| Python爬虫 | 您所在的位置:网站首页 › 百度指数日均值什么意思啊 › Python爬虫 |
Python爬虫
|
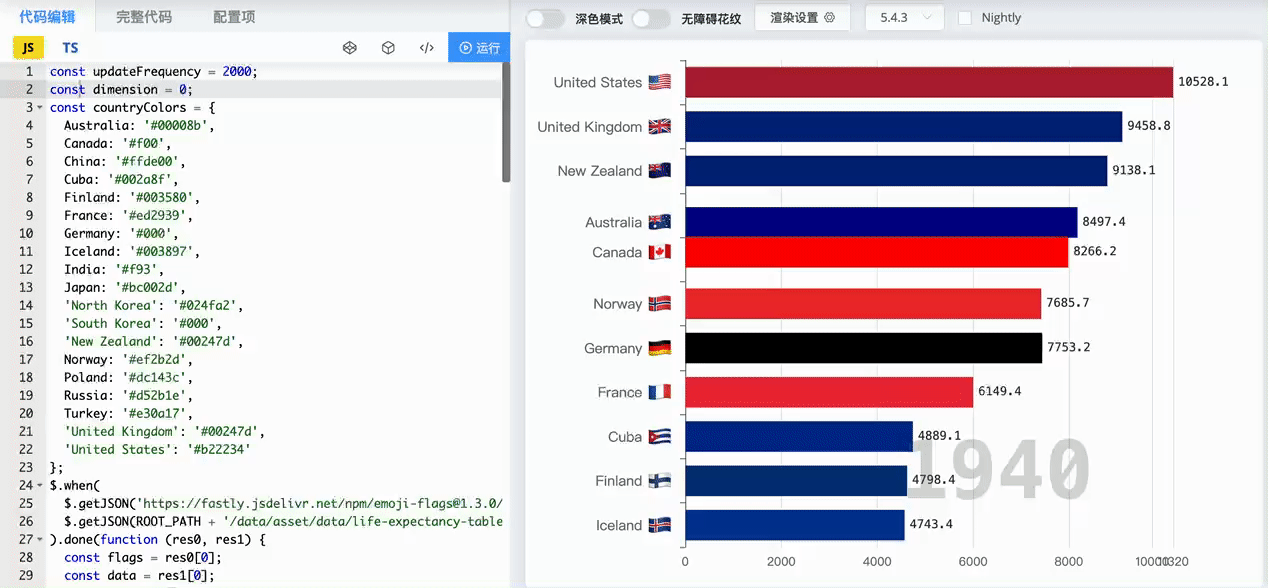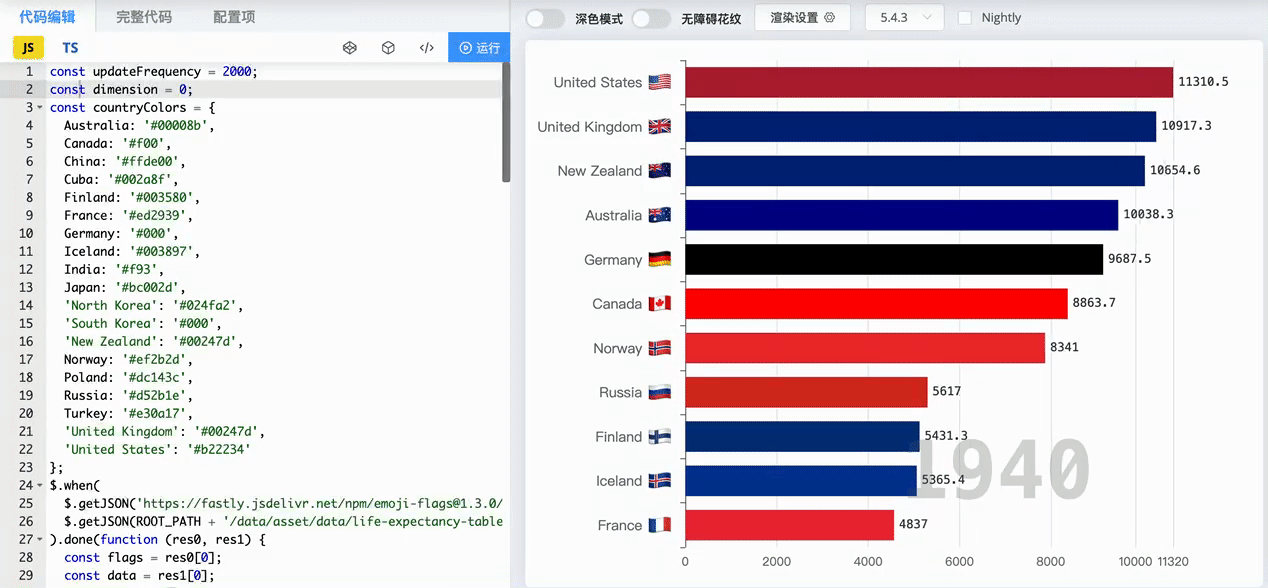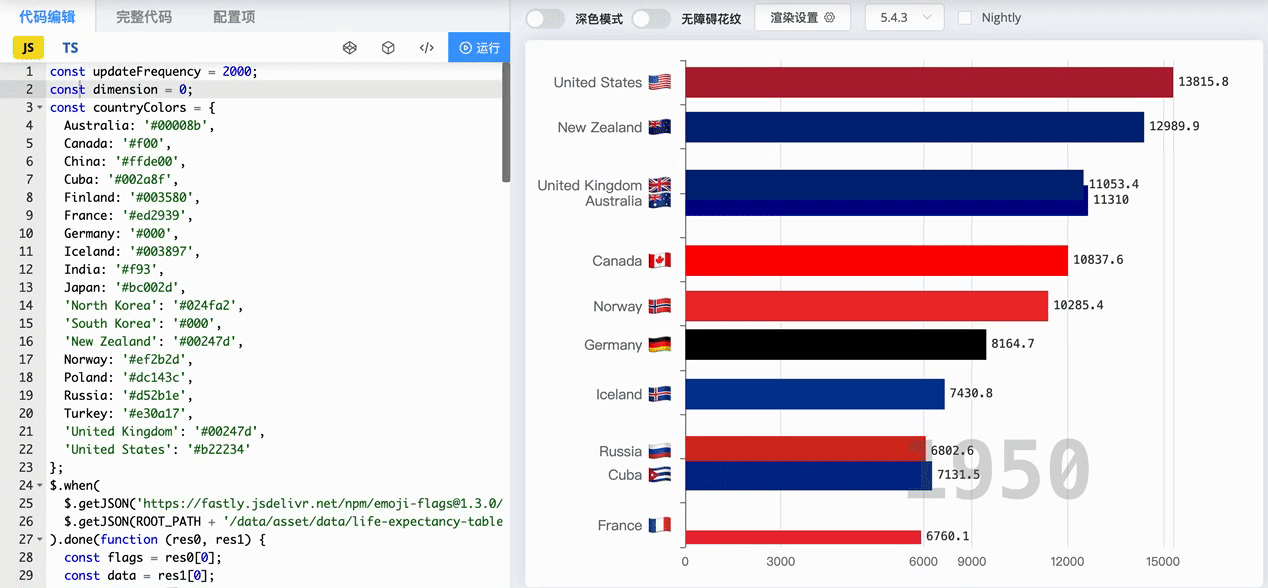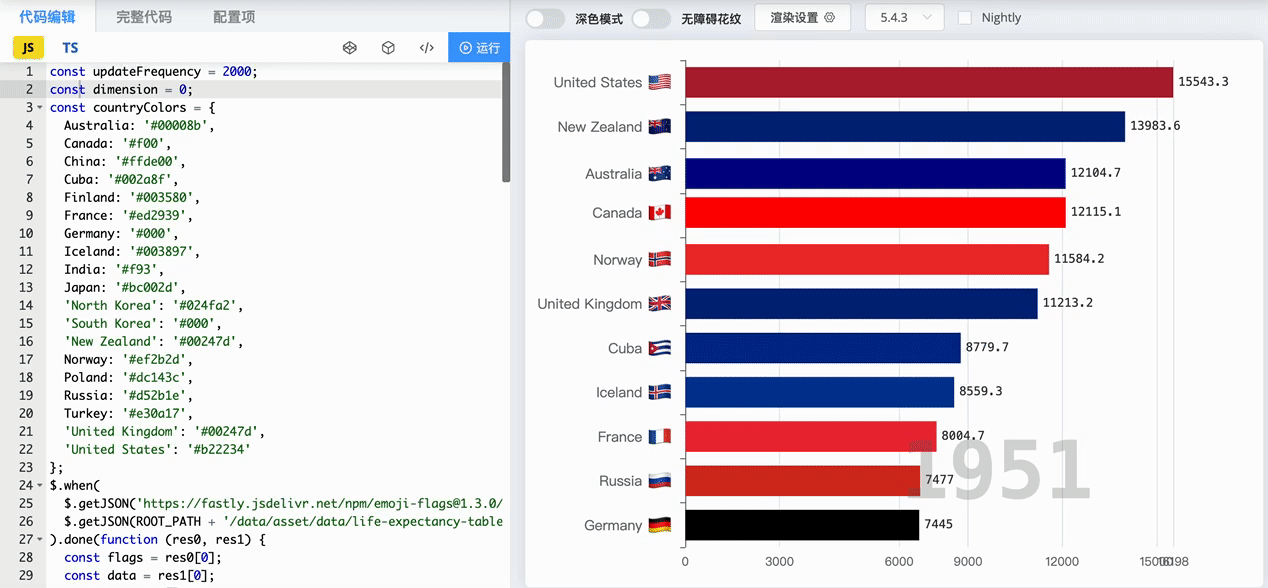
百度指数是由百度提供的一个用于测量特定关键词或搜索词在百度搜索引擎上的搜索量和搜索趋势的工具。它通过分析用户在百度上的搜索行为和搜索量,提供了关键词的搜索指数和相关数据,以反映关键词的热度和受欢迎程度。通过百度指数,用户可以了解到特定关键词在一段时间内的搜索趋势、地域分布以及与其他关键词的对比情况。 不少社会研究分析都用到了百度指数,百度指数提供了大量的搜索行为数据,反映了人们在百度搜索引擎上的兴趣、关注和需求。这些数据可以帮助我们了解社会话题、事件和趋势,从而进行相关的社会科学研究。 你肯定见过像下面这样的动态排序图,那么就可以通过百度指数获取某一日期区间的数据,做出如某时间段内多个品牌热度对比的动态排序图。
那么直接开始正题,我们来到百度指数官网:百度指数
可以看到百度官方也贴心的给出了统计图表,便于观察数据,鼠标光标会显示具体某一天的数据,这说明我们可以获取到具体到天的数据。
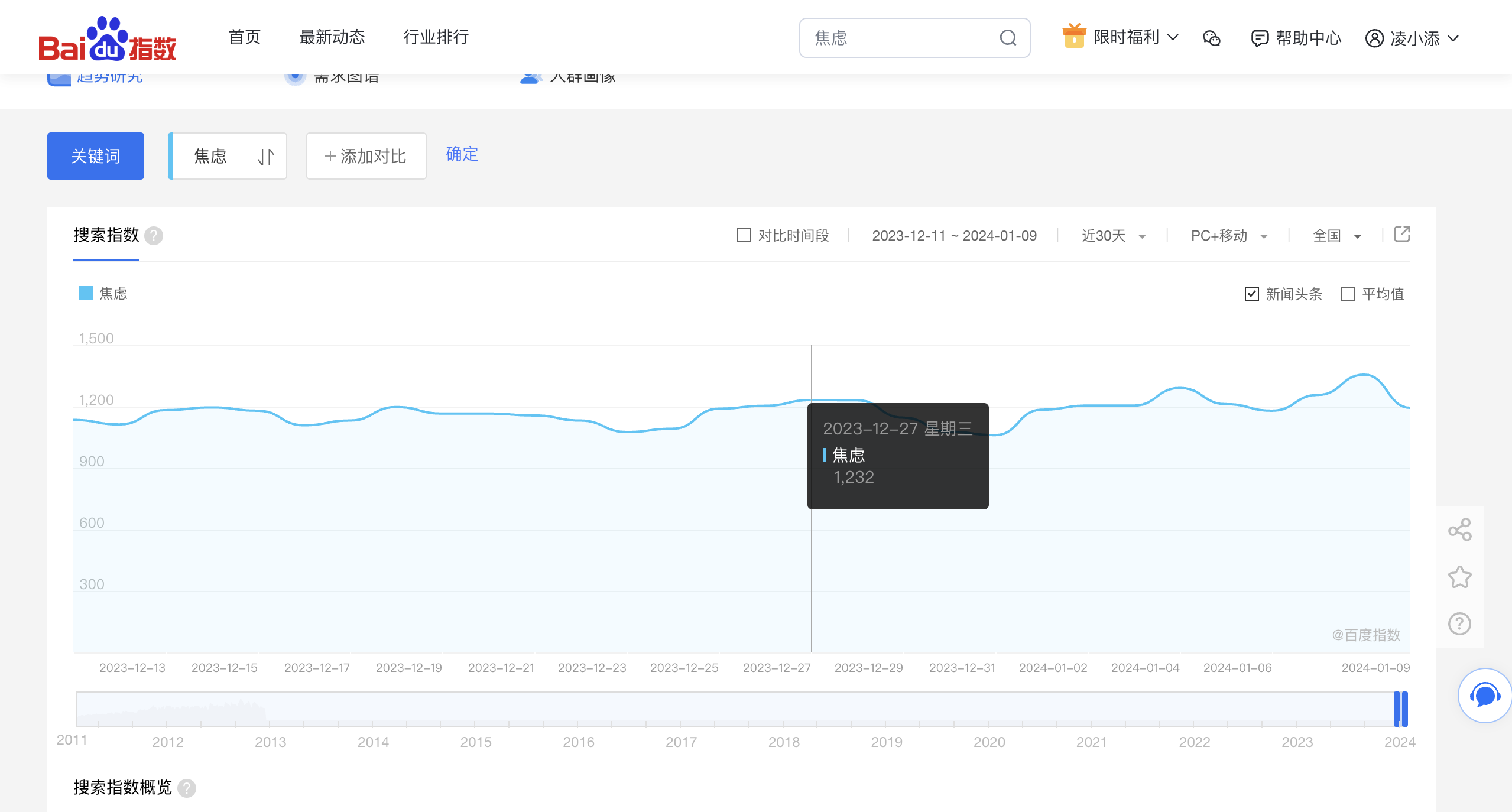
同时我们可以选择多个关键词选择时间区间进行对比,另外还可设定数据地区,用户设备种类等,接下来我们具体分析。 2. 分析思路 2.1. 抓包老规矩,首先按F12打开开发者工具,查看网络请求
