| 《用户体验度量》读书笔记 | 您所在的位置:网站首页 › 用户体验度量第二版pdf › 《用户体验度量》读书笔记 |
《用户体验度量》读书笔记
|
文章目录
书籍信息引言什么是用户体验什么是用户体验度量用户体验度量的价值适用于每个人的度量方法用户体验度量的新技术十个关于用户体验度量的常见误解
背景知识自变量和因变量数据类型描述性统计比较平均数变量之间的关系非参数检查用图形化的方式呈现数据
规划研究目标用户目标选择正确的度量:10种可用性研究评估方法其他研究细节
绩效度量任务成功任务时间错误效率易学性
基于问题的度量什么是可用性问题如何发现可用性问题严重性评估分析和报告“可用性问题相关的度量”可用性问题发现中的一致性可用性问题发现中的偏差参与者数量
自我报告度量自我报告数据的重要性评分量表任务后评分测试后评分用SUS比较设计在线服务其他类型的自我报告度量
行为和生理度量自发言语表情的观察与编码眼动追踪情感度量紧张和其他生理指标
合并和比较度量单一可用性分数可用性记分卡与目标和专家绩效比较
专题实时动态网站数据卡片分类数据可及性数据投资回报率数据
案例研究净推荐与良好用户体验的价值度量指纹采集的反馈效果Web体验管理系统的再设计使用度量来改善大学招生简章网站利用生物测量技术测量可用性
通向成功的10个关键点
书籍信息
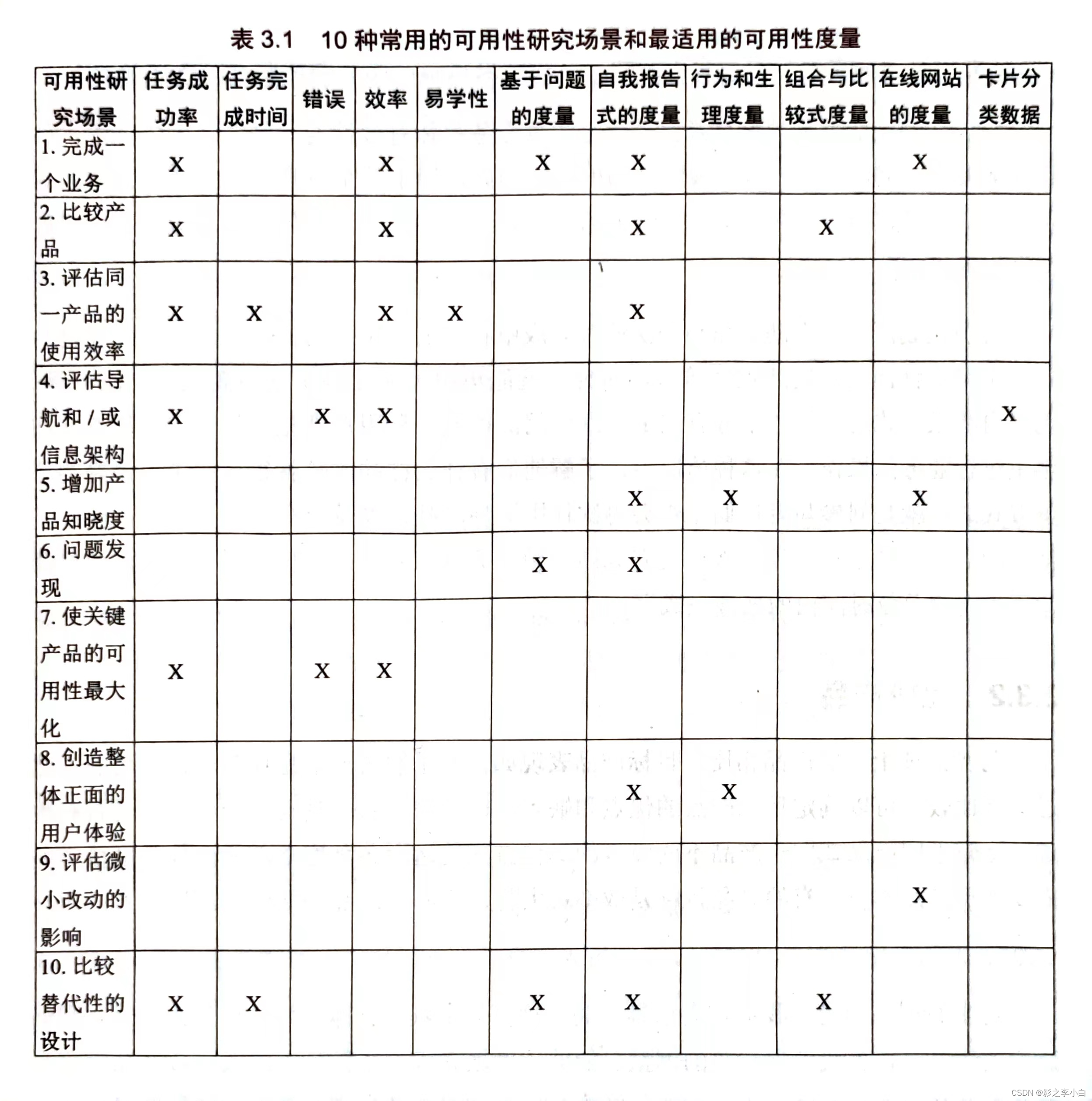
书名:《用户体验度量:收集、分析与呈现》 作者:Tom Tullis, Bill Albert 引言 什么是用户体验 有用户的参与用户与产品、系统或者有界面的任何物品进行交互用户的体验是用户所关注的问题,并且是可观察的或可测量的 什么是用户体验度量用户体验度量可以揭示用户和物件之间的交互,即可揭示出有效性、效率、满意度。 用户体验度量的价值 发现可用性问题。可以说明是否提高了产品的用户体验。计算投资回报率ROI的一个重要组成部分。揭示一些很难或者甚至不可能看出来的问题。 适用于每个人的度量方法收集、分析和呈现用户体验度量的基本方法。 用户体验度量的新技术眼动追踪技术、情感计算技术等。 十个关于用户体验度量的常见误解 度量需要花太多的时间而难以收集用户体验独立要花费太多的钱当集中在细小的改进上时,用户体验度量是没有用的用户体验度量对我们理解原因没有帮助用户体验数据的噪音太多只能相信自己的直觉度量不适用于新产品没有度量适用于我们正在处理的问题度量不被管理层所理解或赞赏用小样本很难收集到可靠的数据 背景知识 自变量和因变量当设计一个可用性研究的时候,研究者必须清楚自己计划操控什么(自变量)和测量什么(因变量)。 数据类型 称名数据:简单无序的群组或类别。如,地域、性别。顺序数据:有序的群组或类别。如,等级、排名。等距数据:没有绝对零点的连续数据。如,温度、日期。比例数据:有绝对零点的连续数据。如,年龄、身高、体重。了解数据对分析结果是至关重要的。 描述性统计常见的描述性统计包括: 集中趋势的测量:平均数、中位数、众数变异性的测试:全距、方差、标准差通常使用99%、95%、90%的置信区间,可以通过误差线来呈现置信区间。 