| Scipy计算皮尔逊相关系数用法以及p | 您所在的位置:网站首页 › 相关系数和显著性水平的关系是什么 › Scipy计算皮尔逊相关系数用法以及p |
Scipy计算皮尔逊相关系数用法以及p
|
使用scipy计算皮尔逊相关系数时会返回相关系数和p-value两个值,刚开始把p-value和置信度当做了一回事,后来经过查阅资料之后才了解到并不是那样,现记录下来供自己备忘和有需要的同学参考: 一、API用法scipy.stats.pearsonr(x, y) 皮尔逊相关系数和p值用于测试非相关性。 皮尔逊相关系数测量两个数据集之间的线性关系。 p值的计算依赖于每个数据集均呈正态分布的假设。与其他相关系数一样,该皮尔逊相关系数取值在-1和+1之间,为0时表示没有相关性。 -1或+1的相关性表示存在明确的线性关系。 正相关表示,随着x的增加,y也随之增加。 负相关性表示随着x增加,y减小。 p值大致表示不相关的系统生成的数据集具有Pearson相关性至少与从这些数据集计算得出的数据一样极端的概率。 p值大致表示不相关系统产生的数据集的概率,这些数据集至少与从这些数据集计算的数据集具有相同的极端性。 p值表示对x和y不相关(即真实总体相关系数为零)的零假设的检验。因此,样本相关系数接近零(即弱相关)将趋向于为您提供较大的p值,而系数接近1或-1(即强正/负相关性)将为您提供较小的p值。 参数: x:(N,) array_like 输入数组。 y:(N,) array_like 输入数组。 返回值: r:float 皮尔逊的相关系数,[-1,1]之间。 p-value:float Two-tailed p-value。 注: p值越小,表示相关系数越显著,一般p值在500个样本以上时有较高的可靠性。 警告: PearsonRConstantInputWarning 如果输入是常量数组则引发。在这种情况下,相关系数未定义,因此返回np.nan。 PearsonRNearConstantInputWarning 如果输入为“nearly”常数则引发。数组x被认为几乎恒定,如果norm(x - mean(x)) < 1e-13 * abs(mean(x))。计算中的数值误差x - mean(x)在这种情况下,可能会导致r的计算不正确。 注意: 相关系数的计算如下: r = ∑ ( x − m x ) ( y − m y ) ∑ ( x − m x ) 2 ∑ ( y − m y ) 2 r=\frac{\sum{(x-m_x)(y-m_y)}}{\sqrt{\sum{(x-m_x)^2}\sum{(y-m_y)^2}}} r=∑(x−mx)2∑(y−my)2 ∑(x−mx)(y−my) 其中 m x m_x mx是向量 x x x的均值和, m y m_y my是向量 y y y的均值。 假设x和y是从独立的正态分布中得出的(因此总体相关系数为0),则样本相关系数r的概率密度函数为: (1 - r**2)**(n/2 - 2) f(r) = --------------------- B(1/2, n/2 - 1)其中n是样本数,B是β函数。有时将其称为r的精确分布,在pearsonr中用于计算p-value。该分布是间隔[-1,1]上的β分布,形状参数a = b = n /2-1。根据SciPy实现β分布的情况,r的分布为: dist = scipy.stats.beta(n/2 - 1, n/2 - 1, loc=-1, scale=2) # a,b: 形状参数 # loc: [可选]位置参数。默认值= 0 # scale: [可选]比例参数。默认值= 1注:β分布-在概率论中,贝塔分布,也称Β分布,是指一组定义在(0,1) 区间的连续概率分布。 pearsonr返回的p-value是two-sided p-value。对于具有相关系数r的给定样本,p-value是从具有零相关性的总体中抽取的随机样本x’和y’的abs(r’)大于或等于abs®的概率。