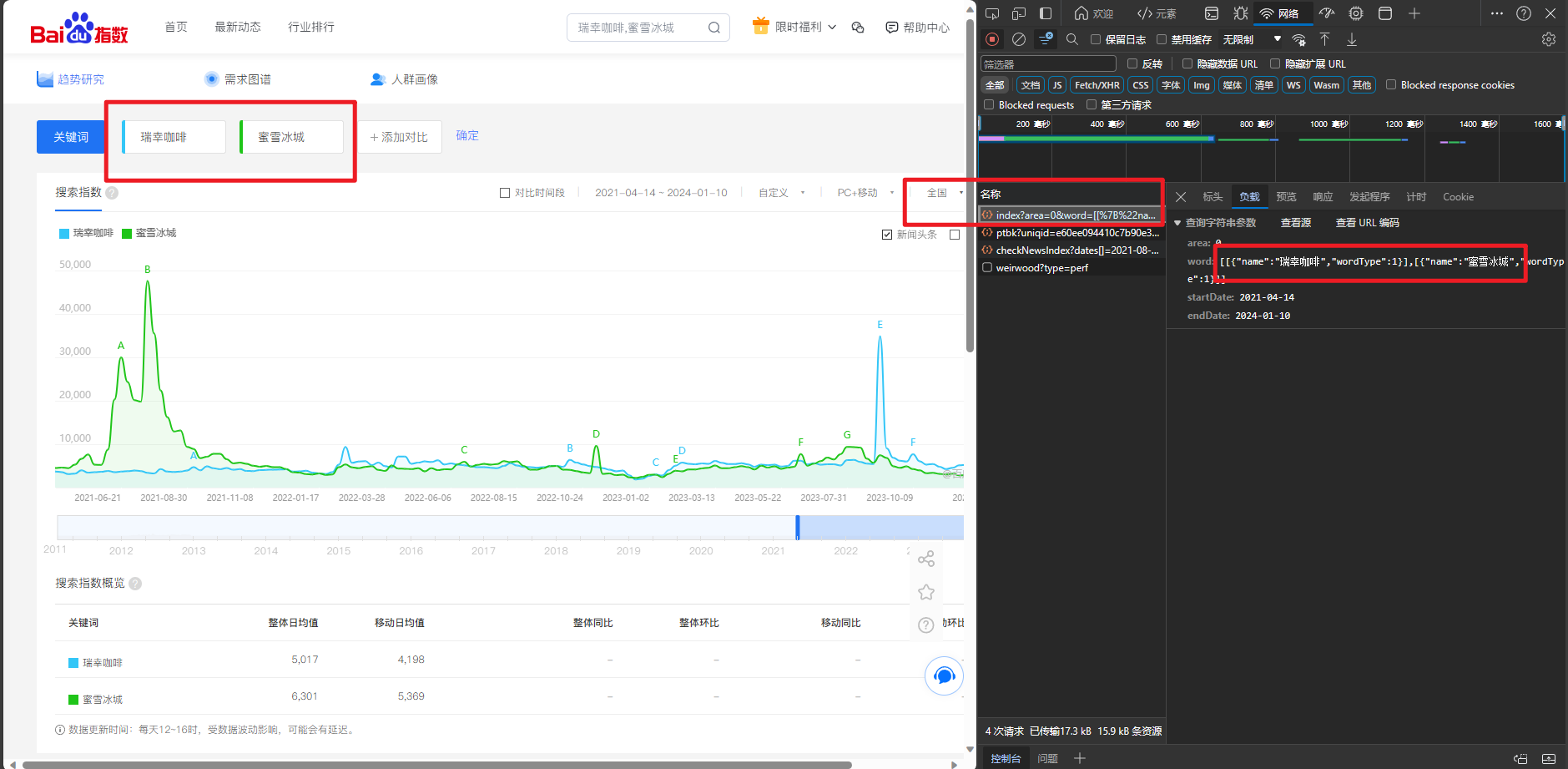
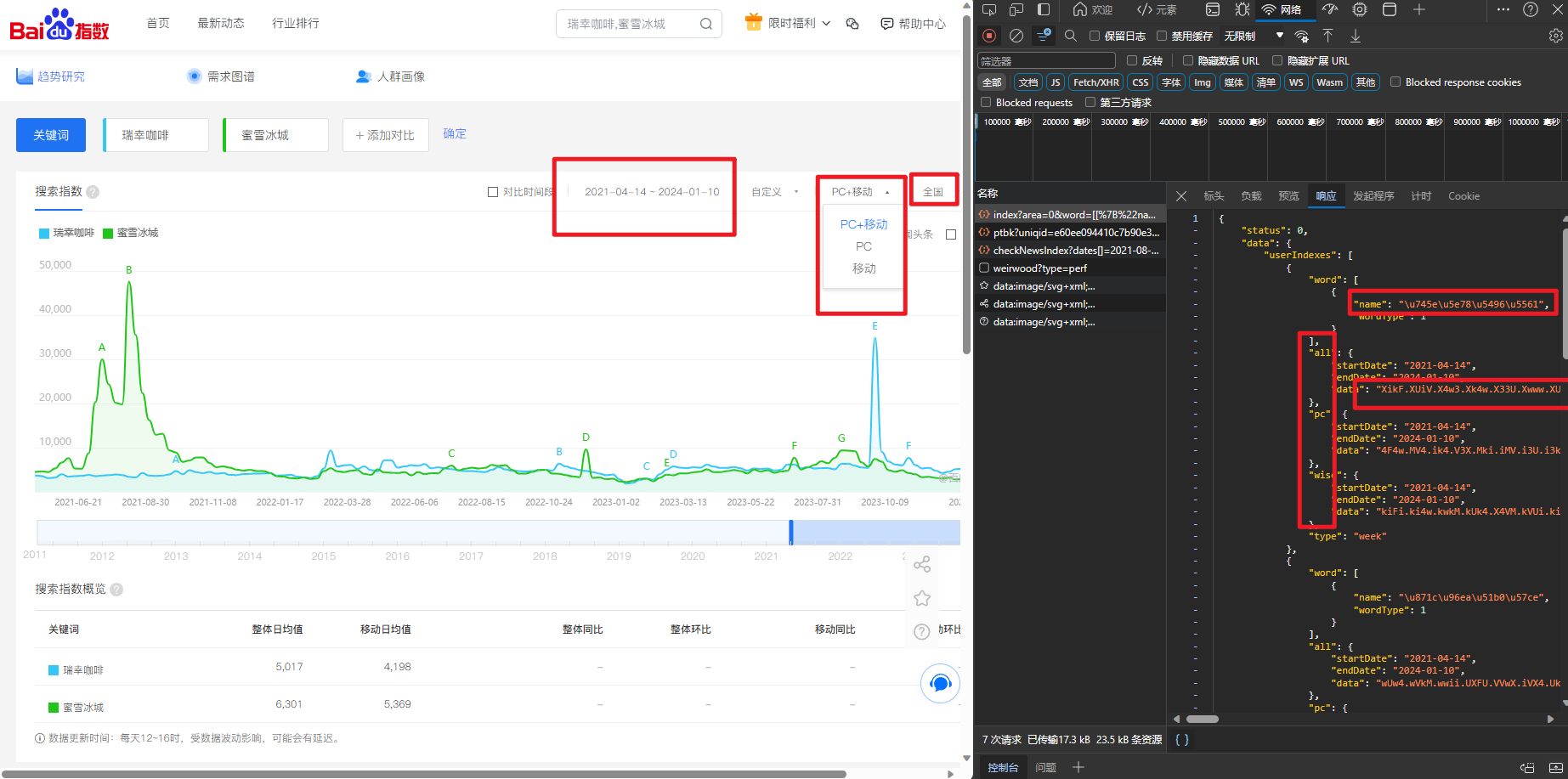
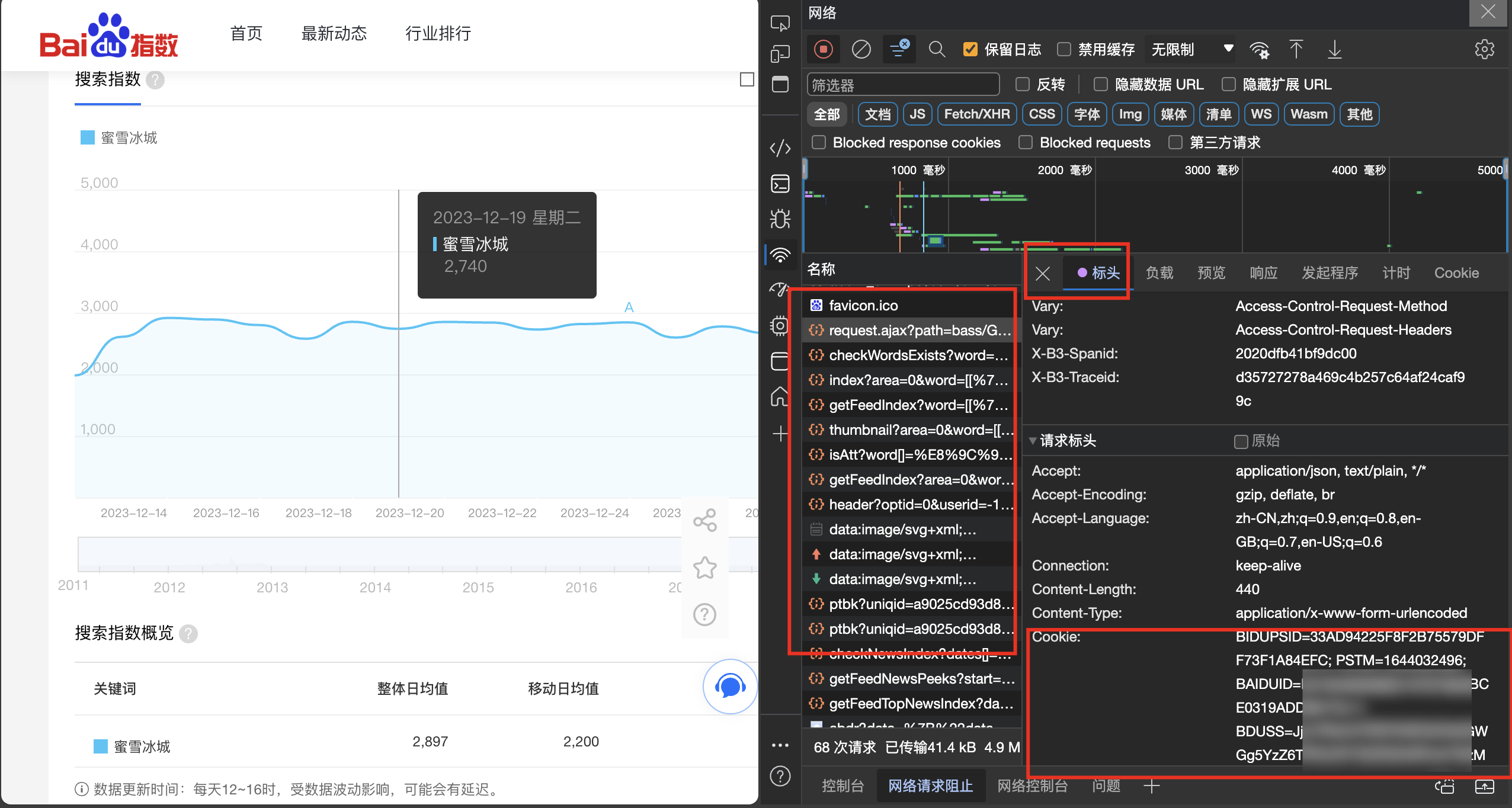
很容易发现,接口地址为:https://index.baidu.com/api/SearchApi/index? 查看请求标题后发现这是一个GET请求,负载数据直接拼串在接口链接后面即可。 接着我们分析响应的数据: "startDate" 和"endDate"对应年份区间; pc wise all对应不同设备的数据; data 也就是我们需要的数据,但是很显然加密了,因此我们后续还需解密。
那么,假设我们得到了这组数据,即一个字典格式的json文件,我们可以将其格式化保存,并读取各个键值对数据。 但问题在于data中的数据:kwwQkkoQwFkQkwoQwFGQwFGQwF-Q很显然是加密的,我们即便获取了这样的数据也无法阅读,但是网页上显示到的数据又是正常显示,这说明网页后端必然存在解密的js代码。 我们回过头来继续观察:
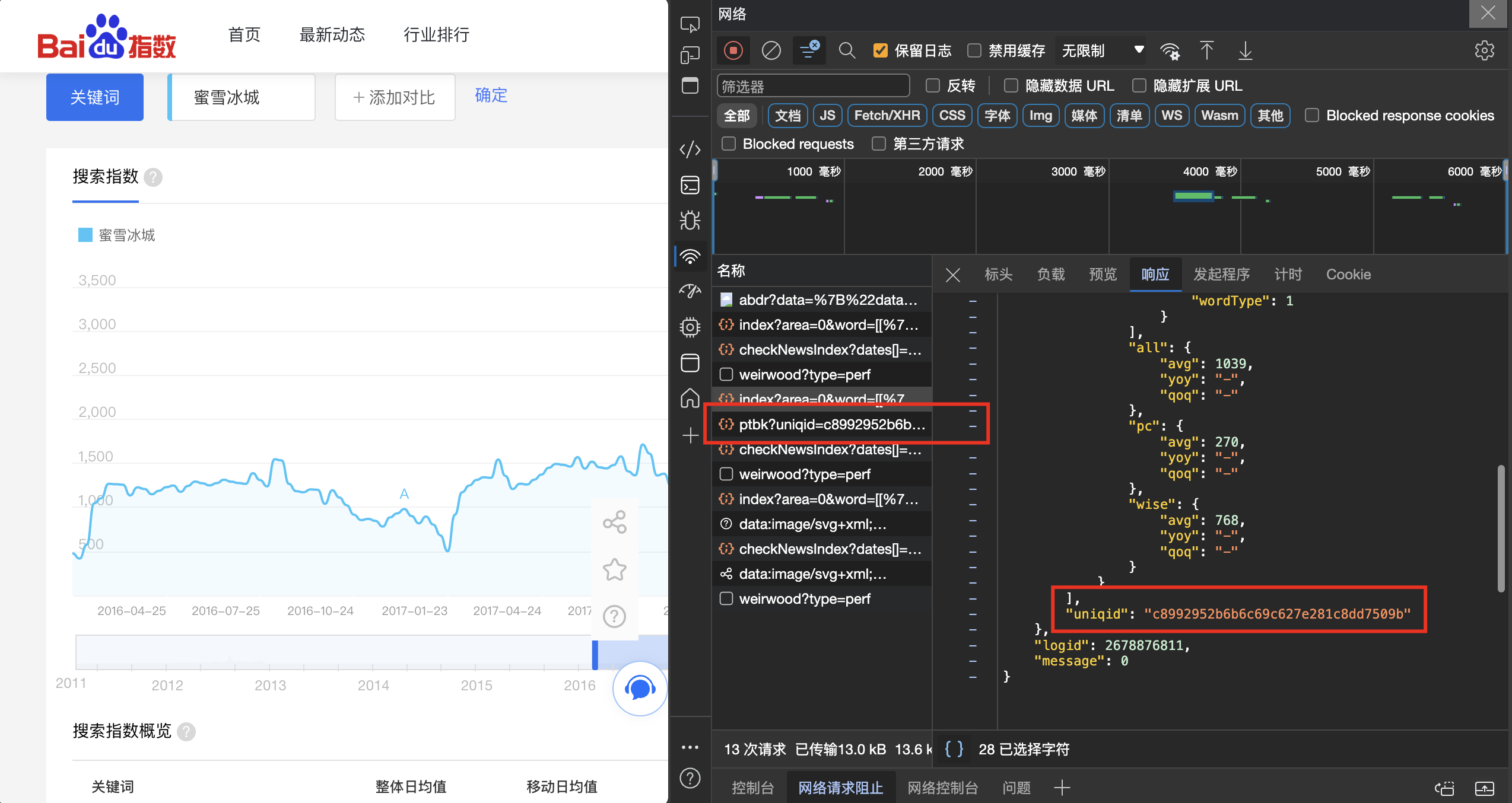
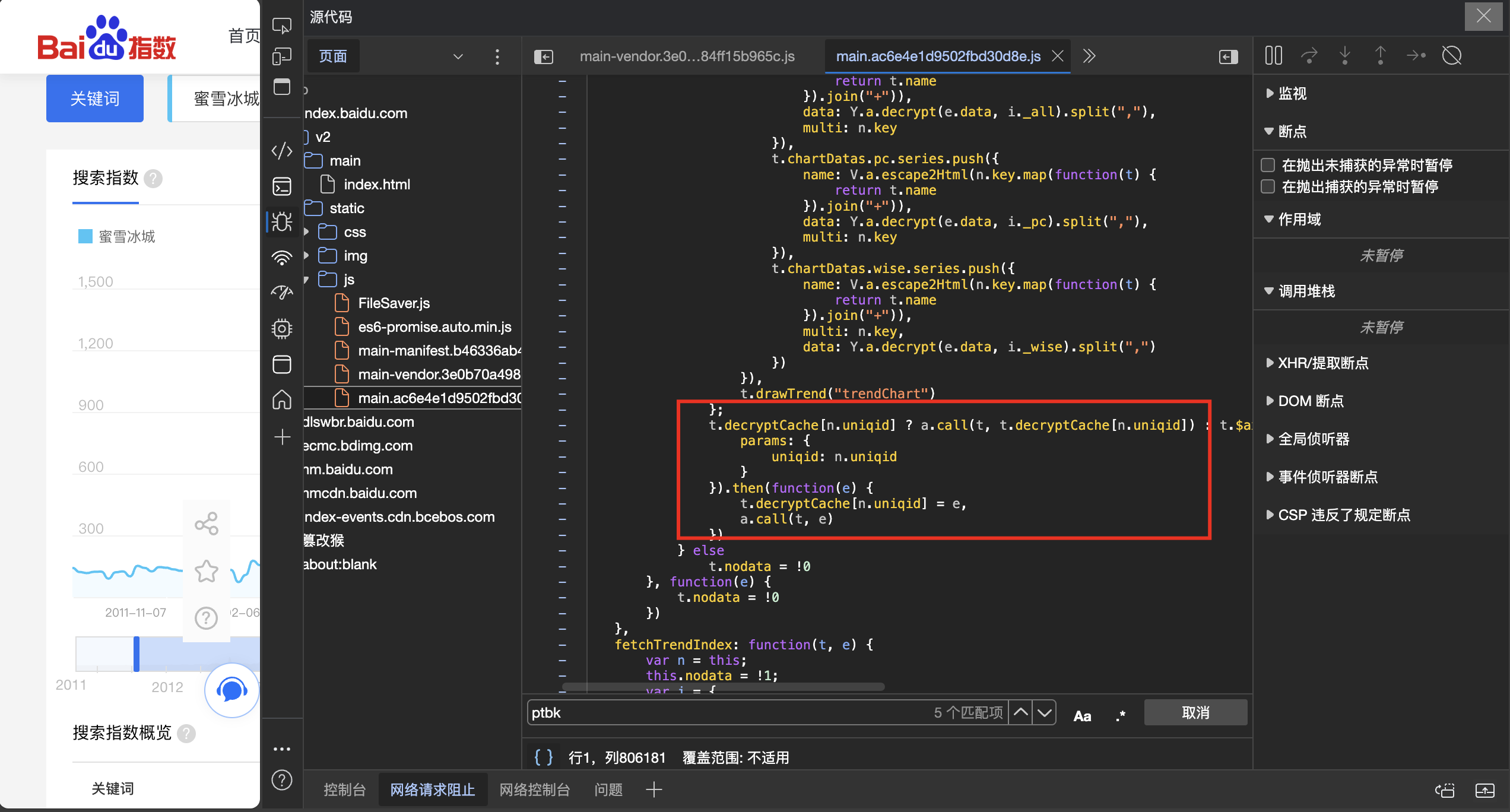
观察上面的结果,我们惊喜的发现,每个json文件中必然包含着一个uniqid这样一个特殊值,而恰巧网页又以这个唯一值为载体发送了一次请求。 这个请求返回了一个键值对,"data":"J,y8vIBmLWlCuw901+3-5%9,8.2746" 我们暂且将其命名为ptbk,这变量名称可能由token,key之类组成,猜测其作用为解码字,密钥之类。 我们紧接着查看这个请求,并在网页JS源代码中搜索,果不其然,发现了相关踪迹:
