| 宏基因组Bin及后续分析的具体步骤(十分详细,手把手教会) | 您所在的位置:网站首页 › 生草图是什么意思 › 宏基因组Bin及后续分析的具体步骤(十分详细,手把手教会) |
宏基因组Bin及后续分析的具体步骤(十分详细,手把手教会)
|
当完成宏基因组的物种和功能注释之后,如果相对数据进行更深层次的挖掘,我们可以进行BIN。现在宏基因组的BINNING工具五花八门,且教程也是层出不穷。其中主要以Maxbin、metawrap、metabat2等为主,不同的软件各有千秋,如metawrap,在BIN的流程上,通过结合concoct, metabat2和maxbin2三个软件的结果,综合判定bins的质量,获得较好的结果,但是缺点是需要较大的服务器内存和花费较长的时间。Metabat2在同类分箱工具中具有更好的表现: 宏基因组最佳分箱工具Metabat2 1. 组装因此后文中我们选用Metabat2工具进行分箱,首先从序列文件组装开始: ##合并双端数据 cat *_R1.fastq > all_R1.fastq cat *_R2.fastq > all_R2.fastq ##进行组装,选用工具megahit,如果组装的文件较小,可以选用SPAdes进行组装,获得较好的组装结果。 nohup megahit -1 all_R1.fastq -2 all_R2.fastq -o assembly -t 24 -m 0.8 --min-contig-len 1000 --presets meta-large &-o 输出文件夹,最终结果和中间文件都会存放在该文件夹下; -t 调用线程数; -m 使用的内存,后面数字为占比,0.8即为服务器全部内存的80%; --min-contig-len 最小片段长度; --presets meta-large 宏基因组模式; nohup 后台运行。 2. 计算深度文件 2.1 序列比对组装完成后,还需一份序列深度的txt文件才能进行分箱,接下来就是进行深度文件的计算,这里采用bwa来进行比对: ##创建索引 bwa index assembly/final.contigs.fasta ##比对 bwa mem -k 19 -t 24 assembly/final.contigs.fasta all_R1.fastq all_R2.fastq > depth.sam这里需要注意的是,如果你想让任务后台运行,最好不要直接添加nohup,这会导致后续的操作出现报错的情况,(不要问我怎么知道的)应先创建一个sh文件后再执行nohup的操作指令,具体为: ##创建一个sh文件 vi bwa.sh ##这时候会弹出来一个界面,点i键开始写入内容(bwa mem -k 19 -t 24 assembly/final.contigs.fasta all_R1.fasta all_R2.fasta > depth.sam),然后ESC,接着Shift+:,左下角出现光标,输入wq,回车即可 ##运行 nohup sh bwa.sh & 