比如,95%的置信区间可用如下公式计算:平均值 ± 1.96 * [ 标准差 / 样本量的平方根 ] 比较平均数比较独立样本平均数的最简单的方法是使用置信区间的重叠情况来判断,其量化结果即:t 检查(Excel的TTEST函数)。 比较同一组参与者2次参与不同产品的体验的平均数时,应使用配对样本进行 t 检查。 比较两个以上的样本时,使用方差分析。 变量之间的关系观察数据可视化后的样子。 非参数检查用于分析称名数据和顺序数据。 比如卡方检查(Excel的CHITEST函数)。 用图形化的方式呈现数据 柱状图或条形图:类别数据折线图:连续数据散点图饼图:数据之和为100%的数据堆积柱形图:数据之和为100%的类别数据 规划 研究目标采用哪种方法: 形成式可用性:在产品研发过程中迭代评估、修改;总结式可用性:产品完成后进行评估。 用户目标 绩效:用户能成功完成一个或一系列任务的程度。满意度:与用户接触和使用产品时的所说所想有关。绩效和满意度并非总是相互关联。 选择正确的度量:10种可用性研究
非引导式的测试工具: 基于定量的工具 全套服务:如 WebEffective、Imperium、Webnographer自助式服务:如 Loop11、UserZoom、UTE卡片分类 / 信息架构工具:如 OptimaSort、TressJac、WebSort调查工具:如 Qualtrics、SurveyGizmo、SurveyMonkey点击 / 鼠标工具:如 Chalkmark、Usabilla、ClickTale、FiveSecondTest 基于定性的工具 视频工具:如 UserTesting.com、Userlytics、OpenHallway报告型工具专家走查工具:如 Concept Feedback 其他研究细节 预算和时间表参与者:招募标准、样本量等数据收集数据整理:筛选数据、创建新变量、检验应答、检查一致性、数据转换等 绩效度量 任务成功任务成功关注用户是否能使用产品完成任务。 二分式成功:通过/不通过;可以计算置信区间成功等级:可以基于用户的体验、完成任务的方式等来评定。 任务时间任务时间关注用户能多快地使用产品完成任务。 分析手段: 全距阈值分布和异常值 错误错误关注用户完成任务的操作等的有效性。 分析手段: 错误频率平均错误数阈值严重等级的分布/频率 效率效率关注用户完成任务所需的努力程度(包括认知上和身体上的)的大小。 分析手段: 操作动作数量迷失度: L = ( 1 − N S ) 2 + ( 1 − R N ) 2 L=\sqrt{(1-\frac{N}{S})^2+(1-\frac{R}{N})^2} L=(1−SN)2+(1−NR)2 ,其中L为迷失度,N为操作任务时所访问的去重后的页面数目,S为操作任务时访问的总的页面数目,R为完成任务时必须访问的最小的去重后的页面数目。一个最佳的迷失度应为0。任务完成率与每个任务平均时间的比值 易学性易学性关注任一绩效度量如何随时间推移而变化。 