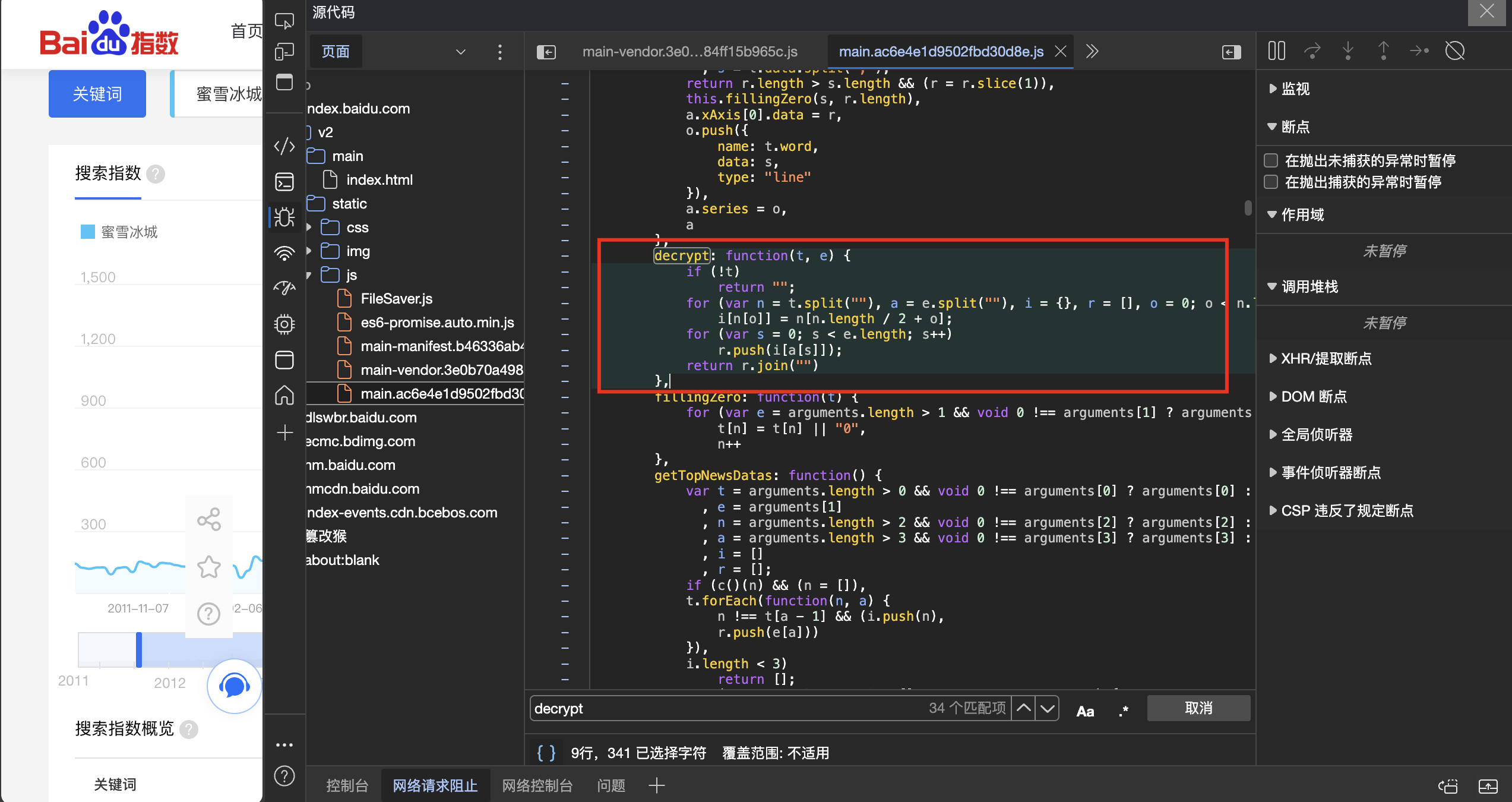
而decrypt就是解密的意思!紧接着我们顺藤摸瓜,搜索decrypt,结果我们就发现了其解密函数。
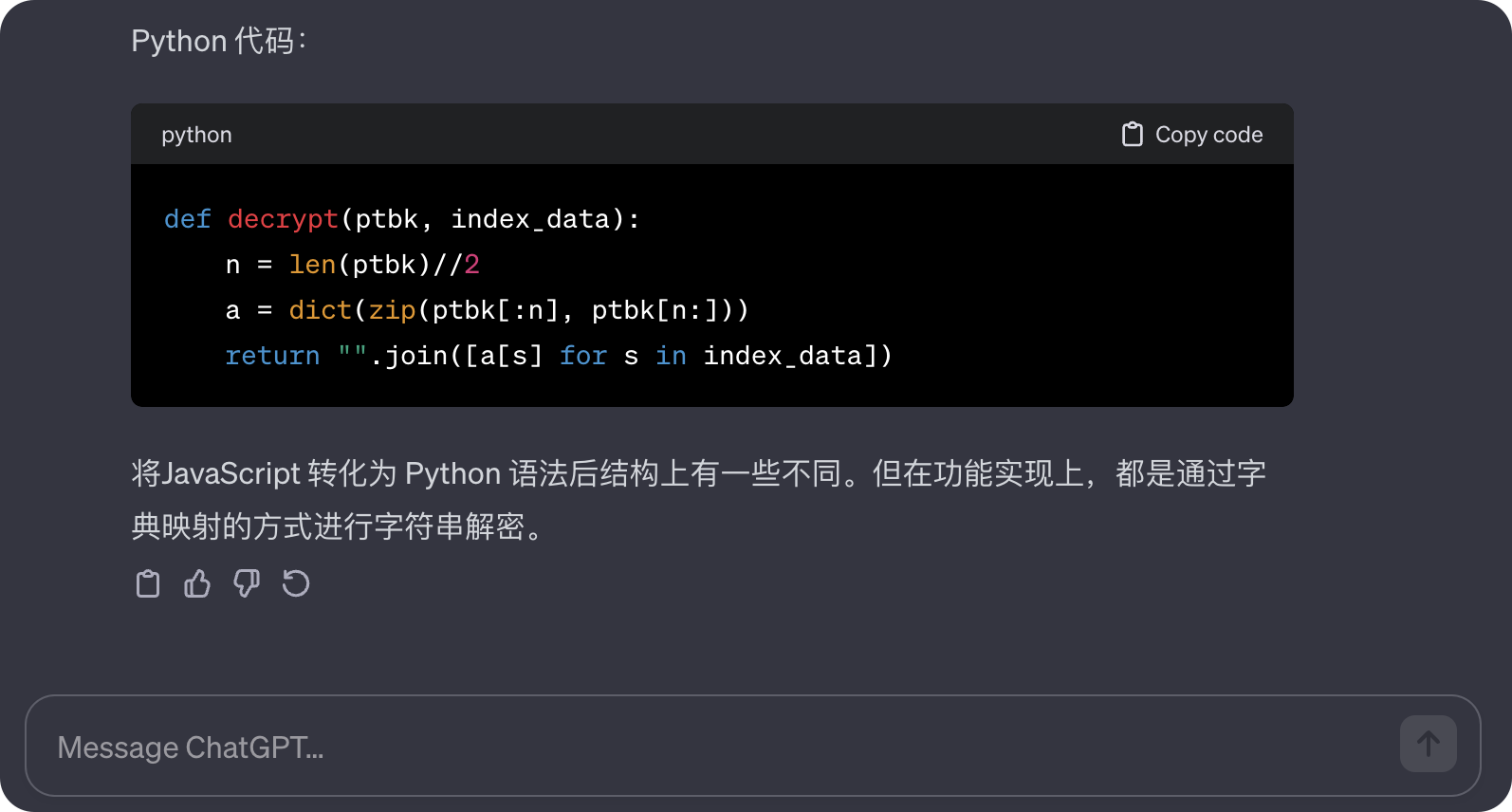
看不懂?没关系,我们有Chatgpt,我们跟它说明原委,让它翻译就好了。 (另外,互联网上也有大佬已经开源了现成的解决方案。)
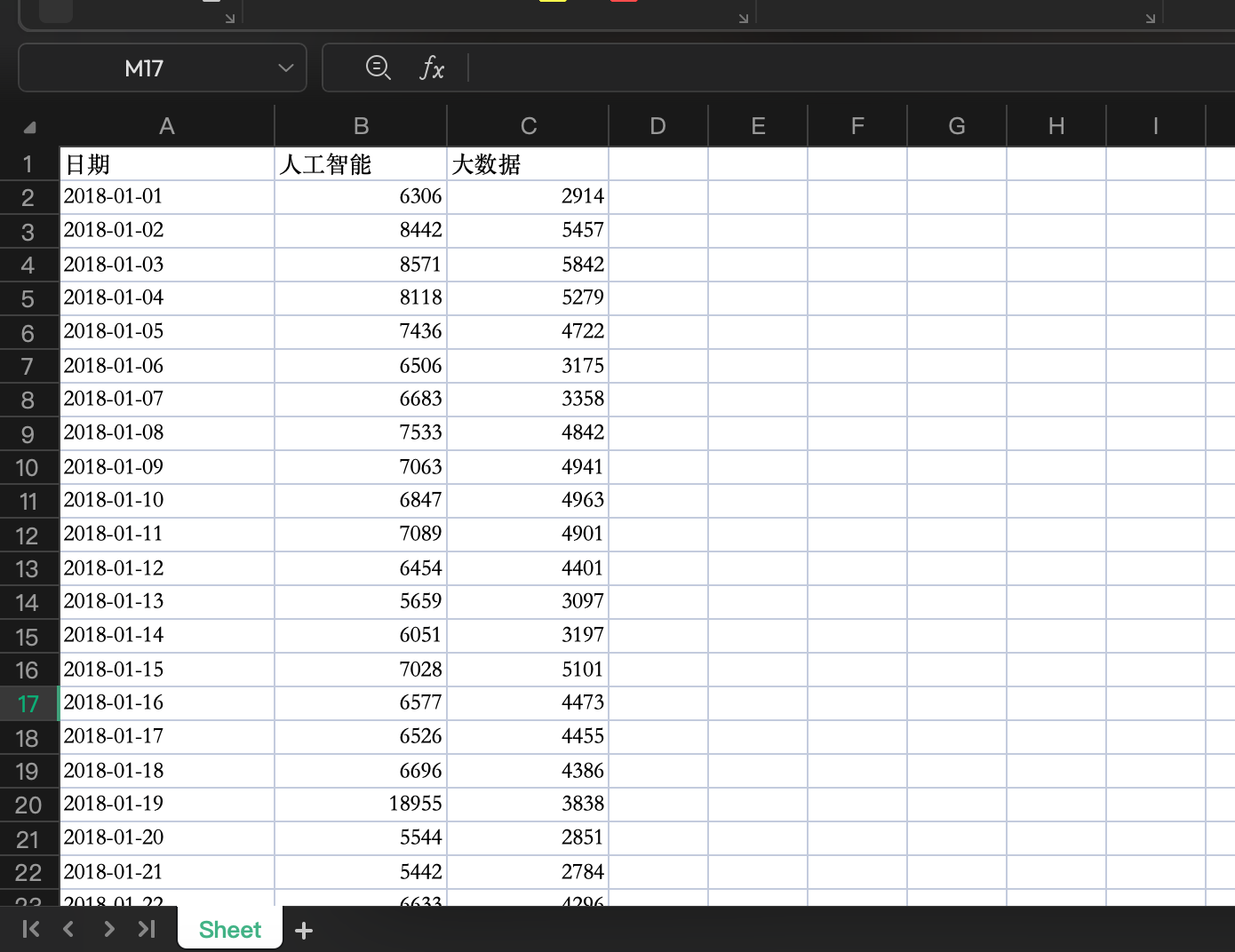
既然数据能够到手,我们接下来的工作就是将数据保存,我们可以将结果保存到json中,用来进行可视化展示处理。也可以存入Excel文件中,首列通过data库输出每天的日期,第二列开始为关键词的数据,如下图所示。
但这里其实有很多问题尚未解决,如: 如果data返回值为空怎么办?如果某些日期中数据缺失,如何对应到正确日期中?遇到润年如何处理?data数据获取有无上限?……这些都是我们需要去解决的细节,细节处理与考虑周全很大程度上都影响了代码质量,最终影响数据准确性。 3. 具体实现 3.1. 数据获取和一般的网站爬虫无异,我们还是使用request库,并配置headers进行伪装。 