2.2 深度计算sam文件还需转化为txt文件: ##先查看自己安装的samtools版本 samtools -version ##转换为bam、排序,1.3版本以前 samtools view -bs depth.sam > depth.bam samtools sort depth.bam > depth_sort.bam samtools index depth_sort.bam ##1.3版本后,排序和转换同时进行 samtools sort -@ 24 depth.sam > depth.bam samtools index -@ 24 depth_sort.bam接下来bam文件转换为Metabat2所需要的txt文件,需安装好Metabat2,借用其自带的脚本jgi_summarize_bam_contig_depths进行转换: jgi_summarize_bam_contig_depths --outputDepth depth.txt depth_sort.bam 3 分箱 nohup metabat2 -m 1500 -t 26 -i assembly.fasta -a depth.txt -o all -v 其中-m:最小contigs长度 -t:线程 -i:contig文件 -a:contig深度 -o:输出文件路径和前缀 -v:啰嗦模式 time:计时 4 分箱结果及基因评估进程结束后可在文件夹目录下生成一个bin的目录,里面包含了所有分箱的结果,这时候我们需要对所有的bins进行一个完整度和污染度的评估: nohup checkm lineage_wf -t 28 -x fa --nt --tab_table -f bins_qa.txt metabat_bins bins_qa_result & #-t 线程数 #-x 输入的文件格式后缀为fa,即分箱的结果,如bin.1.fa #--nt 检测序列为核酸序列 #--tab-table 输出文件格式,为txt或tsv #-f 输出文件 #metabat_bins 存放metabat2分箱结果的文件; #bin_qa-result 输出文件
评估结果中,我们主要关注的是Completeness和Contamination,即完整度即污染度。其中完整度0-100%;需要注意的是污染度Contamination是可以大于100%,不仅限于0-100%。开发者在github上解释如下:
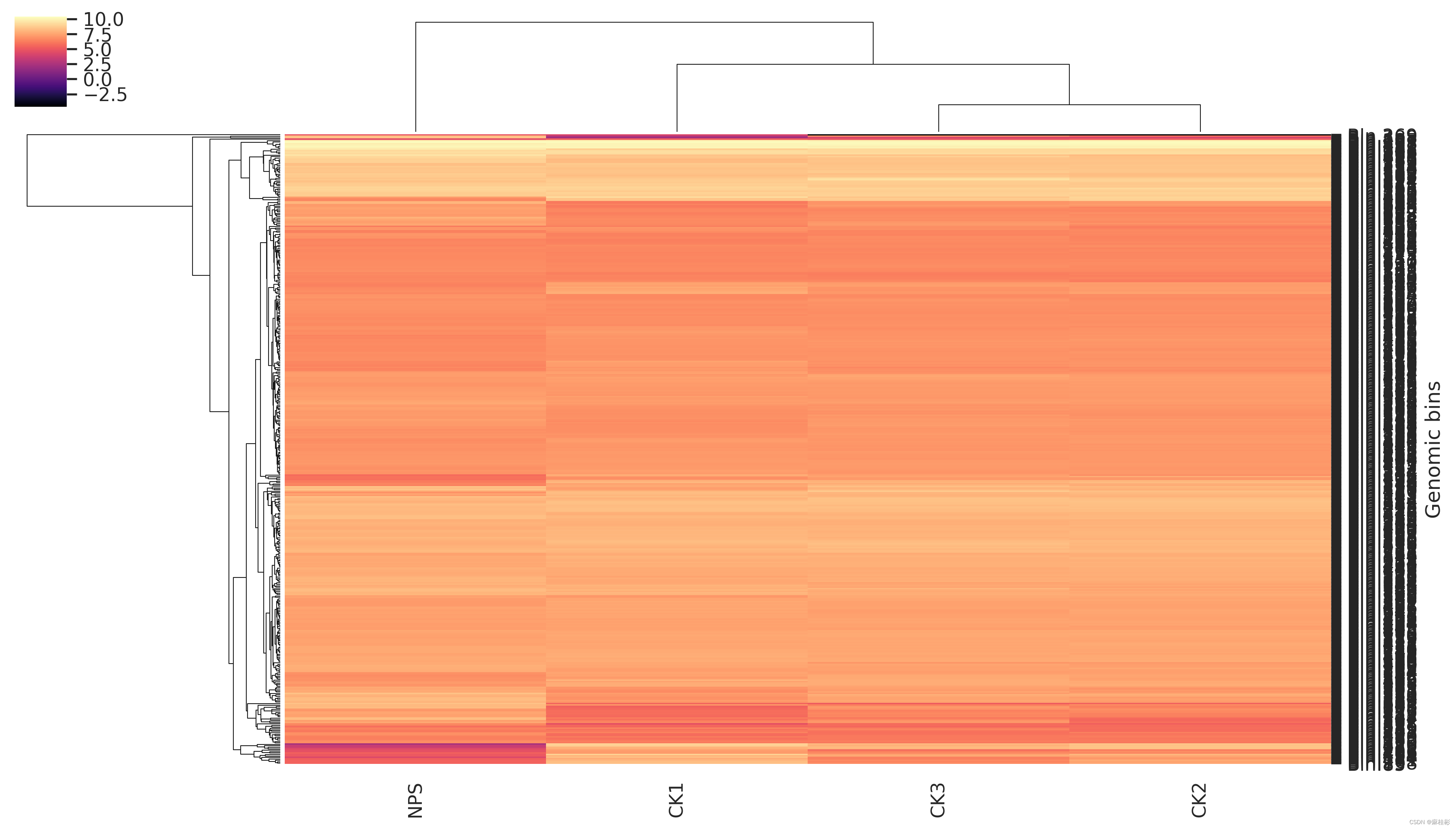
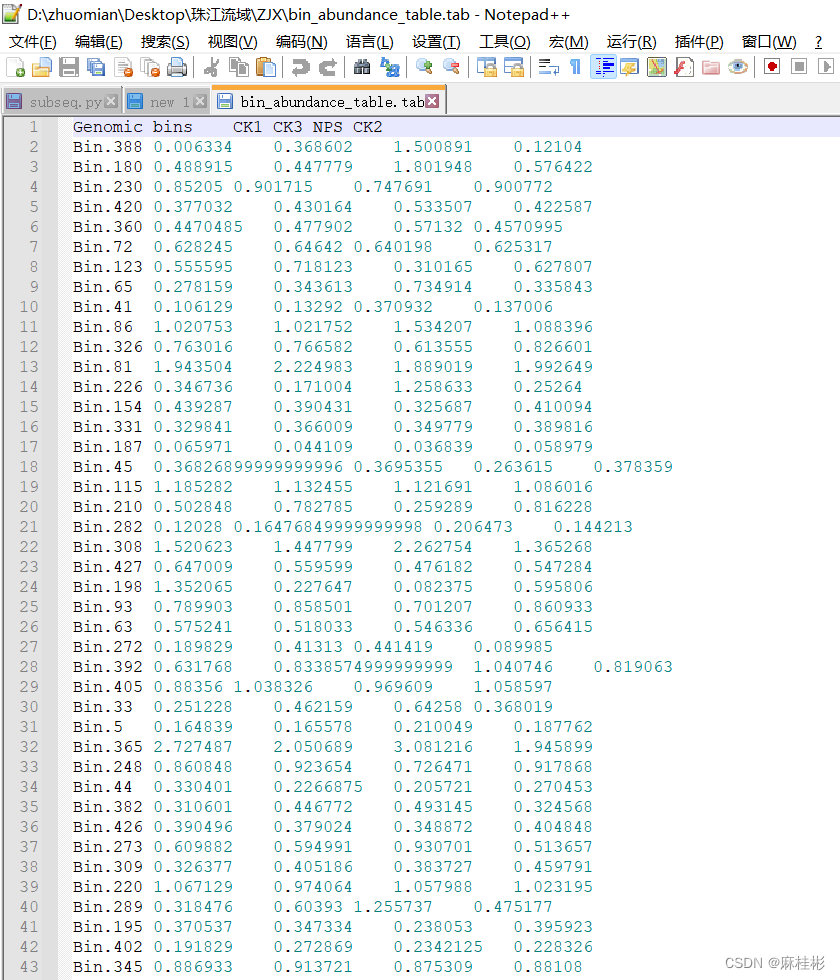