需要多次收集易学性数据,每次收集被看做是一项施测(trial)。 分析手段:通过多次施测来检验一个任务上特定的绩效度量(如任务时间、操作步骤数或错误数)的变化情况。 基于问题的度量 什么是可用性问题可用性问题关注的是用户使用产品过程中的行为。 如何发现可用性问题 面对面研究:出声思维法,用户在操作任务的过程中将他们的想法即时表达出来。自动化研究:如收集完成状态、时间、易用性评分和文本评论。 严重性评估 基于用户体验的严重性评估综合多种因素的严重性评估:用户体验影响、遇到问题的用户数量其他因素:使用频率、对商业价值的影响、持续性 分析和报告“可用性问题相关的度量” 独特问题的频次具体问题的参与者百分比每个任务或类别中出现问题的频次每个参与者遇到的问题数量参与者人次问题归类按任务区分问题 可用性问题发现中的一致性如何确保一致性和避免偏见方面尚没有好的办法,人们难以在何为可用性问题或者这个问题有多严重等方面达成共识。 可用性问题发现中的偏差偏差无法消除,可以归为以下几大类: 参与者任务方法产品环境测试主持人预期 参与者数量一般认为,通过前5个参与者的测试就会发现大多数或者80%的可用性问题。一般建议保持5-10个参与者。 自我报告度量 自我报告数据的重要性自我报告数据可以提供有关用户对系统的认知及他们与系统交互方面的重要信息。 评分量表 Likert 量表:陈述一个观点,回答者要给出自己同意该语句的程度或水平。一般使用5点同意量表:强烈反对、反对、既不同意,也不反对、同意、强烈同意。也有些会使用7点标度。语义差异量表:在一系列评分条目的两端呈现一对相反或相对的形容词,比如弱/强、业余/专业、容易/困难。5点或7点标度是最常用的。分析手段: 平均值选项的实际频率分布查看首项或前2项的比例 任务后评分 易用性:容易ooooo困难情景后问卷(ASQ):容易程度、所用时间、辅助性信息,对这3个维度感到满意的Likert量表。期望测量:任务开始前对期望的难度评分,任务完成后对实际的难度评分。 测试后评分 合并单个任务的评分:平均值系统可用性量表(SUS):由John Brooke在1986年编制。对2个维度、10个选项进行评价。满分为100分的话,根据经验,结果70为可接受。计算机系统可用性问卷(CSUQ):由Jim Lewis在1995年编制。对4个维度、19个选项进行评价。用户界面满意度问卷(QUIS):由Chin、Diehl、Norman在1988年编制。对27个选项进行评价。有效性、满意度和易用性的问卷:由Amie Lund在2001年编制。对30个选项进行评价。产品反应卡:由Joey Benedek、Trish Miner在2002年编制。提供了118张词卡,让用户挑选出可以描述系统的词卡,然后再从中挑选出前5张卡并解释原因。净推荐值(NPS):由Fred Reichheld在2003年编制。它用来衡量顾客忠诚度,只使用一个问题:“你有多大的可能性把你的公司(产品、网站等)推荐给你的朋友或同事?”,并提供一个标度从0分(绝无可能)到10分(极有可能)的选项。