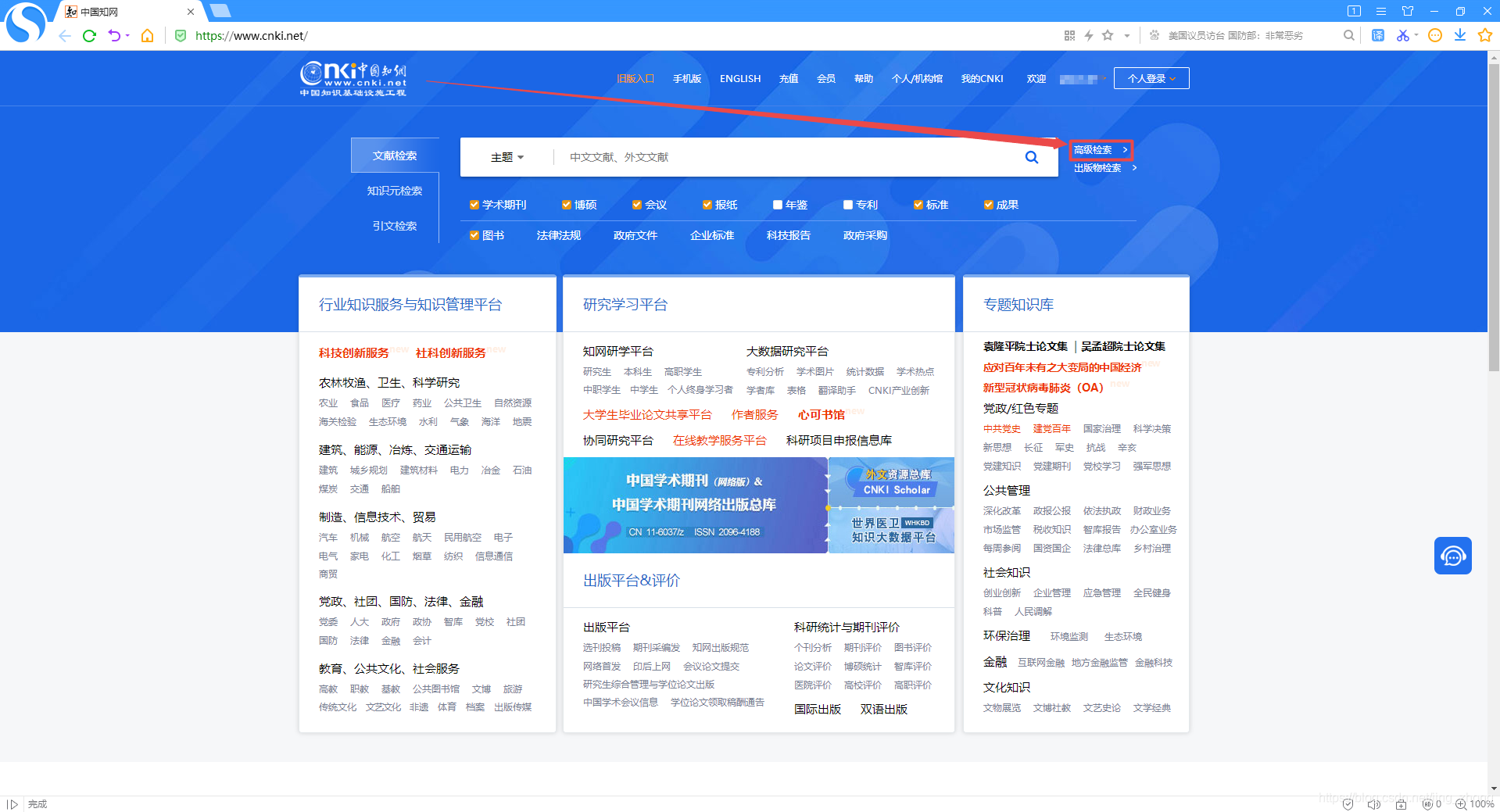
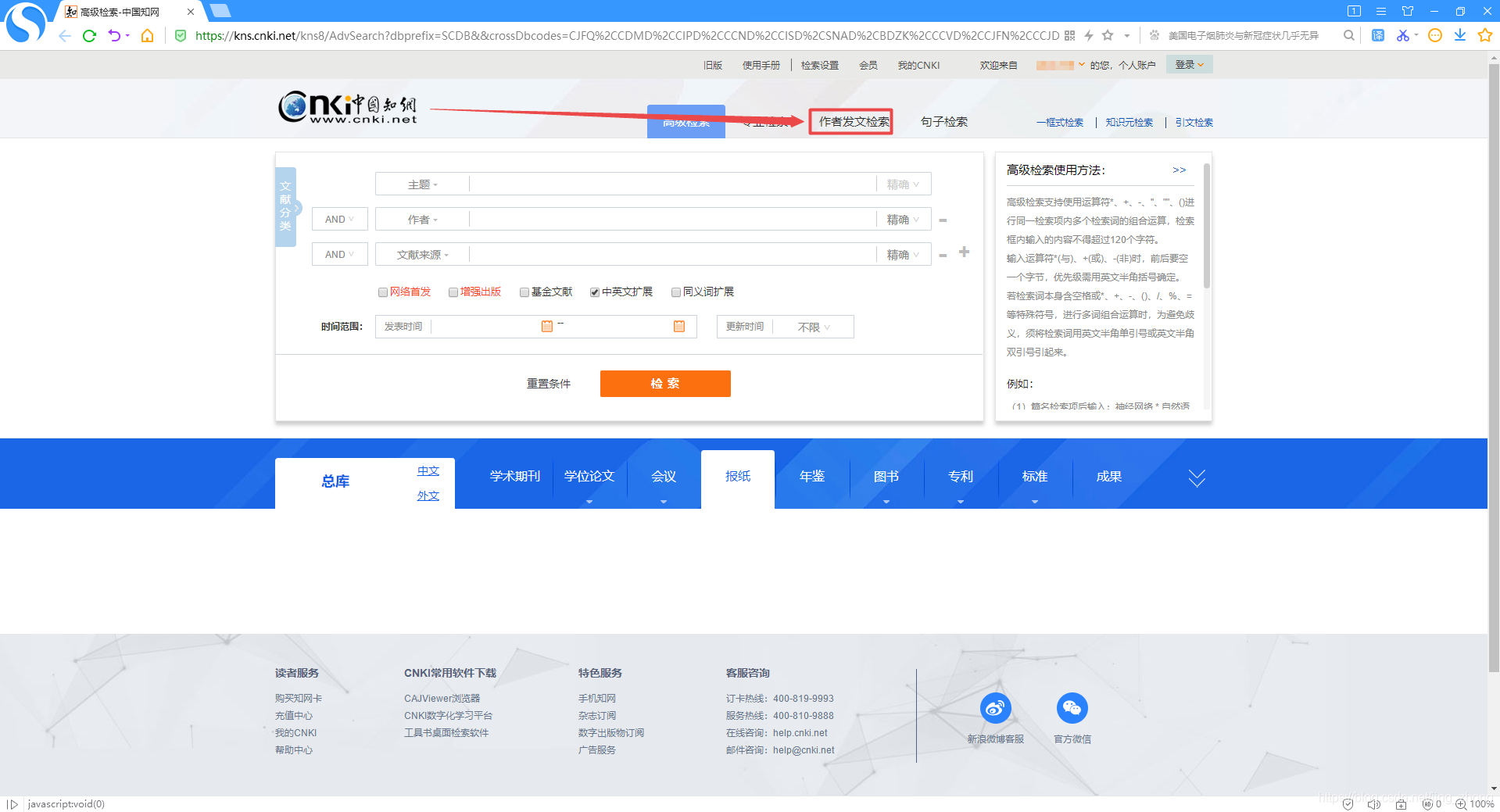
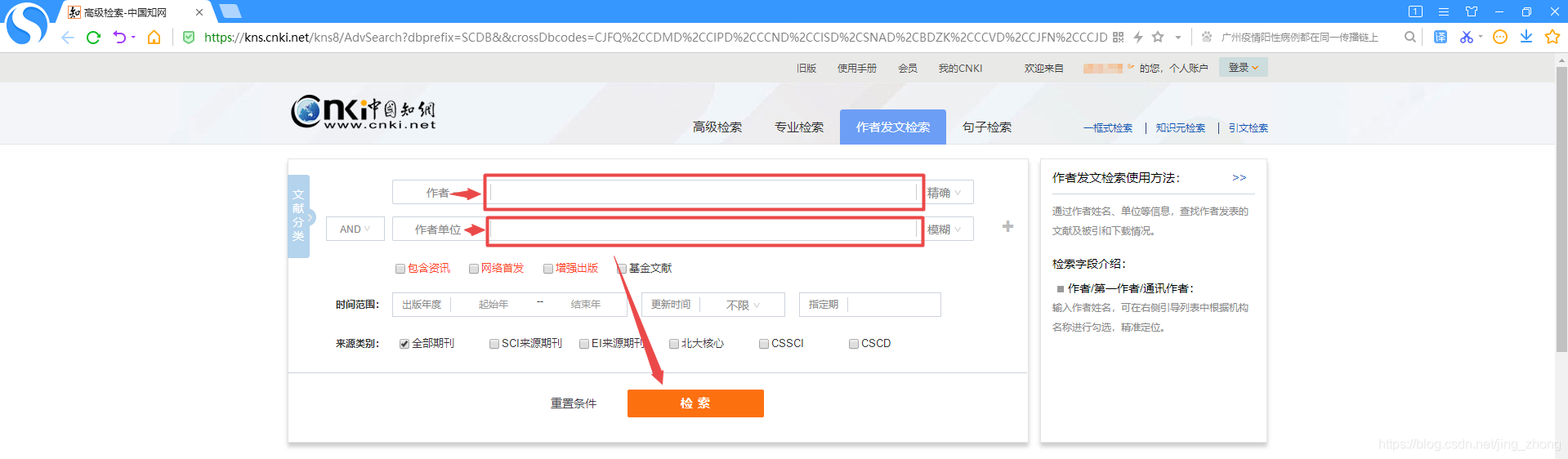
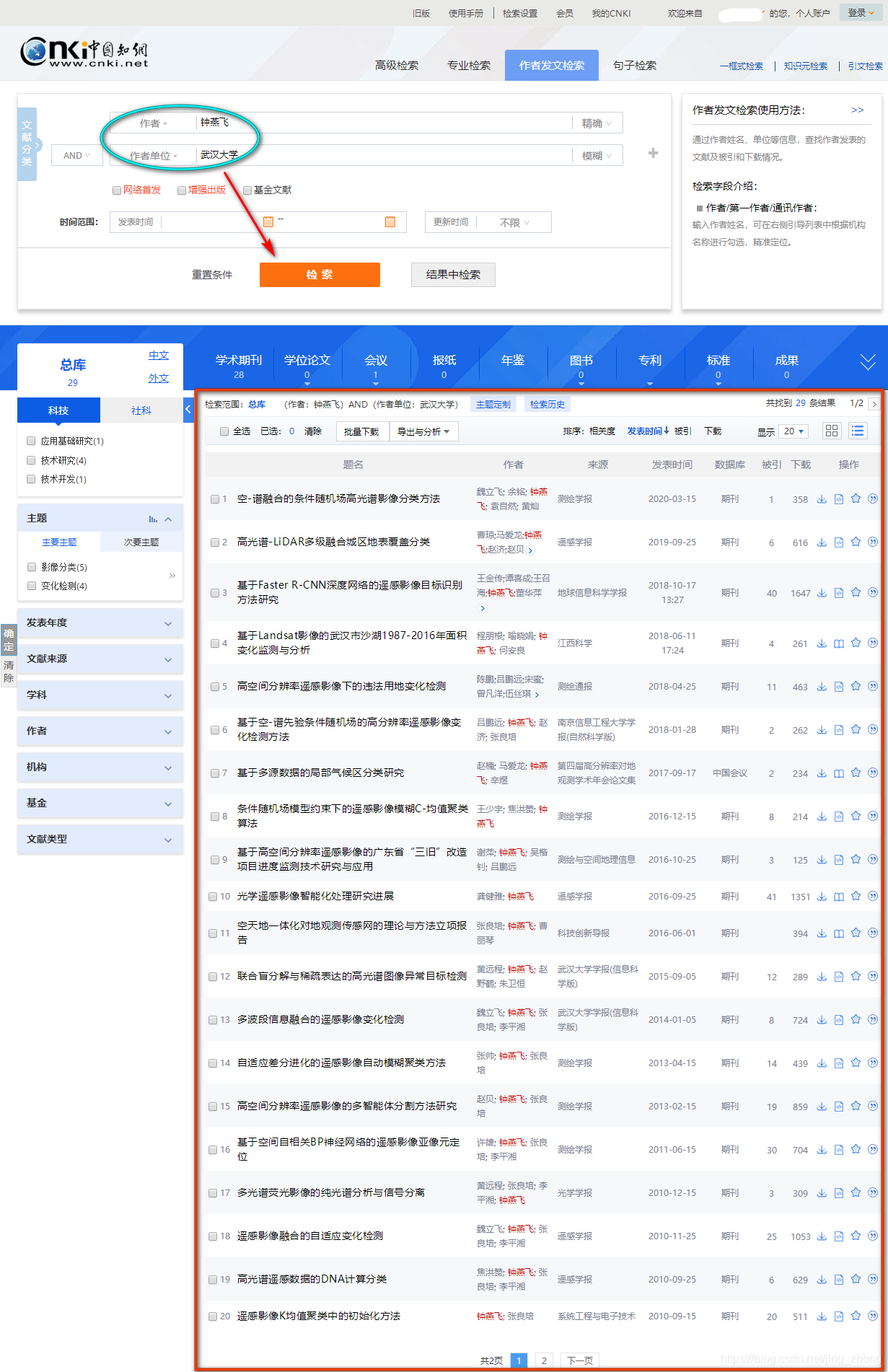
中国知网, 进入知网页面后点击搜索框右侧的高级检索,进入高级检索页面,选择作者发文检索,可以看到检索条件里只有作者和作者单位两项内容,只需在这两项右侧的文本框中分别输入作者姓名和作者单位后再点击下方的检索按钮即可得到查询结果。
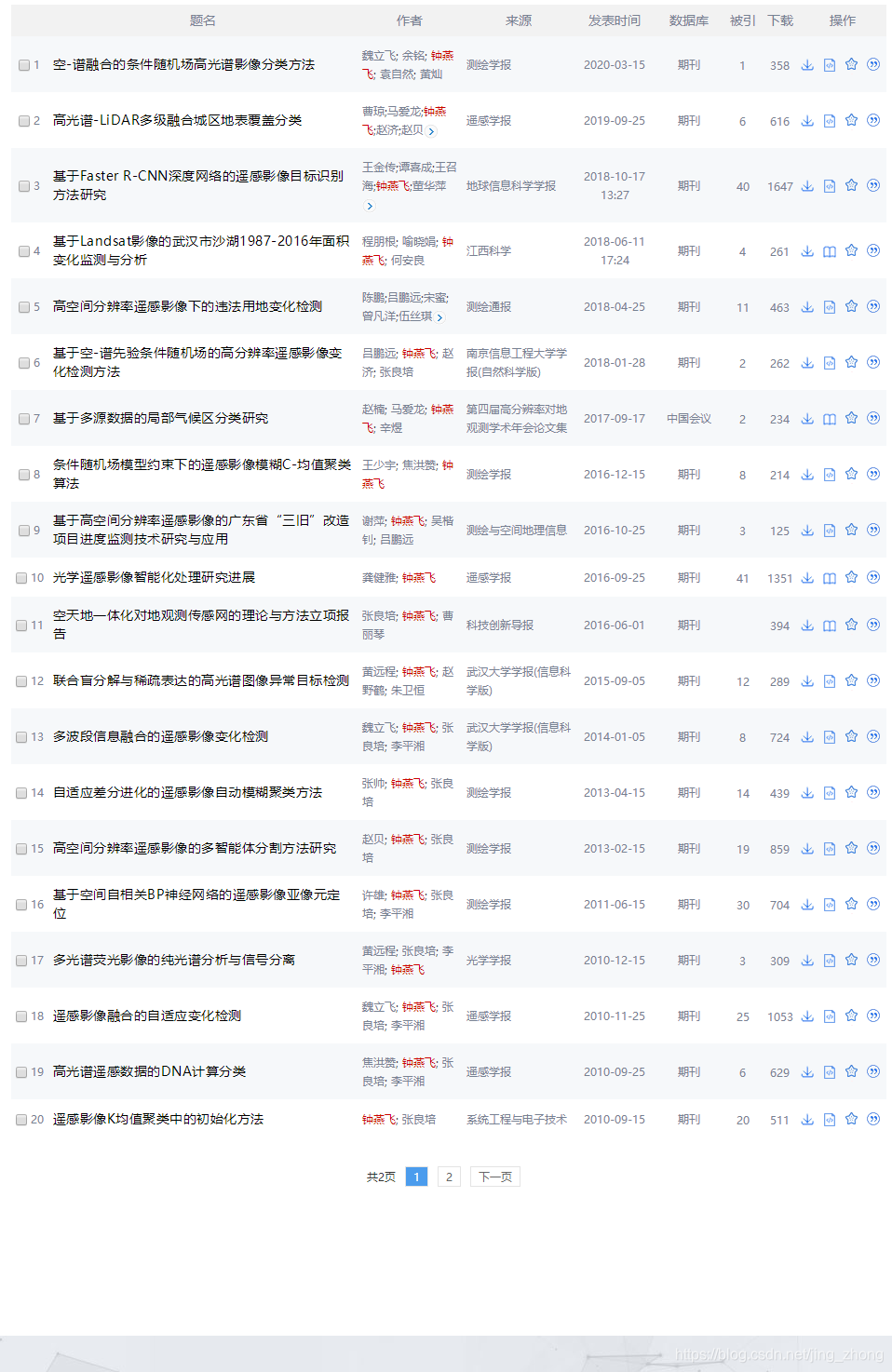
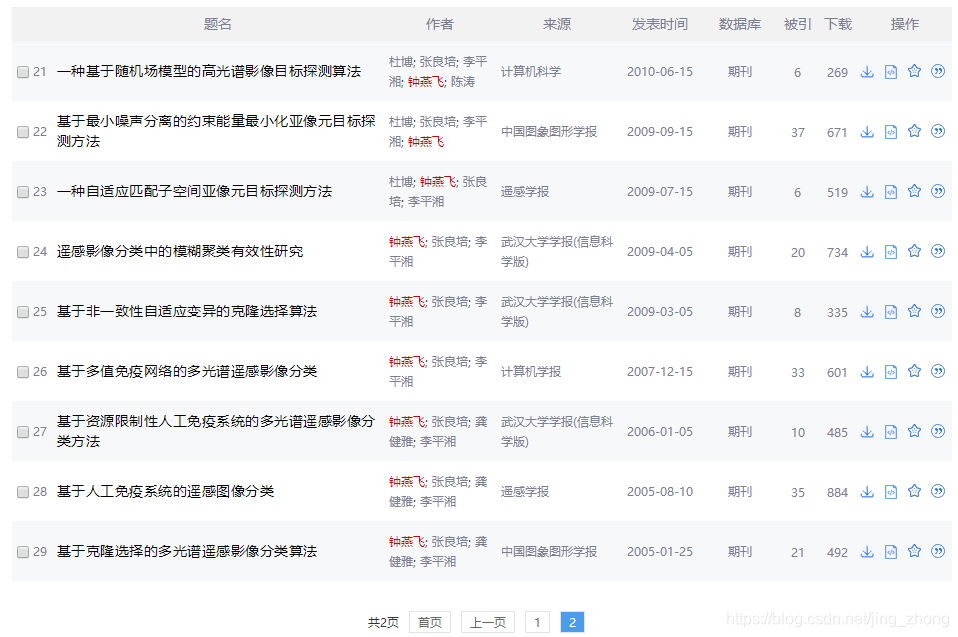
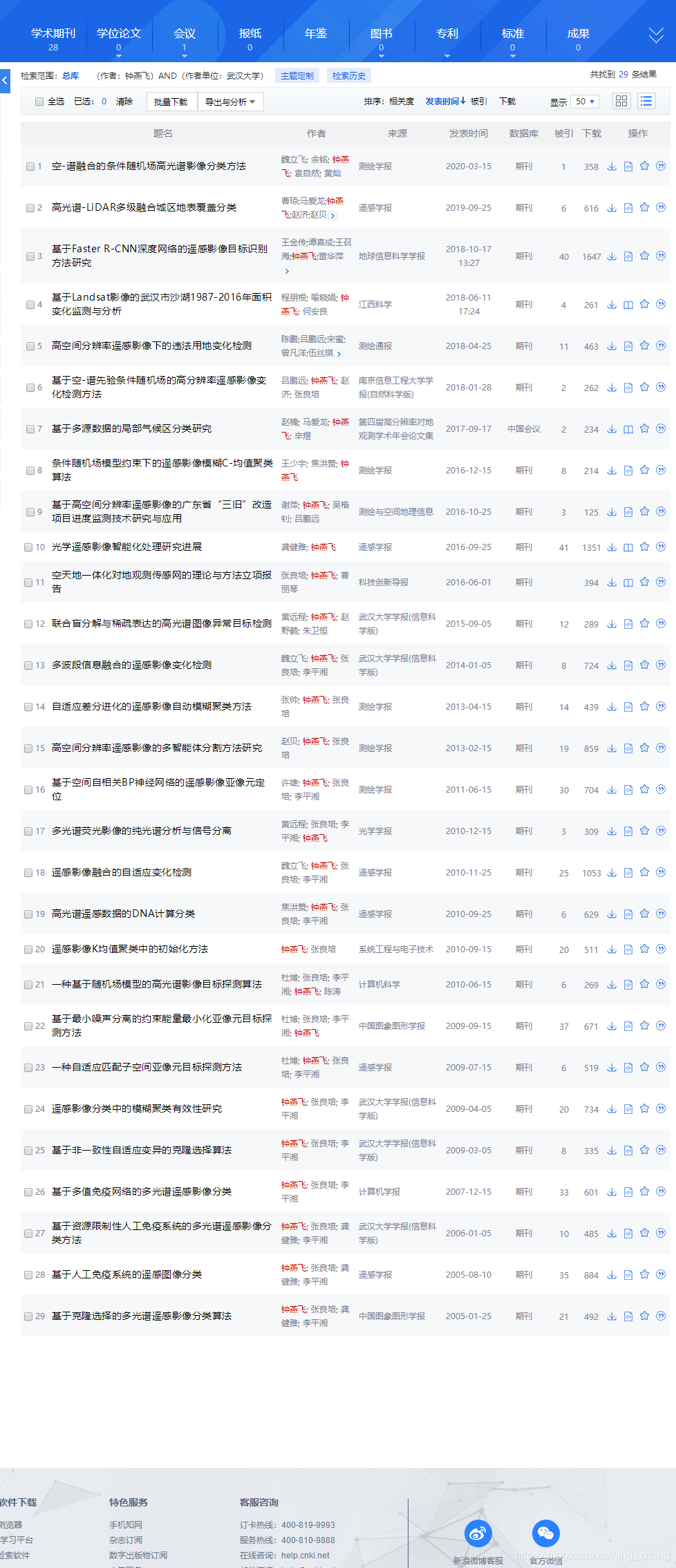
下面以武汉大学的钟燕飞教授为例进行作者发文检索,可以看到检索结果中共有29条中文论文,每页显示20条,总共被划分为2个页面。 以下两张图分别是 第1页(1-20) 和 第2页 (21-29) 所显示的检索结果。
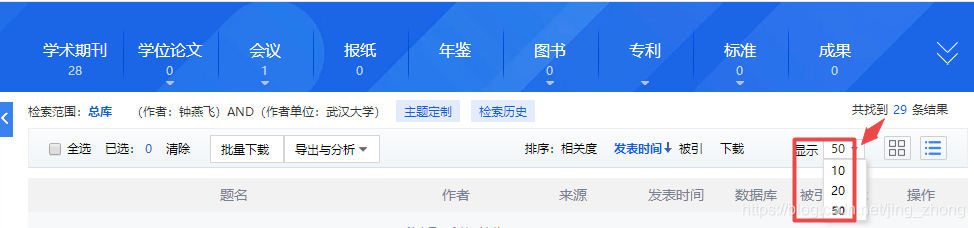
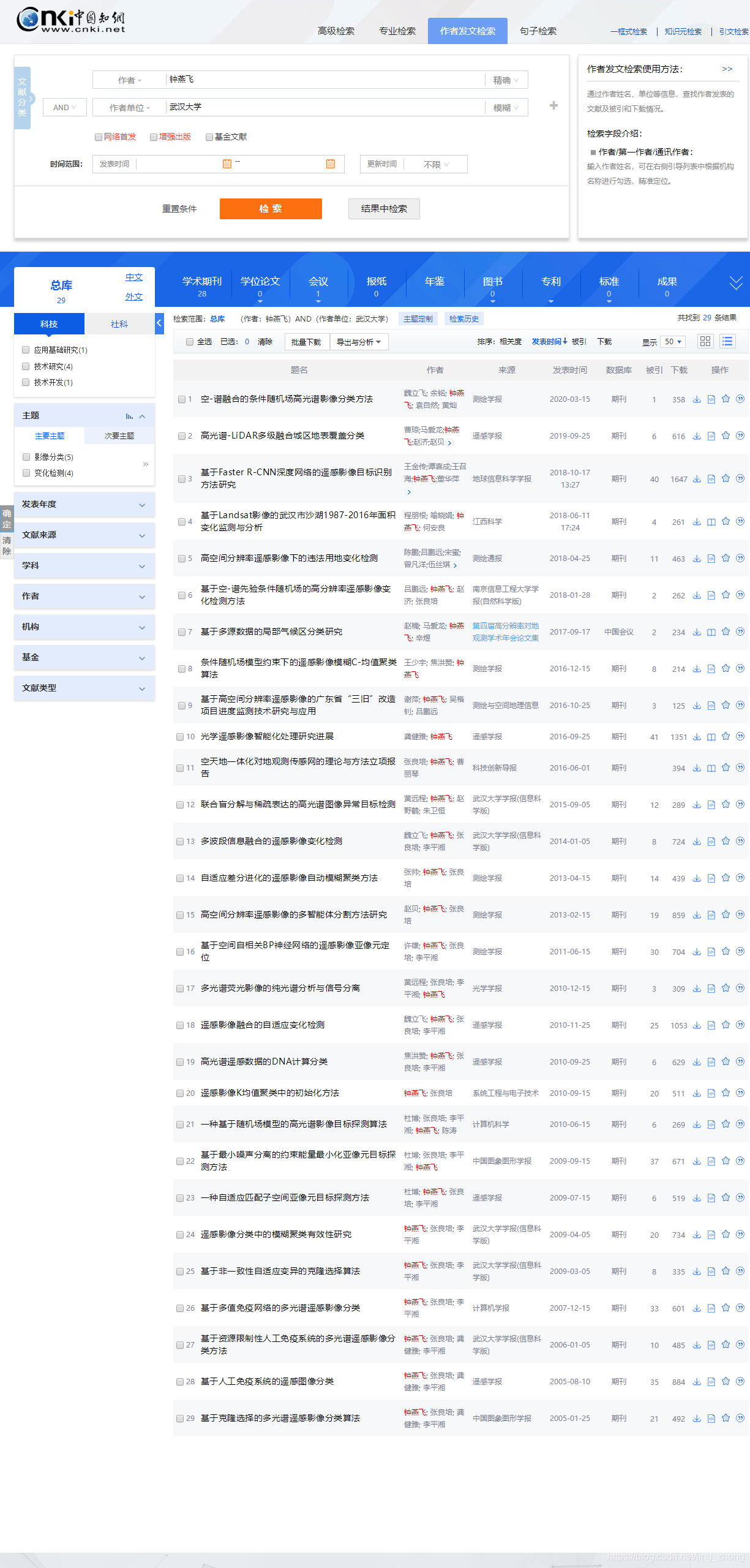