大致说的是污染值>100%意味着单拷贝标记基因被多次识别。如一个bins的56个标记基因出现次数大于5次,因此其contamination>100%,这表明这个bins包含5个或者更多的基因组。 bins的筛选根据完整度和污染度进行,具体阈值需要根据自己的研究来决定。主要是分为两类: 1. 单菌的基因组。这一策略是关注高完整度、低污染度的bins,期望构建该菌的完整基因组进行分析,如完整度 > 97%,污染度< 3%。 2. bins群落分析。这一策略则是降低完整度和污染度筛选阈值,如设定阈值为完整度 > 50%,污染度 < 20%。 这两个策略都有相关文献使用,可以找找看。 5 定量定量方式在上一篇推文中详细的描述:宏基因组TPM定量。不同的是bins与代表基因间的定量过程有所差别,这是因为bins中含有多个contigs,即多条独立的序列;而上篇推文的定量是单条序列进行的,因此进行bins的定量时,策略需要进行一定的调整,简单来说就是一个bins对每一条contigs进行定量,最后再求其均值作为这个bin的定量结果。这一过程类似于contigs的注释,每一条序列与NR数据库比对后会获得多个比对结果,这时候就需要根据它们的比对得分score来获取可信度最高的物种注释。不过为了简便,我们只需要使用别人造好的轮子,不需要花更多的时间和精力去重新创造,因此metawrap是一个不错的工具,当然,metawrap作为一个综合流程,也可以用它进行宏基因组的分析,详情参考:MetaWRAP分箱流程实战和结果解读。(如只需要metawrap进行bins定量,可以不进行数据库的配置) #安装好metawrap后,激活环境。安装方法参考上文博客。 conda activate metawrap #定量 metawrap quant_bins -b metabat_bins -t 28 -o QUANT_BINS -a assembly/final_assembly.fa clean_data/*_1.fastq clean_data/*_2.fastq其中,metabat_bin为metabat2运行保存bins的文件位置,如保存在当前目录下的bin目录,表示为 ./bin;-o 为输出文件;-a 为组装的fa序列文件;clean_data/*_1.fastq clean_data/*_2.fastq为质控后的双端序列文件。 最终结果文件夹QUANT_BINS中,会存在.tab后缀的文件,即为定量文件;其余结果中包括一些热图等。
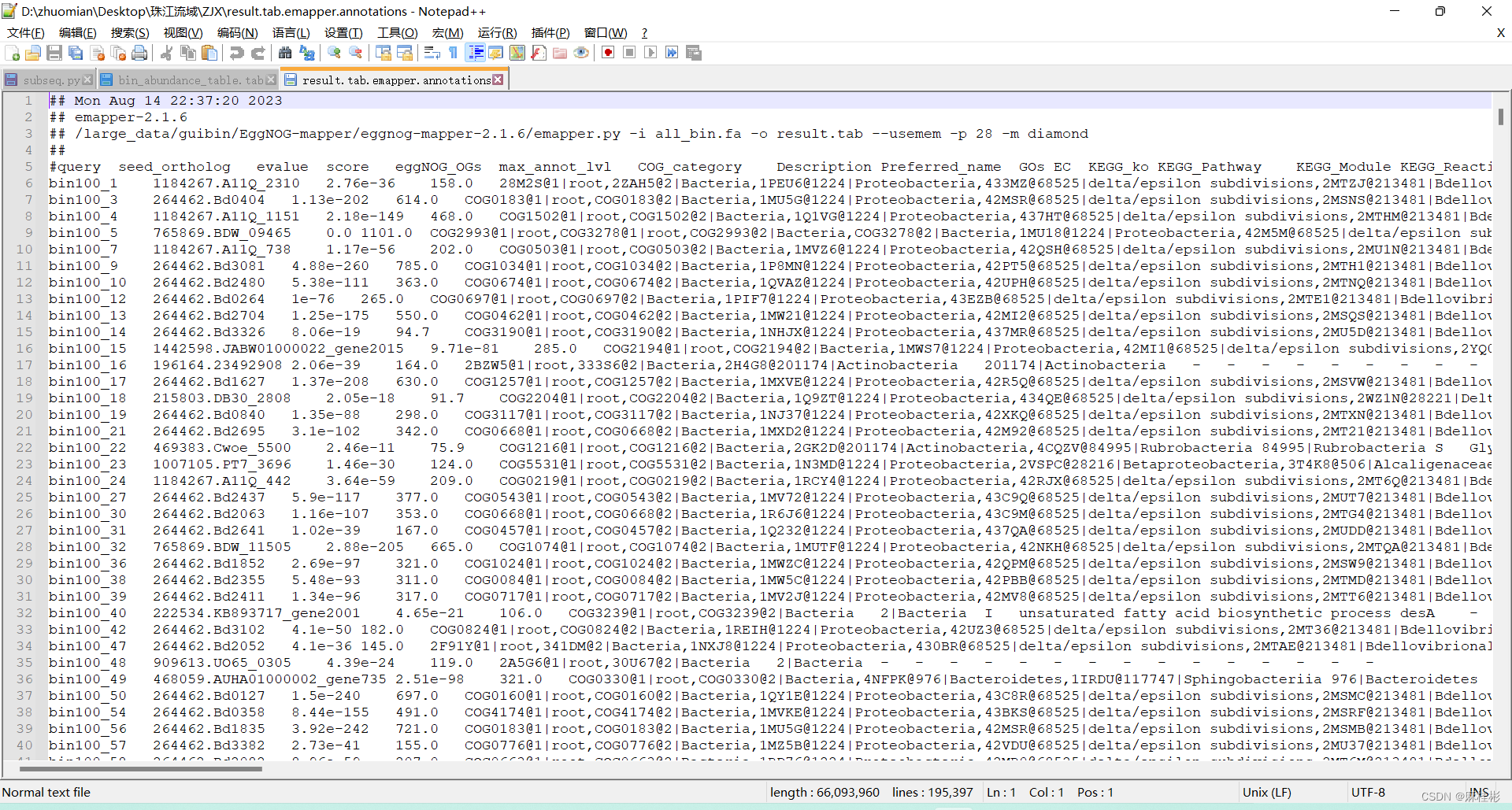
废话少说,功能注释策略是将所有bins的congtigs合并在一起,直接用Eggnog-mapper进行功能注释,但在那之前需要对每个bins的contigs重命名,防止不同bin基因组混在一起,需要注意的是这里bins的contigs指的是预测的功能区CDS(在checkm的结果文件中也含有每个bins的gff文件,可以直接提取使用): #prodigal预测序列功能区 for ((i=1;i new_bin${i}.fa done #为每条序列添加对应的bins的编号 for ((i=1; i all_bin.fasta #seqkit将核酸序列转化为蛋白序列,没有先安装,conda安装很快 seqkit translate --threads 20 all_bin.fasta > all_bin.faeggnog-mapper进行功能注释,首先是软件安装和数据库配置。 #下载eggnog-mapper git clone https://github.com/eggnogdb/eggnog-mapper.git #数据库下载 python ./download_eggnog_data.py #注释 python emapper.py -i all_bin.fa --output result -d bact --cpu 20 -m diamond --usemen #-d bact 细菌数据库 #-m diamond 比对方法 diamond,确保已下载
eggnog-mapper会生成三个结果文件: [project_name].emapper.hmm_hits: 记录每个用于搜索序列对应的所有的显著性的eggNOG Orthologous Groups(OG). 所有标记为"-"则表明该序列未找到可能的OG[project_name].emapper.seed_orthologs: 记录每个用于搜索序列对的的最佳的OG,也就是[project_name].emapper.hmm_hits里选择得分最高的结果。之后会从eggNOG中提取更精细的直系同源关系(orthology relationships)[project_name].emapper.annotations: 该文件提供了最终的注释结果。大部分需要的内容都可以通过写脚本从从提取。.emapper.annotations每一列对应的记录如下: 1. query: 检索的基因名或ID 2. seed_ortholog:seed同源数据库的注释结果 3. evalue:匹配的evalue值 4. score:匹配得分 5. eggNOG_OGs:eggnog的OG数据库比对结果 6. max_annot_lvl:物种信息的注释 7. COG_category:COG数据库 8. Description:对该蛋白的功能描述 9. Preferred_name:预测的基因名 10. GOs:GO数据库比对结果 11. EC:功能蛋白对应的酶编号 12. KEGG_ko:功能蛋白对应的KO编号 13. KEGG_Pathway:KEGG代谢通路 14. KEGG_Module:KEGG模块 15. KEGG_Reaction:KEGG反应过程 16. KEGG_rclass:KEGG rclass数据库 17. BRITE:BRITE数据库,KEGG 18. KEGG_TC:TC数据库 19. CAZy:碳水化合物数据库 20. PFAMs:蛋白结构域 eggnog-mapper的结果包含多个数据库注释结果,可根据自己的需要进行选择。其中常用的KEGG对应的KO和代谢通路、GO没有具体的注释,举要自己在官网上下载其相关文件进行解析使用,具体方法参考:kegg 上ko号对应的通路数据。 6.2 物种注释两个方法,一是软件一步到位,优点:步骤少,简便;缺点:数据库配置对新人不是很友好; 二是自己逐步进行,过程步骤较多,但相对容易理解。 