def get_index_data(keys,year): words = [[{"name": keys, "wordType": 1}]] words = str(words).replace(" ", "").replace("'", "\"") startDate = f"{year}-01-01" endDate = f"{year}-12-31" url = f'http://index.baidu.com/api/SearchApi/index?area=0&word={words}&startDate={startDate}&endDate={endDate}' # 请求头配置 headers = { "Connection": "keep-alive", "Accept": "application/json, text/plain, */*", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Cipher-Text": "1698156005330_1698238860769_ZPrC2QTaXriysBT+5sgXcnbTX3/lW65av4zgu9uR1usPy82bArEg4m9deebXm7/O5g6QWhRxEd9/r/hqHad2WnVFVVWybHPFg3YZUUCKMTIYFeSUIn23C6HdTT1SI8mxsG5mhO4X9nnD6NGI8hF8L5/G+a5cxq+b21PADOpt/XB5eu/pWxNdwfa12krVNuYI1E8uHQ7TFIYjCzLX9MoJzPU6prjkgJtbi3v0X7WGKDJw9hwnd5Op4muW0vWKMuo7pbxUNfEW8wPRmSQjIgW0z5p7GjNpsg98rc3FtHpuhG5JFU0kZ6tHgU8+j6ekZW7+JljdyHUMwEoBOh131bGl+