当然,如上图所示,每页所显示的条数是可以进行设置的,最多设置每页能够显示50条结果,那么29条结果就只会显示在1个页面内,如下图所示。 第1页:1~29 在学习和研究的过程当中,可能往往需要针对性地阅读某些专家学者的大量论文才能有所启发和感悟,那么首先必须将该学者的所有论文检索出来最好汇总到自己的Excel表格当中进行标记,然后针对性地去阅读,这样可能会事半功倍(因为每次检索本身就会花费自己一定的时间和精力)。 2.1 纯手工复制粘贴(针对检索结果少且页数不多 较为可行) 在这个万物互联、信息化高速发展的时代,纯手工复制粘贴的方式实属笨重,但有时在找到更好的方法之前无奈也是可以去尝试的,这里介绍将第1页的结果汇总至Excel的步骤,如果页数多的话每页方法类似。
Python解析代码ParseHTMLCNKI.py print('序号,'+'题名,'+'作者,'+'来源,'+'发表时间,'+'数据库,'+'被引次数,'+'下载次数') f = open('D:\\搜狗高速下载\\CNKIGet\\1.txt','r') # 返回一个文件对象 wf = open("D:\\搜狗高速下载\\CNKIGet\\1_parseCNKIHtml.csv",'w') wf.write('序号,'+'题名,'+'作者,'+'来源,'+'发表时间,'+'数据库,'+'被引次数,'+'下载次数'+'\n') line = f.readline() # 调用文件的 readline()方法 while line: if (line.find('') >= 0): sequence = line.strip('\n') # 去掉列表中每一个元素的换行符 sequence = sequence[sequence.find('filenameClick()" />') + 19:sequence.find('')] line= f.readline() name = line.strip('\n') # 去掉列表中每一个元素的换行符 name = name[name.find('"_blank">') + 9:name.find('')] line = f.readline() author = line.strip('\n') # 去掉列表中每一个元素的换行符 author = author[author.find('"Mark">') + 7:author.find('')] line = f.readline() source = line.strip('\n') # 去掉列表中每一个元素的换行符 source = source[source.find('BaseID=') + 13:source.find('')] line = f.readline() publishdate = line.strip('\n') # 去掉列表中每一个元素的换行符 publishdate = publishdate[publishdate.find('"date">') + 7:publishdate.find('')] line = f.readline() db = line.strip('\n') # 去掉列表中每一个元素的换行符 db = db[db.find('"data">')+7:db.find('')] line = f.readline() citied = line.strip('\n') # 去掉列表中每一个元素的换行符 if(citied.find('"_blank">')>=0): citied = citied[citied.find('"_blank">') + 9:citied.find('')] else: citied = citied[citied.find('"quote">') + 8:citied.find(' ')] line = f.readline() download = line.strip('\n') # 去掉列表中每一个元素的换行符 download = download[download.find('void(0);"') + 10:download.find('')] print(sequence+','+name+','+author+','+source+','+publishdate+','+db+','+citied+','+download) wf.write(sequence+','+name+','+author+','+source+','+publishdate+','+db+','+citied+','+download+'\n') line = f.readline() f.close() wf.close();
