| spss中的aic值计算 | 您所在的位置:网站首页 › 用excel计算残差平方和 › spss中的aic值计算 |
spss中的aic值计算
|
转载自:标点符 链接:最优模型选择准则:AIC和BIC - 标点符 作者:钱魏Way 很多参数估计问题均采用似然函数作为目标函数,当训练数据足够多时,可以不断提高模型精度,但是以提高模型复杂度为代价的,同时带来一个机器学习中非常普遍的问题——过拟合。所以,模型选择问题在模型复杂度与模型对数据集描述能力(即似然函数)之间寻求最佳平衡。 人们提出许多信息准则,通过加入模型复杂度的惩罚项来避免过拟合问题, 信息准则 = 复杂度惩罚 + 精度惩罚,值越小越好。 复杂度惩罚:对应“参数数量”、“训练数据量”,数值变大表明模型复杂度增加,容易过拟合 精度惩罚:对应“负log-似然函数”,数值变大表明似然函数降低,模型对数据集的描述能力下降1、实现参数的稀疏有什么好处? 一个好处是可以简化模型、避免过拟合。因为一个模型中真正重要的参数可能并不多,如果考虑所有的参数作用,会引发过拟合。并且参数少了模型的解释能力会变强。 2、参数值越小代表模型越简单吗? 是。越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反应了在这个区间的导数很大,而只有较大的参数值才能产生较大的导数。因此 复杂的模型,其参数值会比较大。 此处我们介绍一下常用的两个模型选择方法——赤池信息准则(Akaike Information Criterion,AIC)和贝叶斯信息准则(Bayesian Information Criterion,BIC)。 目录 AIC BIC AIC和BIC该如何选择? AIC/BIC实战:Lasso模型选择 相关文章: AIC赤池信息量准则(英语:Akaike information criterion,简称AIC)是评估统计模型的复杂度和衡量统计模型“拟合”资料之优良性(Goodness of fit)的一种标准,是由日本统计学家赤池弘次创立和发展的。赤池信息量准则建立在信息熵的概念基础上。 在一般的情况下,AIC可以表示为: AIC=2k−2ln(L) 其中: k是参数的数量 L是似然函数假设条件是模型的误差服从独立正态分布。让n为观察数,RSS为残差平方和,那么AIC变为: AIC=2k+nln(RSS/n) 增加自由参数的数目提高了拟合的优良性,AIC鼓励数据拟合的优良性但尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个。赤池信息量准则的方法是寻找可以最好地解释数据但包含最少自由参数的模型。 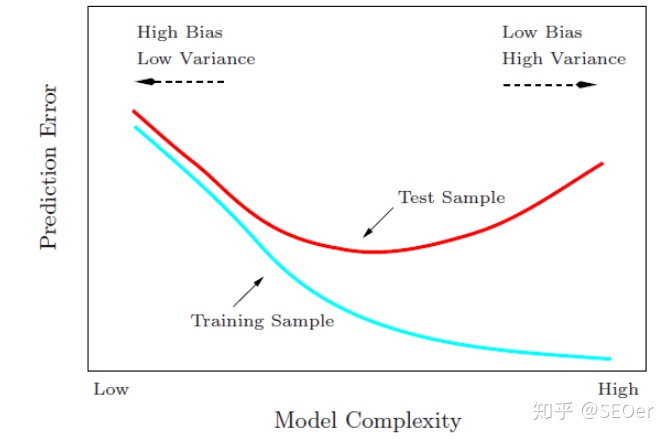
当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。一 |
【本文地址】