oIHR8vw8Ijtg8UXr0xZqcZbMEagEBzWiiKkEAfibCui59hltAgW5LG8IOtBDqp8RJkbK+IL5GcFkNaXaZfNMpI=", "Referer": "https://index.baidu.com/v2/main/index.html", "Accept-Language": "zh-CN,zh;q=0.9", 'Cookie': Cookie} res = requests.get(url, headers=headers) res_json = res.json()需要注意的是,请求头配置中务必填写自己的Cookie,如果Cookie缺失或错误,直接导致数据获取失败!! 至于如何获取Cookie,下面是一种简单的手动处理方式: 打开百度指数官网并登录随意搜索某一关键词,按F12打开开发者工具,切换到网络模块点击一个请求信息,查看请求头即可看到自己的Cookie
(为了自身账号安全,请务必保管好自己的Cookie,切勿发送到公开场合) 紧接着我们利用软件发送请求,获取json文件以及uniqid解码字。 if res_json["message"] == "bad request": print("抓取关键词:"+keys+" 失败,请检查cookie或者关键词是否存在") else: # 获取特征值 data = res_json['data'] # print(data) uniqid = data["uniqid"] url = f'http://index.baidu.com/Interface/ptbk?uniqid={uniqid}' res = requests.get(url, headers=headers) # 获取解码字 ptbk = res.json()['data'] #创建暂存文件夹 os.makedirs('res', exist_ok=True) filename = f"{keys}_{year}.json" file_path = os.path.join('res', filename) with open(file_path, 'w', encoding='utf-8') as json_file: json.dump(res_json, json_file, ensure_ascii=False, indent=4) return file_path,ptbk 3.2. 格式化数据在获取到data数据和ptbk解码字后,我们即可调用解码函数进行翻译,获取原始数据。 # 解码函数 def decrypt(ptbk, index_data): n = len(ptbk)//2 a = dict(zip(ptbk[:n], ptbk[n:])) return "".join([a[s] for s in index_data])但是在测试过程中我们发现,data值的获取具有上限,如果一次性获取跨年数据,则数据大概率残缺。 关键的一步来了!我们按年份逐次进行多次请求,并将每年的结果拼接成完整的数据列表! 在这一过程中,我们要确保每年的数据数量为365个,润年为366个,若数量缺失则用0从左侧补足。 由此,我们能确保拼接而成的数据列表能与日期一一对应。 