电脑已安装python,打开一个Python的IDE,这里使用PyCharm新建一个项目,设置好Python编译器路径,将上述的ParseHTMLCNKI.py复制到项目中后即可运行,运行后会在控制台输出解析的检索文献信息,同时这些信息也会保存到1_parseCNKIHtml.csv文件中,运行结果如下所示。 |
 浏览器里针对该页面,键盘Ctrl+A全选页面元素后再按住键盘Ctrl+C进行页面文本的复制
浏览器里针对该页面,键盘Ctrl+A全选页面元素后再按住键盘Ctrl+C进行页面文本的复制  之后在文件夹里新建一个txt文件,键盘按Ctrl+V粘贴到txt文件中,文件内容如下图所示。
之后在文件夹里新建一个txt文件,键盘按Ctrl+V粘贴到txt文件中,文件内容如下图所示。  由于虚线框内文本属于目标内容,所以需要在txt里删除目标之前和目标之后的内容,删除后结果如下图所示
由于虚线框内文本属于目标内容,所以需要在txt里删除目标之前和目标之后的内容,删除后结果如下图所示 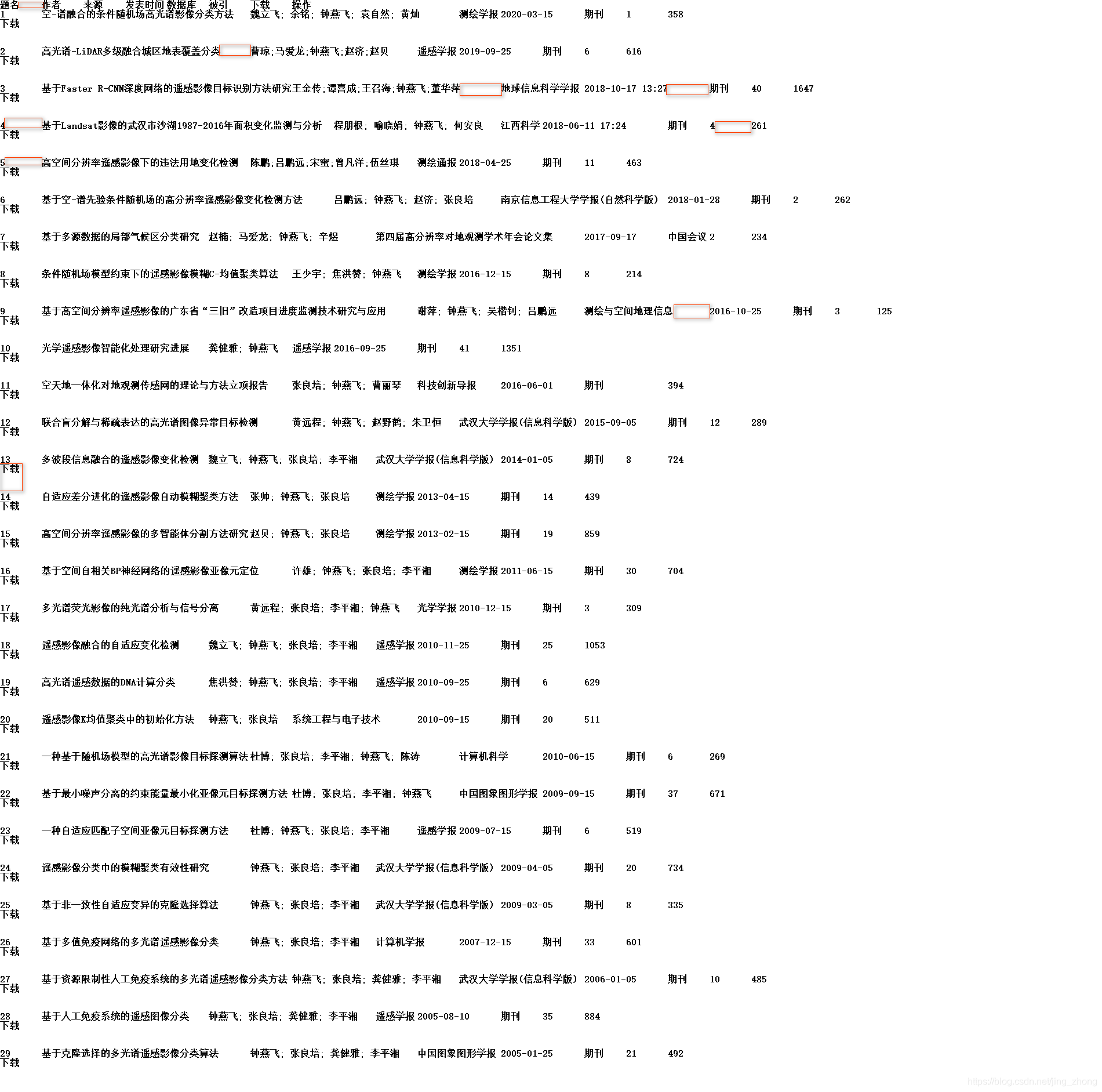 之后需要利用txt文件编辑功能中的替换,将下图中标出的这些空格替换为英文的逗号,,替换完成后如下
之后需要利用txt文件编辑功能中的替换,将下图中标出的这些空格替换为英文的逗号,,替换完成后如下 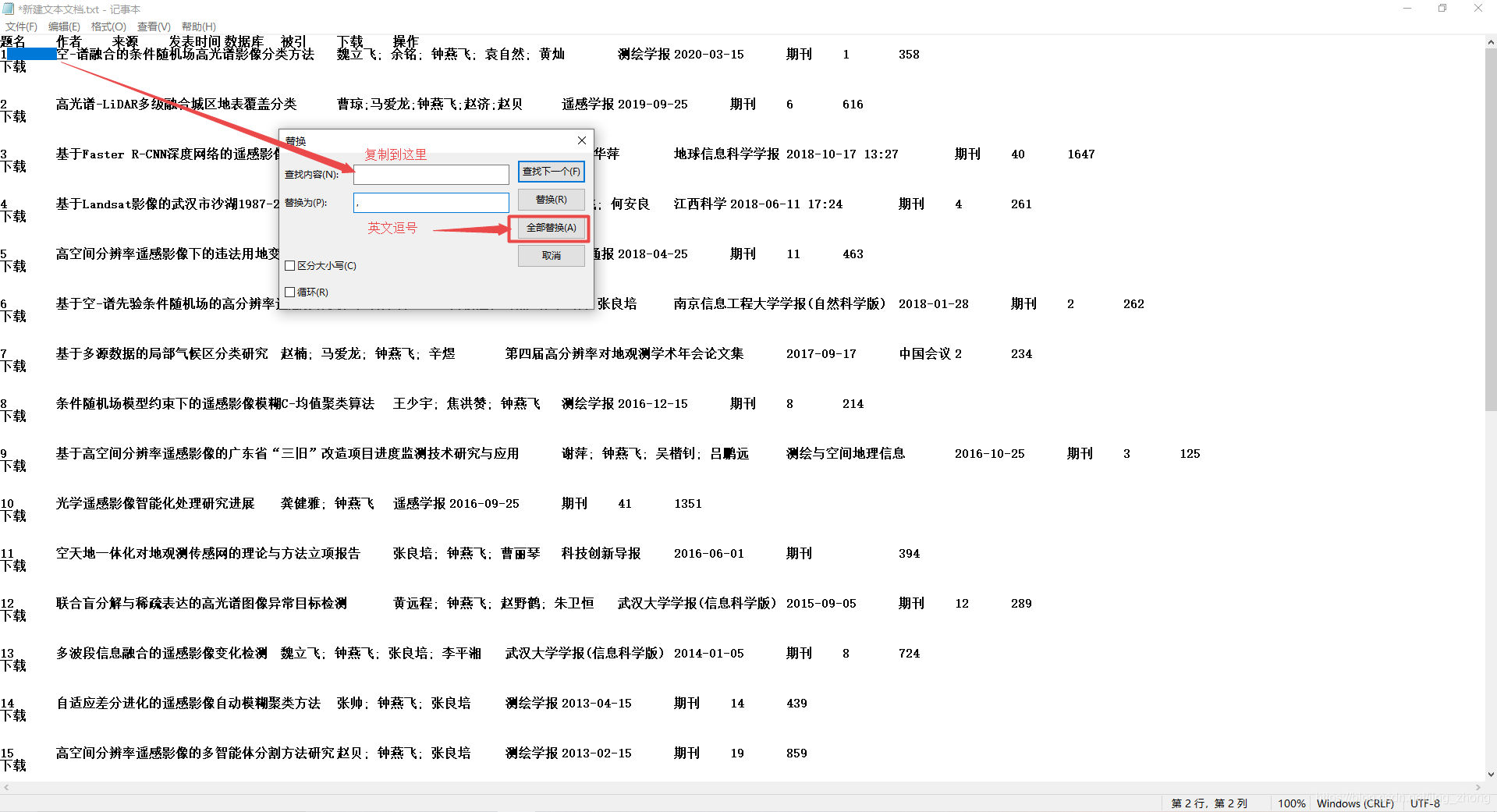