根据得分,0-6分为批评者,7-8分为被动者,9-10分为推荐者。NPS的值则为推荐者的百分比减去批评者的百分比(忽略被动者),范围在-100到+100。 用SUS比较设计标准问卷SUS已被证明是相当有效且灵活的,及时只有8-10人的参与者时也是如此。 在许多针对具有相似任务的不同设计(比如Win XP和Win Me)而进行的可用性研究中,SUS被当做一种比较方法来使用。即针对同样的参与者,比较2种或多种不同设计的SUS分数谁更高些。 在线服务在线服务可以把网站评价结果与他们参考数据库中的大量网站进行比较,并呈现比较后的结果。 网站分析和测量问卷(WAMMI):HFRG研发。对20个选项进行评价。美国客户满意度指数(ACSI):密歇根大学的Stephen M.Ross商学院研制。对14个选项进行评价。OpinionLab:提供用户对网页层面的反馈。 其他类型的自我报告度量 评估特定的属性:比如视觉吸引力、感知效率、愉悦性。具体元素的评估:比如在线帮助、首页、搜索。开放式问题知晓度和理解程度:提问是否记得使用过程中的一些内容。 行为和生理度量 自发言语表情的观察与编码自发的言语表情可以为理解参与者使用产品时的情绪和心理状态提供很有价值的信息。 言语表情最有价值的度量方式是正面评价和负面评价的比值。 眼动追踪眼动数据可视化: 单个参与者可以使用注视路径图进行可视化展现。热区图是最常见的将多位参与者的眼动数据进行可视化展现的方式。我们所关注的多个页面的特定区域被称为兴趣区,它的相关度量指标: 停留时间注视点数量注视时间:所有注视点的平均持续时长浏览顺序首次注视所需要的时间重访次数命中率:参与者比例 情感度量 Affectiva公司和Q传感器:戴在手腕上,可以测量皮肤电导。皮肤电测试唤醒程度。蓝色泡沫实验室和Emovision:摄像头,对面部表情进行分析来判断情绪状态。面部表情分类后可以与六种基本情绪进行关联。Seren公司和Emotlv:脑电扫描设备,测量脑电波。脑电波活动与特定情感反应相关。 紧张和其他生理指标 心率变异性皮肤电尚在研究实验的新技术:压力鼠标和姿势分析座椅 合并和比较度量 单一可用性分数 将每个度量数据与预定目标进行比较,然后根据能够达到一组综合目标的参与者百分比,呈现一个单一的度量。合并具有不同单位的分数,可以将每个分数转换为百分比,然后求其平均数。转换为百分比时关键是确定最小和最大的值,分别映射为0%和100%。使用 z 分数将不同单位的分数进行转换并合并数据。 z = ( x − μ ) / δ z=(x-μ)/δ z=(x−μ)/δ,z 分数表示特定数值在距离正态分布的平均值上下多少个单位的位置,可以通过Excel的STANDARDIZE函数计算。使用单一可用性度量(SUM),是Jeff Sauro、Erika Kindlund在2005年开发的一种将多个可用性度量合并为单一可用性分数的量化模型,他们使用的输入是:任务完成情况、任务时间、每个任务的错误数和任务后的满意度评分。 可用性记分卡合并不同的度量以得到总体可用性得分的另一种备选方法是以图形的形式将度量结果呈现在一个概要性图表上,这种类型的图表被称为可用性记分卡。 