根据上面显示的对象dist,给定r和长度n的p-value可以计算为: # dist.cdf:累计分布函数,是概率密度函数的积分 p = 2*dist.cdf(-abs(r))当n为2时,上述连续分布不是well-defined。当形状参数a和b接近a=b=0时,β分布的极限可以解释为在r=1和r=-1处具有等概率质量的离散分布。更直接地说,我们可以观察到,给定数据x=[x1,x2]和y=[y1,y2],并假设x1!=x2和y1!=y2,r的唯一可能值是1和-1。因为长度为2的任何样本x’和y’的abs(r’)将为1,因此长度为2的样本的two-sided p-value始终为1。 二、p-value从上面可以看出,p-value是通过计算β分布在abs(r’)大于等于abs®的区域的累计分布函数值而得出的。 在科学研究的许多领域,p值小于0.05被认为是确定实验数据可靠性的金标准。换句话说,p值低于该阈值(显著水平)的结论是可靠的。 在满足相关系数显著的条件下,相关系数越大,相关性就越强。 可视化代码如下: import numpy as np import matplotlib.pyplot as plt from scipy.stats import beta n = 12 # dist = beta(n/2 - 1, n/2 - 1, loc=-1, scale=2) # print(dist) # PDF 概率分布函数 quantile = np.linspace(-2, 2, 1000) R = beta.pdf(quantile, n/2 - 1, n/2 - 1, loc=-1, scale=2) plt.plot(quantile, R, "-") r = 0.5 plt.axhline(y=0, linestyle="--", color='orangered') plt.axvline(x=r, linestyle="--", color='orangered') plt.axvline(x=-r, linestyle="--", color='orangered') plt.show() # dist.cdf:累计分布函数,是概率密度函数的积分 dist = beta(n/2 - 1, n/2 - 1, loc=-1, scale=2) p = 2*dist.cdf(-abs(r)) print(p) # 0.0978546142578125绘图结果: 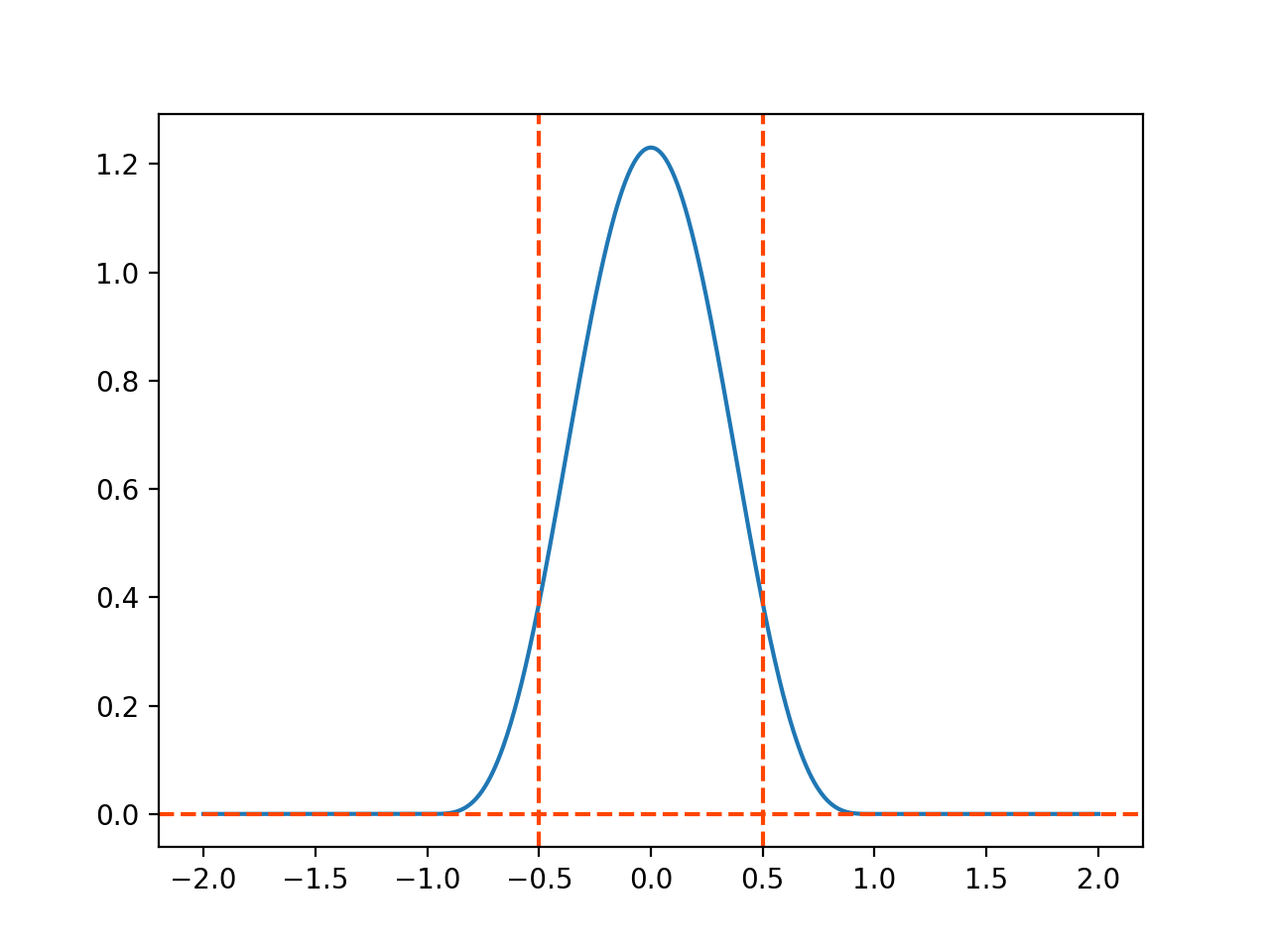
注:p-value即为概率分布函数(图中蓝色曲线)和x=r,x=-r,y=0(图中三条橘色虚线)围成的区域的面积。 API源码 三、置信度也称为可靠度,或置信水平、置信系数,即在抽样对总体参数作出估计时,由于样本的随机性,其结论总是不确定的。置信区间的跨度是置信水平的正函数,即要求的把握程度越大,势必得到一个较宽的置信区间,这就相应降低了估计的准确程度。置信水平是指总体参数值落在样本统计值某一区间内的概率。而置信区间是指在某一置信水平下,样本统计值与总体参数值间误差范围。置信区间越大,置信水平越高。 总结:p-value是用来表示假设检验中假设错误(零假设)是否显著,p-value越小越显著,置信度是用来表示总体参数值落在样本统计值某一区间内的概率,置信区间越大,置信度越高,但是对应的准确程度越低。它们的计算方法类似,都跟累积分布函数(即概率分布函数的积分)有关,并且它们都提到了0.05。 参考文献: 1.https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.beta.html 2.https://zh.wikipedia.org/zh-hans/P%E5%80%BC 3.https://mp.weixin.qq.com/s/tmlaB4nwK0EPxaAmsIVScA |
【本文地址】