 此时,只需要将下载之前的逗号、下载这两个字以及下载下方那一行同时选中复制,在此进行替换为空即可完成
此时,只需要将下载之前的逗号、下载这两个字以及下载下方那一行同时选中复制,在此进行替换为空即可完成 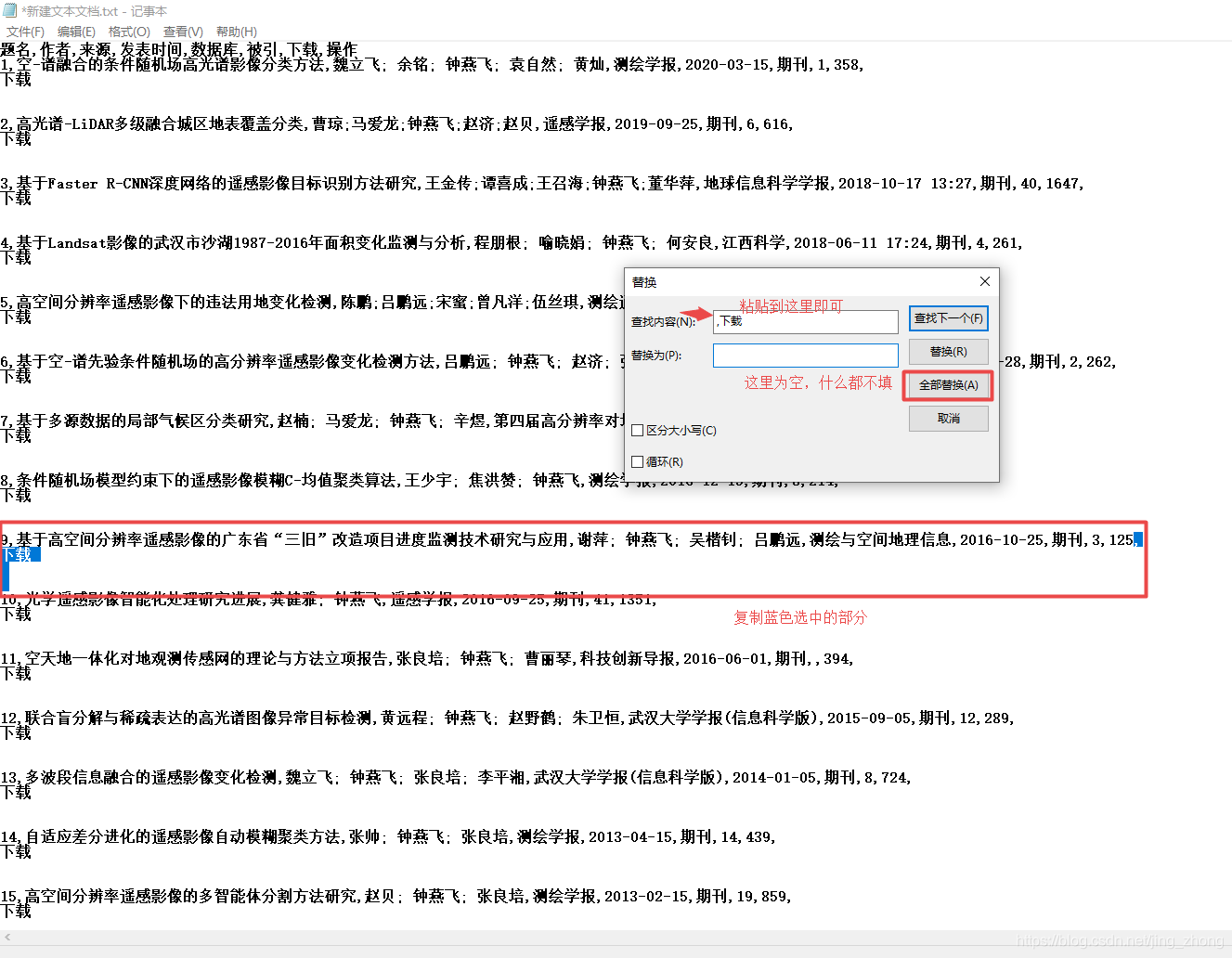
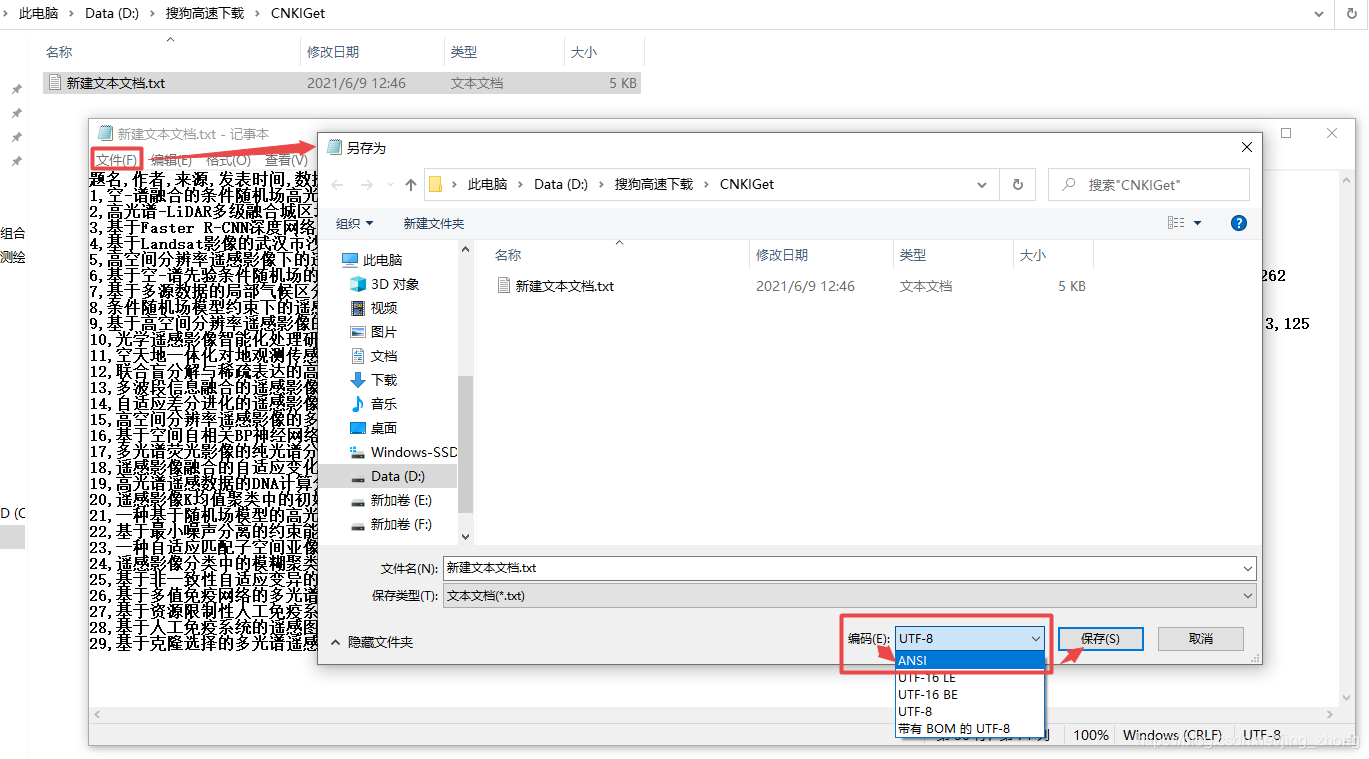
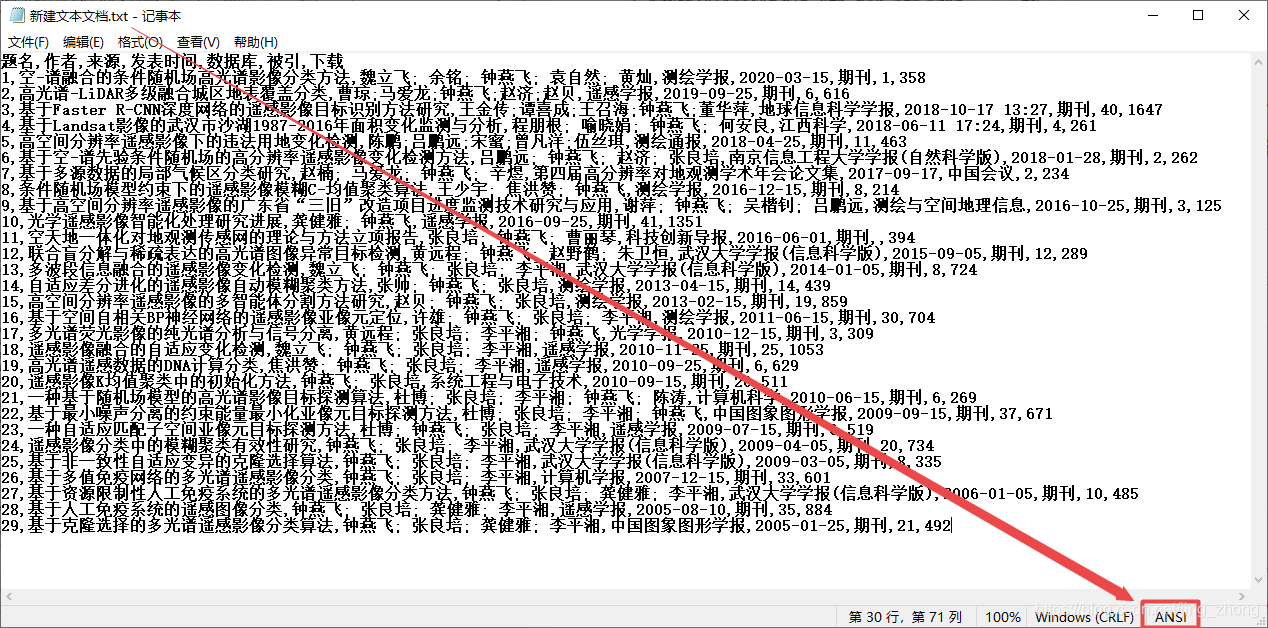
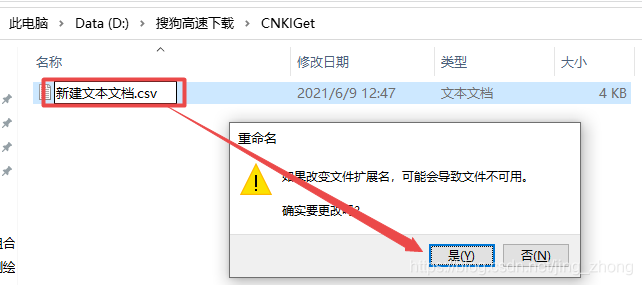
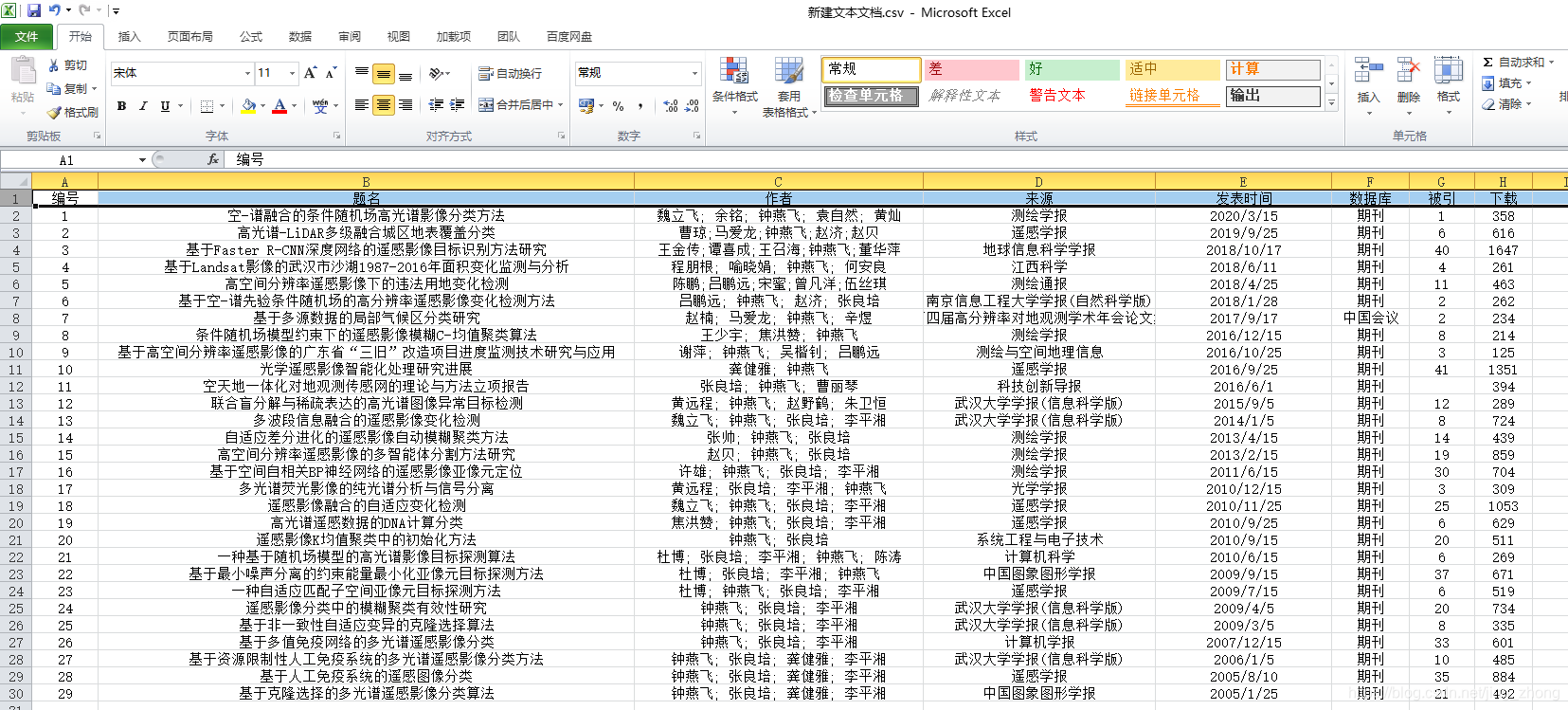
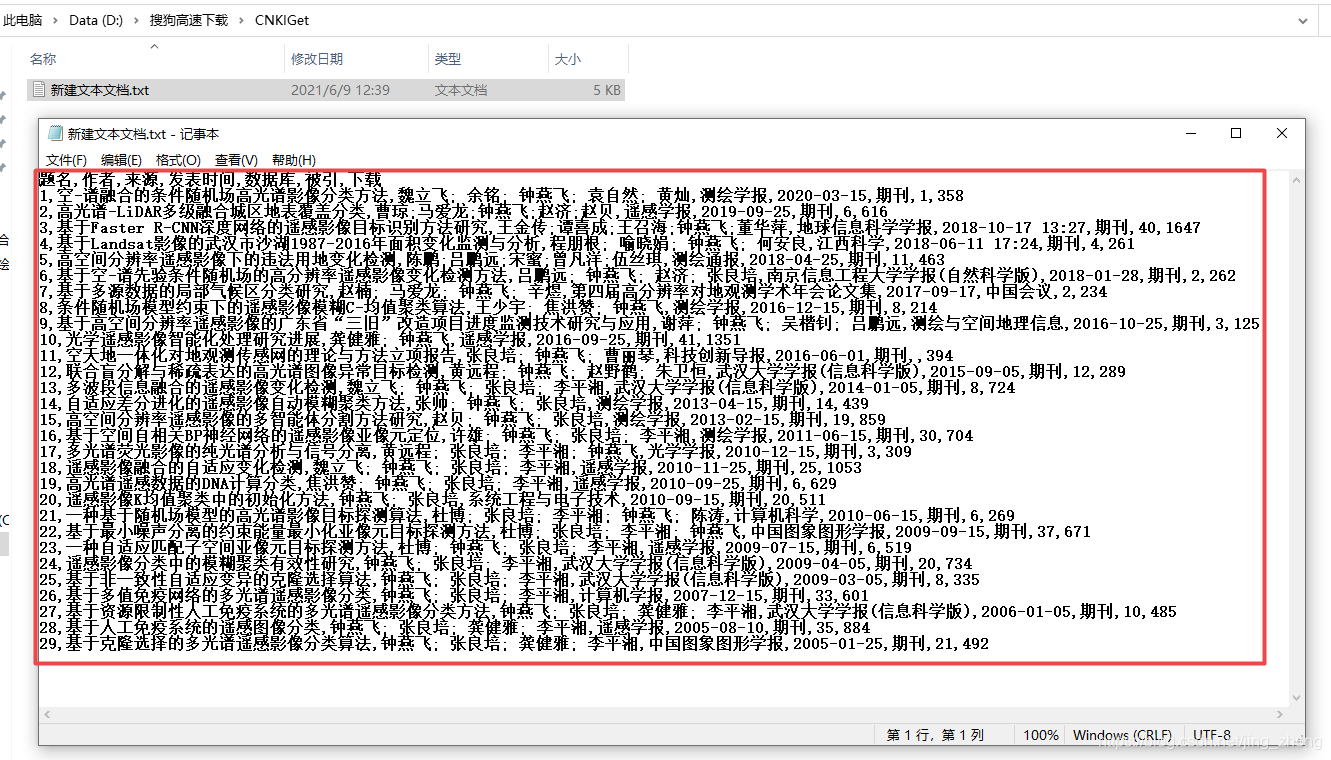 最后将新建文本文档.txt文件另存为ANSI编码后,可以将后缀名改为.csv后用Excel打开查看效果并在第一行添加编号列属性
最后将新建文本文档.txt文件另存为ANSI编码后,可以将后缀名改为.csv后用Excel打开查看效果并在第一行添加编号列属性 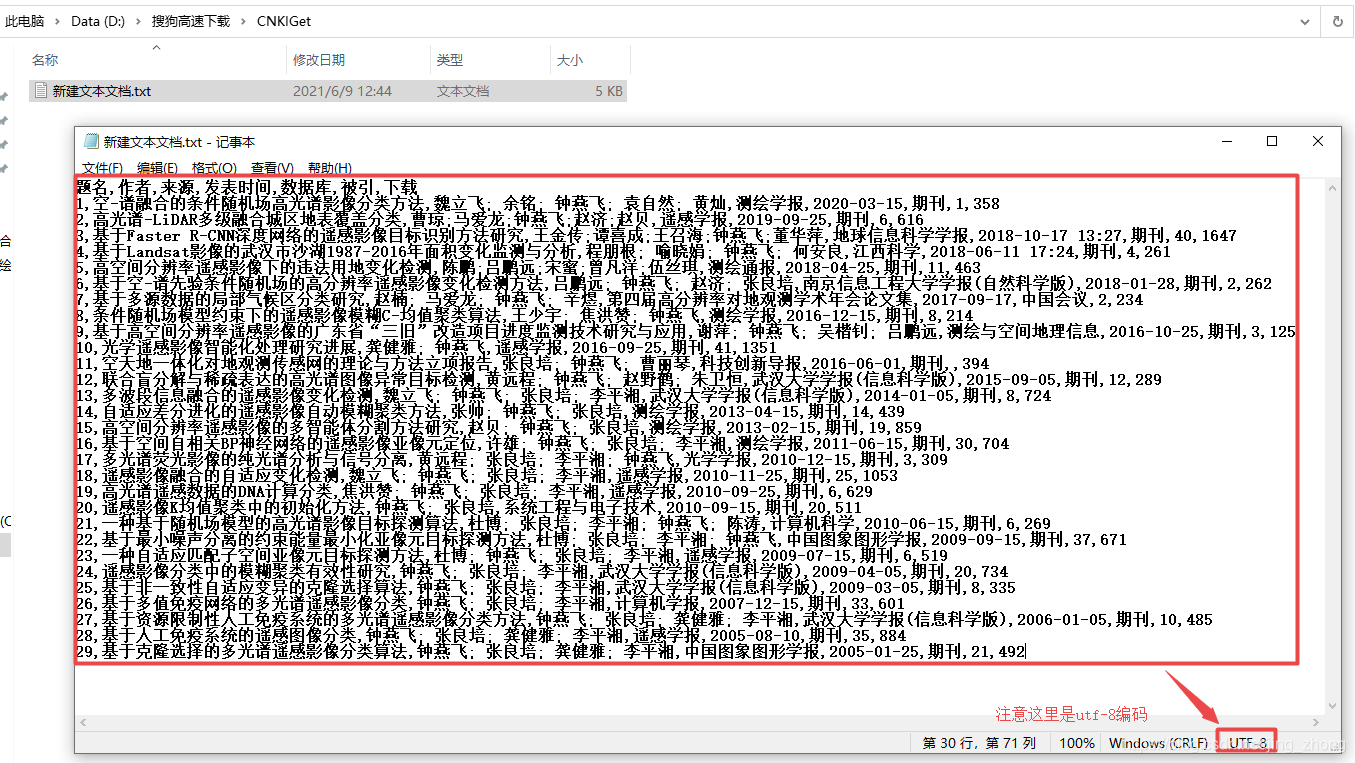
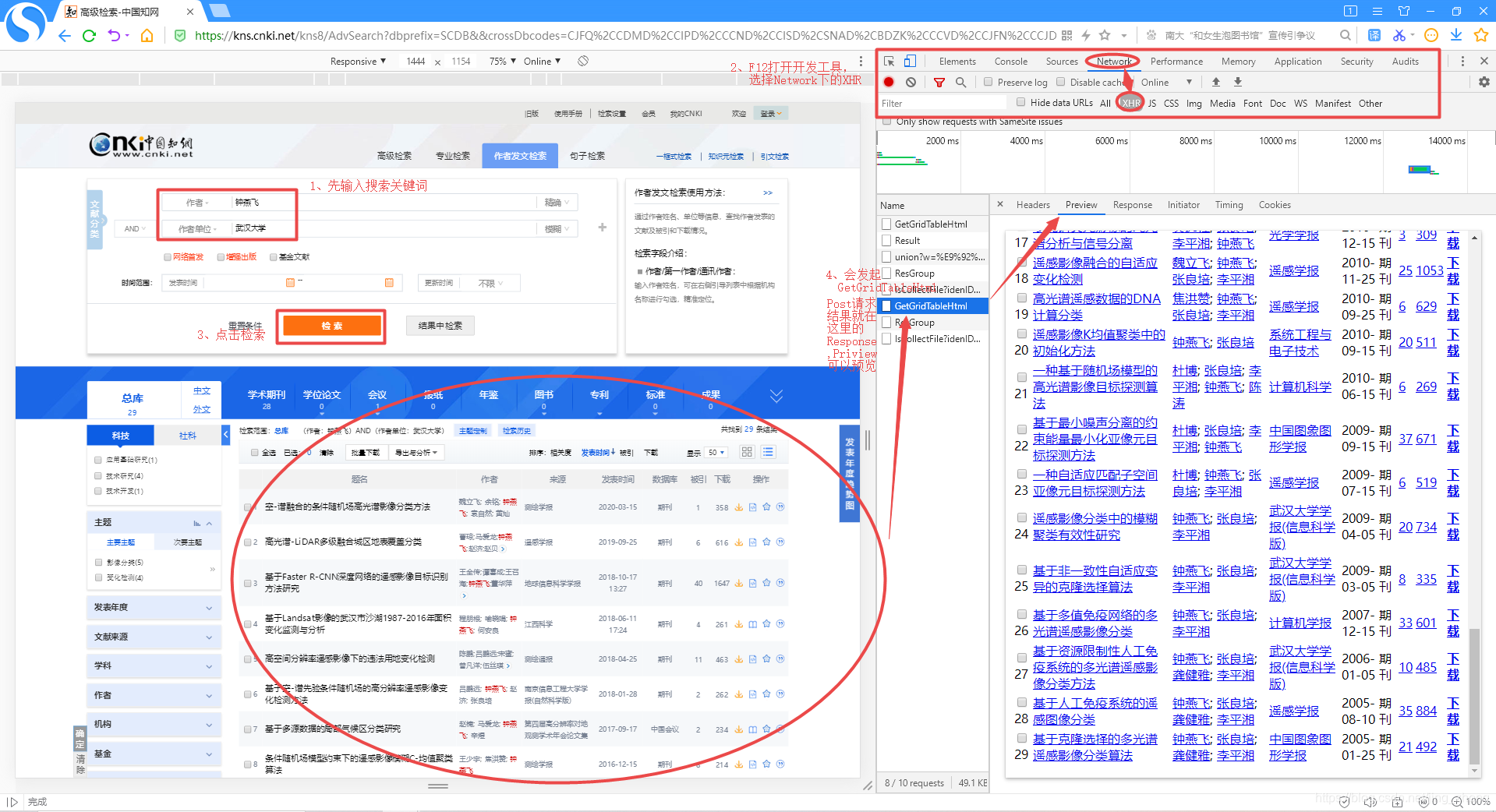 