图标的形式包括:条形图和折线图组合、雷达图,任务层面可以使用Harvey球表示各维度可用性度量。 Harvey球: 优秀:90%-100%,实心圆很好:80%-89%,3/4实心圆好:70%-79%,半实心圆一般:60-69%,1/4实心圆差:0%-59%,空心圆 与目标和专家绩效比较总结可用性数据时,可能有外部标准可用于比较的参照点,一般是预设的目标和专家级的(或最优的)绩效。 预设的目标的维度可以参考SUM设置的4个维度:任务完成、时间、准确度和满意度。专家绩效则尤其适用于时间数据。 专题 实时动态网站数据最受欢迎的免费分析服务之一:谷歌分析。 点击率弃用率:在由一系列网页构成的操作流程中中途退出或放弃的比率一个好的A/B测试: 用户应该被随机分配;测试一些小的变化,尤其是一开始的时候;显著性检验需要通过统计来完成;快速迭代,让好的版本尽早全量;相信数据,并去发现和理解令人吃惊的数据的背后的原因; 卡片分类数据一般建议参与用户数量不少于15个比较合适,因为15个样本量得出的分类结果与全部用户的分类结果之间的相关系数达到0.90。 开放式卡片分类中,不指定组别的信息,而是靠用户自己去自定义组别并归类卡片;封闭式卡片分类中,会已经指定组别名称,用户仅作卡片的归类。 封闭式卡片分类不是很常用。一般是在一个开放式分类后紧跟着做一个或多个封闭式分类,并在封闭式分类中使用前面的开放式分类的得到的一个或多个组别结果,从而对这些组别结果是否合理进行验证。 开放式卡片分类数据的分析: 根据每个用户的分类,生成该用户的距离矩阵:矩阵为横列和纵列都是每个卡片,矩阵的每个格表示2个卡片的距离,如果用户将某对卡片放在一起,则其距离记为0,否则记为1。生成所有用户的总体距离矩阵:直接将每个用户的距离矩阵的对应格的值进行加和。使用层级聚类分析,或者多维标度法。 层级聚类分析:目的是建立一个叶子在左边,根在右边的树状图,每个叶子就是一个卡片,最相似的卡片会被放在相近的枝节上,先结合(交汇)在一起的卡片要比后结合在一起的卡片的相似度更高。然后通过对树状图进行垂直“切分”来划分组别。多维标度法(MDS):画出一张地图标记出所有的卡片,在这张地图上所有的配对卡片之间的距离尽可能地接近原始距离矩阵中的距离。然后通过直观的位置上的聚群来划分出组别。封闭式卡片分类数据的分析: 根据所有用户的分类,计算每个卡片被列入每个组的比例,形成一个横列是组别、纵列是卡片、格里是比例值的矩阵。在最右侧添加一个纵列,记录每行的最大比例,即:该行卡片被分到每个组的比例的最大值。统计出最右侧纵列的平均值,使用该值来衡量封闭式卡片分类中使用的一系列组名是否有效,其值越大则越有效。 多次封闭式卡片分类中,分类数量相同时,可以直接使用上步的平均值比较,来比较出优劣。多次封闭式卡片分类中,分类数量不同时,在上步添加一个纵列,记录每行的第2大比例,再添加一个纵列,记录最大比例减去第2大比例的差值。然后对差值纵列求平均值,并使用该平均值进行比较。