def reCode(file_path,ptbk): # 读取暂存文件 with open(file_path, 'r', encoding='utf-8') as file: res = json.load(file) data = res['data'] li = data['userIndexes'][0]['all']['data'] startDate = data['userIndexes'][0]['all']['startDate'] year_str = startDate[:4] # 使用切片取前四个字符,即年份部分 try: # 将年份字符串转换为整数 year = int(year_str) # 根据年份判断是否为闰年 if (year % 4 == 0 and year % 100 != 0) or (year % 400 == 0): year = 366 else: year = 365 except : year =365 if li =='': result = {} name = data['userIndexes'][0]['word'][0]['name'] tep_all = [] while len(tep_all) < year: tep_all.insert(0, 0) result["name"] = name result["data"] = tep_all else: ptbk = ptbk result = {} for userIndexe in data['userIndexes']: name = userIndexe['word'][0]['name'] index_all = userIndexe['all']['data'] try: index_all_data = [int(e) for e in decrypt(ptbk, index_all).split(",")] tmp_all = index_all_data except: tmp_all = [] while len(tmp_all) < year: tmp_all.insert(0, 0) result["name"] = name result["data"] = tmp_all return result注意,由于我们需要获取特征值,上面的代码中,我们创建了res文件夹存放第一次请求的结果,将数据暂存,防止数据丢失。
在经过上面的代码后,我们即可得到一个字典数据:result 其基本格式为:{"name":"关键词","data":[123,123,123,432,453,634]} 3.3. 数据保存最后,我们只需要对数据进行保存,如前所述,我们将其保存到Excel文件中。 为此,我们需要创建Excel表格并进行读写操作。 #创建日期表格 def create_excel(start_year, end_year): workbook = openpyxl.Workbook() sheet = workbook.active # 设置第一行的标题 sheet['A1'] = '日期' # 计算日期范围 start_date = datetime(start_year, 1, 1) end_date = datetime(end_year, 12, 31) # 逐行填充日期 current_date = start_date row = 2 # 从第二行开始 while current_date |


【本文地址】