首先进入知网的作者发文检索界面,在作者对应框中输入作者姓名,在作者单位框中输入对应的作者单位,然后按F12打开开发工具页面,上方选择Network后点击中间的XHR,接下来就可以点击检索按钮进行查找了,当点击检索的那一刻,其实浏览器后台已经发起了Post方式的GetGridTableHtml请求,然后才有了页面下方的检索结果,29个检索结果对应的HTML代码就在Response中,但在Preview中可进行预览。 然后打开Response,可以看到左侧页面对应的HTML代码,鼠标点击Response下方的HTML代码内部,按住Ctrl+A全选后再按住Ctrl+C复制
首先进入知网的作者发文检索界面,在作者对应框中输入作者姓名,在作者单位框中输入对应的作者单位,然后按F12打开开发工具页面,上方选择Network后点击中间的XHR,接下来就可以点击检索按钮进行查找了,当点击检索的那一刻,其实浏览器后台已经发起了Post方式的GetGridTableHtml请求,然后才有了页面下方的检索结果,29个检索结果对应的HTML代码就在Response中,但在Preview中可进行预览。 然后打开Response,可以看到左侧页面对应的HTML代码,鼠标点击Response下方的HTML代码内部,按住Ctrl+A全选后再按住Ctrl+C复制 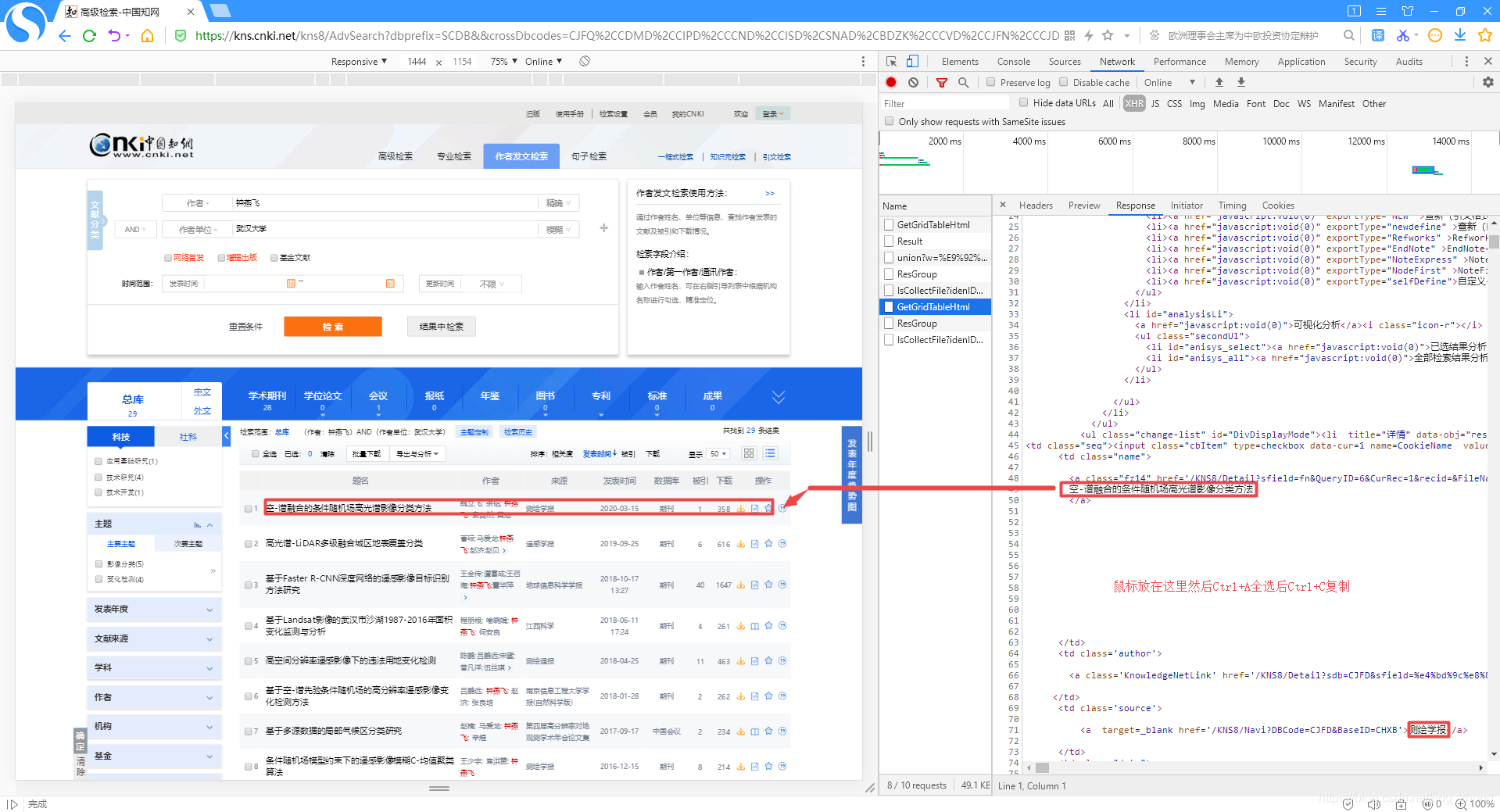
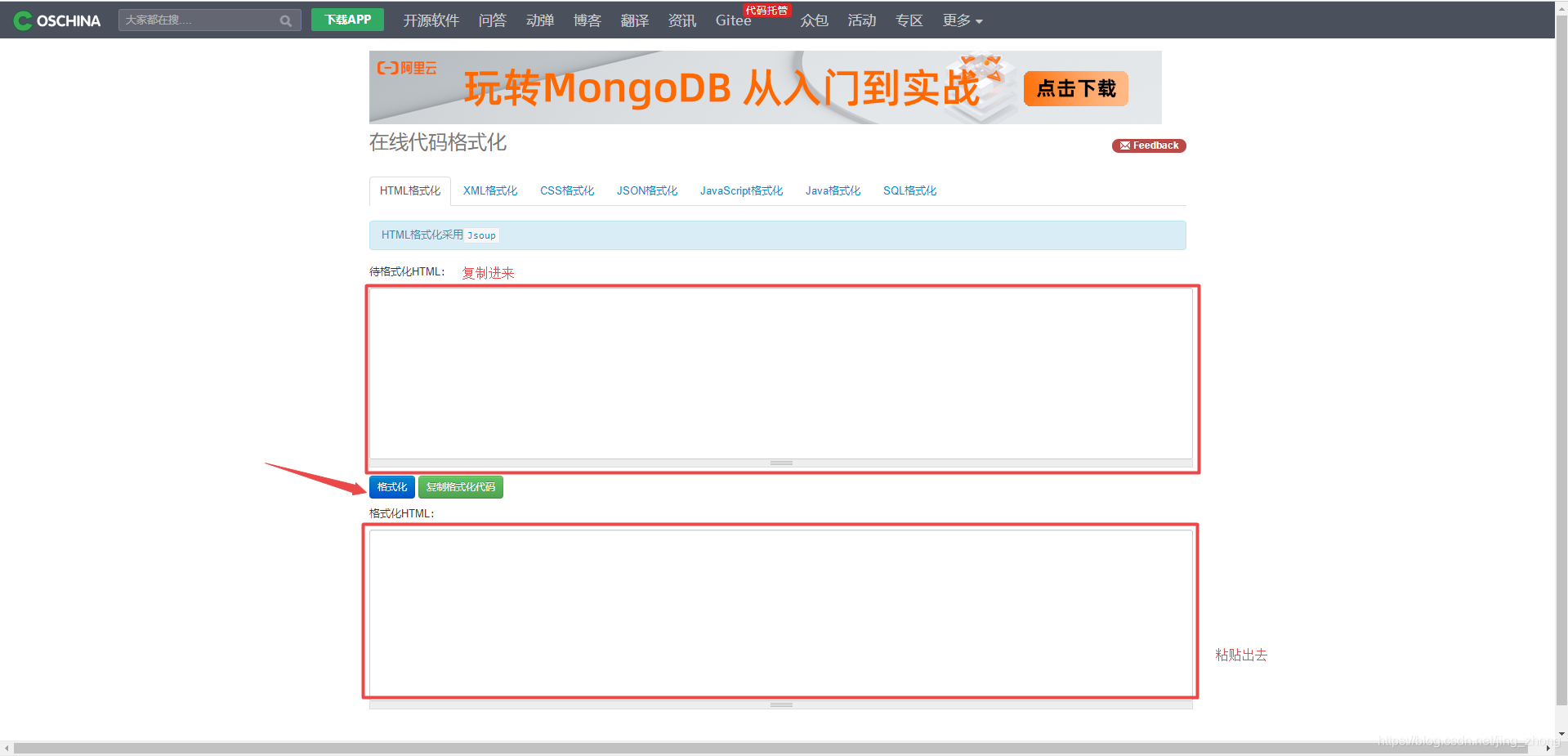 利用在线代码格式化工具将剪切板中复制的页面HTML代码粘贴到待格式化HTML下方的文本框中后,点击格式化,待格式化完成后,点击复制格式化代码,将复制的代码粘贴到一个新建的记事本txt文件中即可。