封闭式卡片分类数据的分析还有一种常用的方法是树测试:将建议的分类使用可交互的形式表现出来,一般是菜单的方式。指定一个任务(寻找某个选项),而用户可以通过逐级选择子菜单,直至寻找到该选项。在这个过程中统计出:任务成功数据、直线完成率(没有再返回过父菜单)、时间,来综合衡量分类的有效性。 树测试工具举例:C-Inspector、Optimal Workshop’s Treejack、PlainFrame、UserZoom Tree Testing。 此外,封闭式卡片分类数据也可以使用层级聚类法、多维标度分析法进行分析,方法同前,这样可以得到分类的直观信息。 可及性数据可及性通常指残障人士如何有效地使用某一产品或功能。 得到最广泛认可的网站可及性指南是W3C的网页内容可及性指南(WCAG)第2版: 可感受性 对非文本内容提供文本形式的可替代内容对多媒体内容提供标题或其他形式的说明内容创建内容时要以多种方式呈现,包括一些辅助技术,且不会失去原意要让用户对内容的听读更简单 可操作性 通过一个键盘就能操作所有的功能给用户充足的时间来阅读和使用内容不要使用会引起癫痫的内容帮助用户定位和寻求内容 可理解性 文本要可读和可理解内容要以可预期的形式来展现和操作帮助用户避免和修正错误 鲁棒性 与当前和未来的用户工具实现最大程度上的兼容在对一个网站是否满足了这些标准进行量化分析时,有一种方法是评估网站上有多少页面没有满足这些指南中的某条或多条建议。 检测可及性的自动化工具有:Cynthia Says、Accessibility Valet Demonstrator、WebAIM’s WAVE tool、University of Toronto Web Accessibility Checker、TAW Web Accessibility Test。 投资回报率数据有两类主要的ROI: 内部ROI 生产率的提升用户错误的降低培训成本的降低在设计生命周期的早期做改进所节省的成本 外部ROI 销售量的增长客户支持成本的降低在设计生命周期的早期做改进所节省的成本培训成本的降低(如果培训是由公司来提供的)计算ROI虽然很有挑战性,但一般是可行的。一般需要将任务完成率的提升或总体满意度的提升等可用性指标换算成电话支持量的降低、销量的增加或客户忠诚度的提高等指标,并估算金额。 案例研究 净推荐与良好用户体验的价值 度量指纹采集的反馈效果 Web体验管理系统的再设计 使用度量来改善大学招生简章网站 利用生物测量技术测量可用性 通向成功的10个关键点 让数据活起来:可视化主动去度量:没有被直接要求时就要主动行动度量比想的便宜:要善用工具早计划:计划开始于收集度量之前给产品确定基线:用户体验度量是相对的挖掘数据:进行探索性统计分析讲商业语言:只使用管理层可以理解和认同的术语及行话,更重要的是采用他们的观点呈现置信程度:在结果中标示置信程度,将有助于做出明智的决策和提高可信度不要误用度量:在不需要度量的地方使用、一次呈现太多数据、一次测量太多、过于依赖某个度量简化报告 :需要符合汇报对象的目标,简洁和直接。 |
【本文地址】