利用在线代码格式化工具将剪切板中复制的页面HTML代码粘贴到待格式化HTML下方的文本框中后,点击格式化,待格式化完成后,点击复制格式化代码,将复制的代码粘贴到一个新建的记事本txt文件中即可。 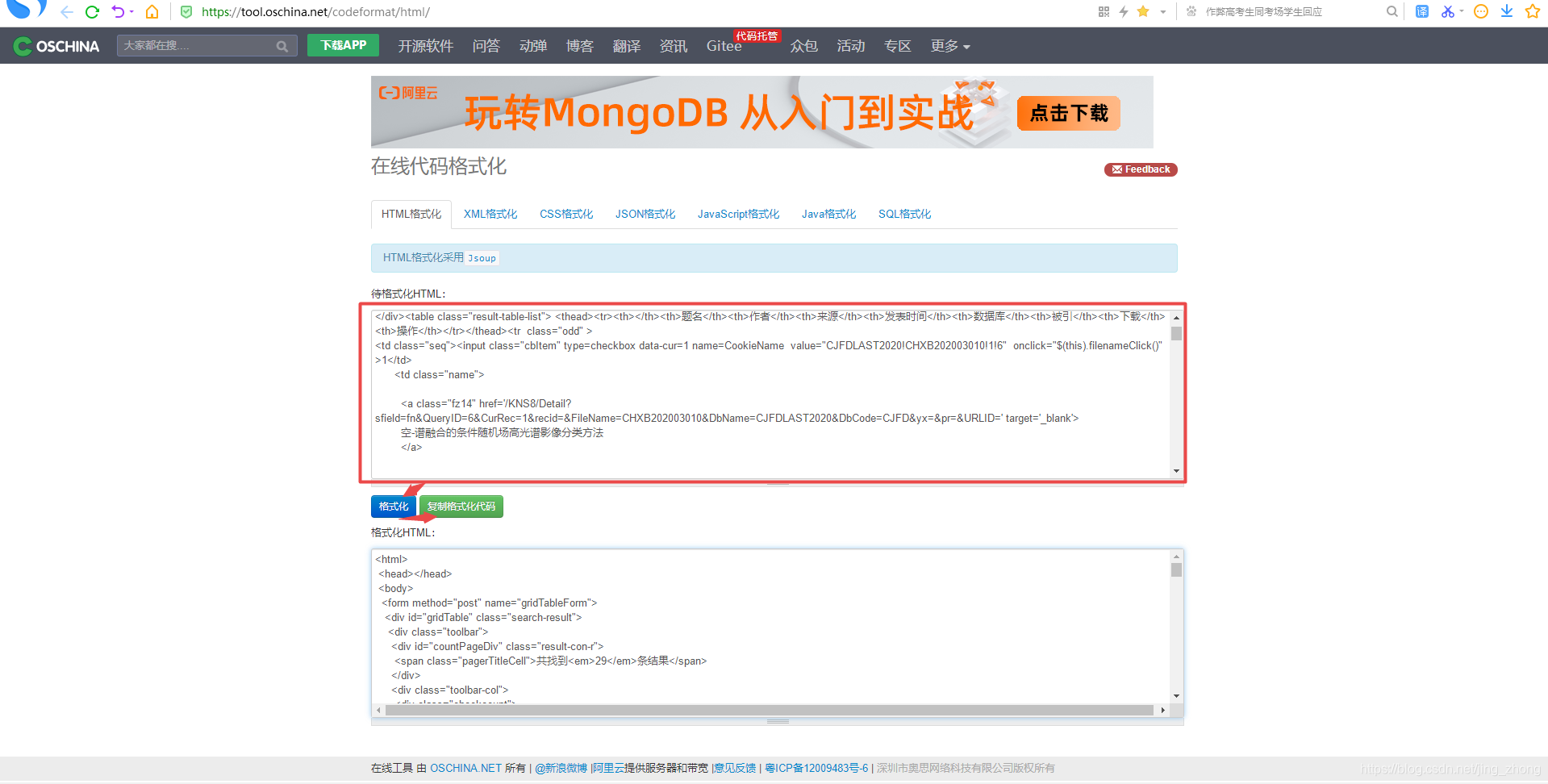 在文件夹中新建一个记事本文件1.txt(注意保存为ANSI编码)后,将复制的格式化代码粘贴其中,如下图所示。
在文件夹中新建一个记事本文件1.txt(注意保存为ANSI编码)后,将复制的格式化代码粘贴其中,如下图所示。 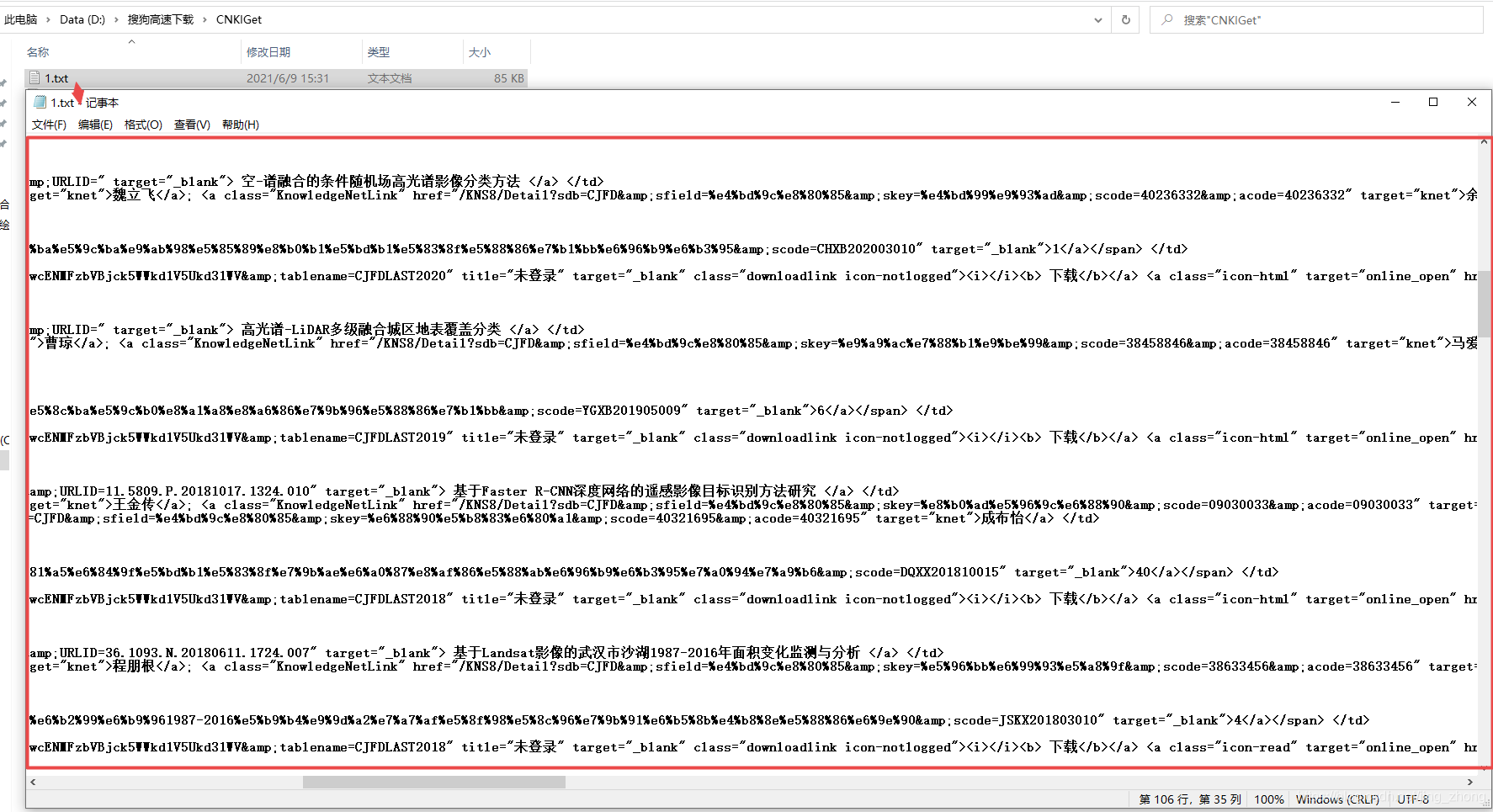

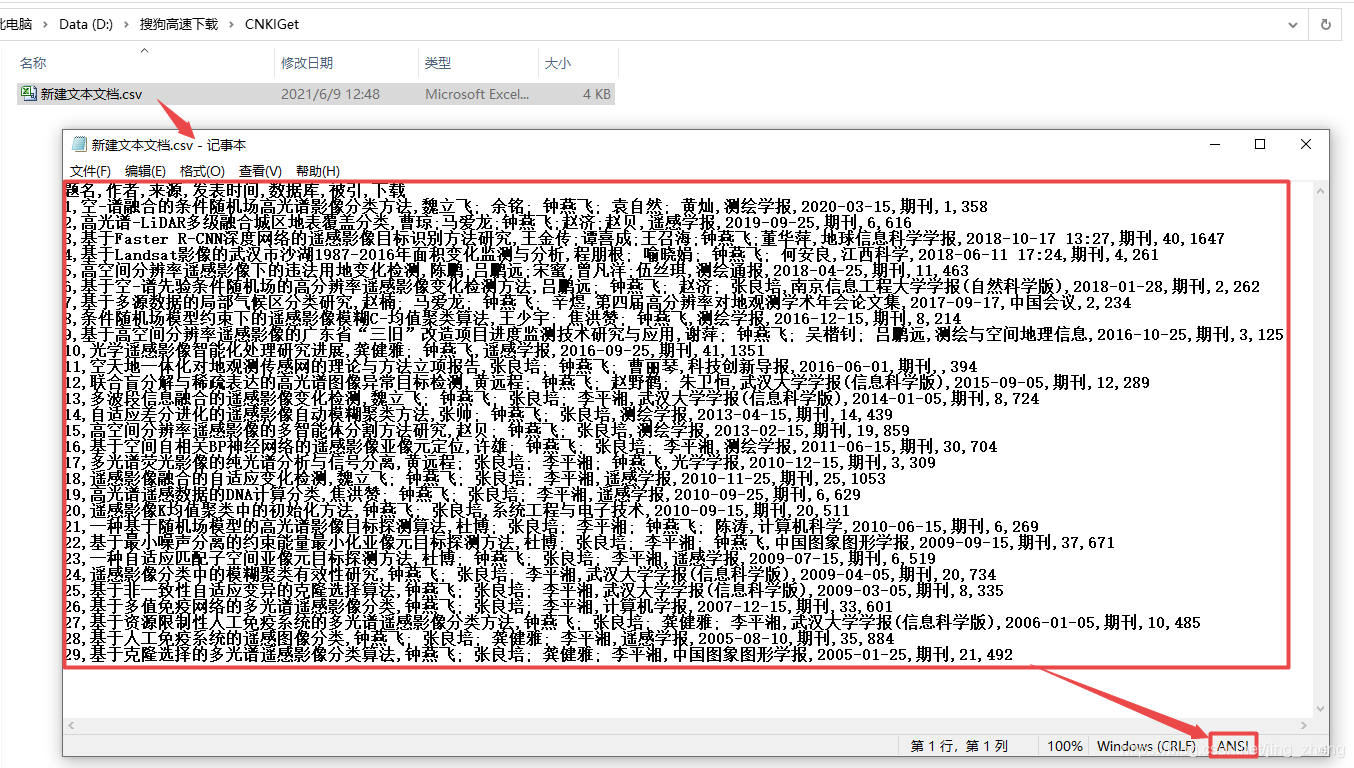
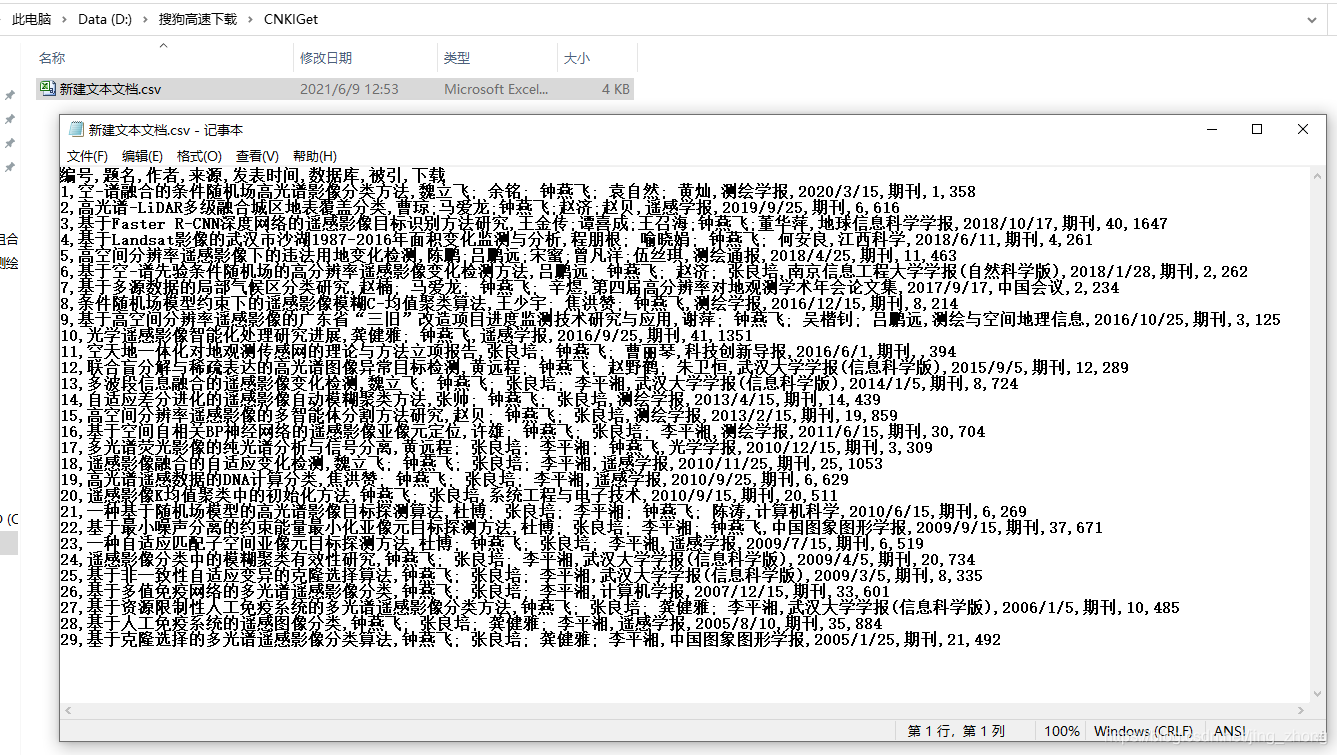
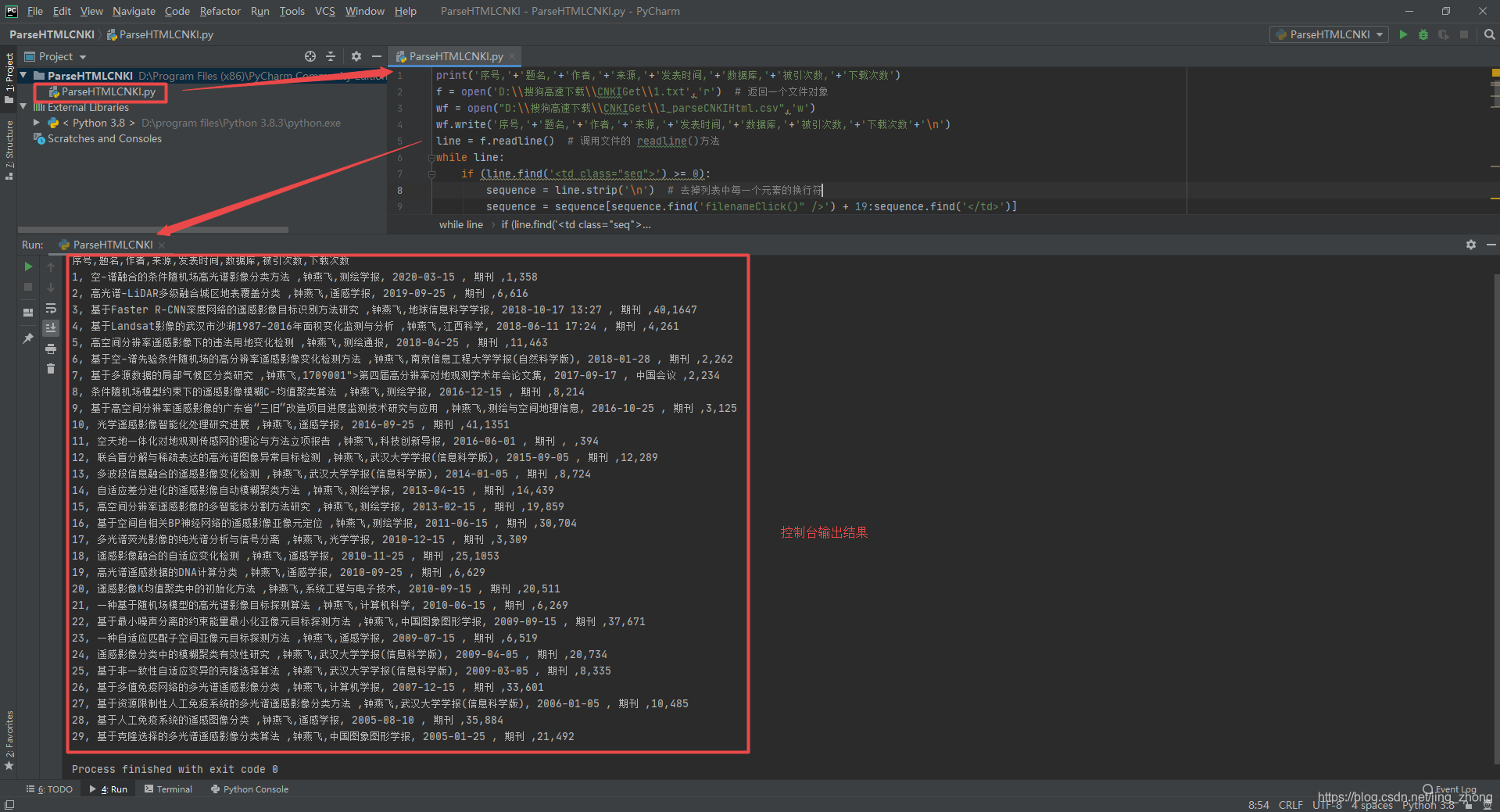 记事本打开1_parseCNKIHtml.csv文件查看结果
记事本打开1_parseCNKIHtml.csv文件查看结果  Excel打开1_parseCNKIHtml.csv文件查看结果
Excel打开1_parseCNKIHtml.csv文件查看结果 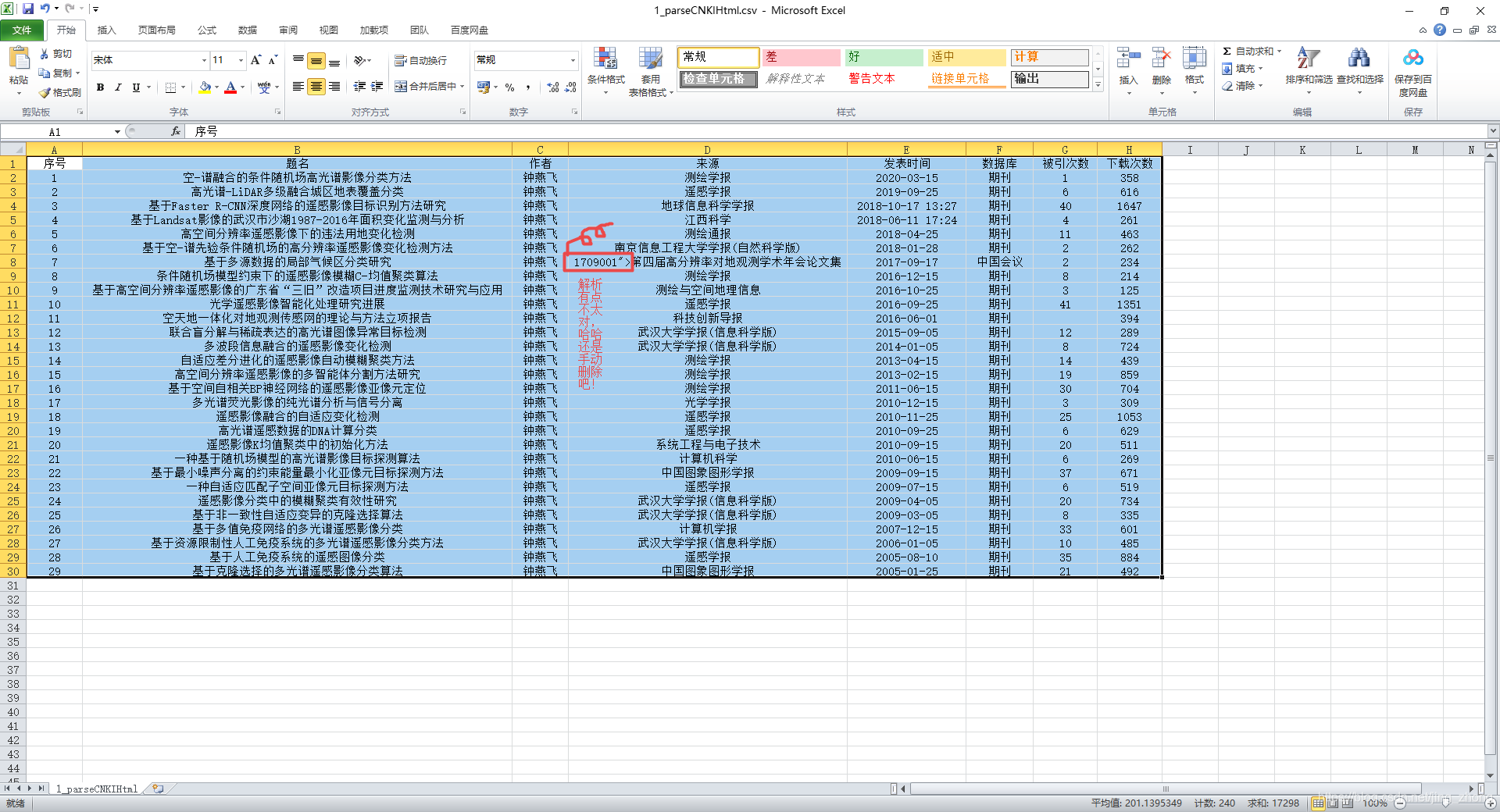
【本文地址】