首先是软件进行注释,metawrap或者phylophlan等;而另一个方式是自己下载NR数据库比对。具体选择哪种方法看你自己配置了哪个数据库。这里主要是phylophlan的注释和NR注释,metawrap在在上文的博客链接有详细的教程,不多叙述。这里我推荐phylophlan,因为该软件除了能进行bins的物种注释外,还能构建bins系统进化树,一步到位。参考:PhyloPhlAn 3.0 微生物组系统发育分析 #phylophlan安装 conda create -n python3.7 -c bioconda python=3.7 #创建新的环境 conda activate python3.7 conda install phylophlan=3.0 phylophlan --version #检查安装是否成功phylophlan能够自动下载两个原核生物通用数据库: 1. PhyloPhlAn (-d phylophlan, 400 universal marker genes) presented in Segata, N et al. NatComm 4:2304 (2013) 2. AMPHORA2 (-d amphora2, 136 universal marker genes) presented in Wu M, Scott AJ Bioinformatics 28.7 (2012) mkdir phylophlan_database && cd phylophlan_database #amphora2 wget http://cmprod1.cibio.unitn.it/databases/PhyloPhlAn/amphora2.tar wget http://cmprod1.cibio.unitn.it/databases/PhyloPhlAn/amphora2.md5 #phylophlan wget http://cmprod1.cibio.unitn.it/databases/PhyloPhlAn/phylophlan.tar wget http://cmprod1.cibio.unitn.it/databases/PhyloPhlAn/phylophlan.md5 #linux下载失败就window下载再上传 #解压 tar -xzf phylophlan.tar # 解压文件夹 bunzip2 -k phylophlan/phylophlan.faa.bz2 #amphora2.tar解压同上 #构建索引 diamond makedb --in phylophlan/phylophlan.faa --db phylophlan/phylophlan diamond makedb --in amphora2/amphora2.faa --db amphora2/amphora2物种注释,SGB (species-level genome bins) 数据库 (MetaRefSGB, *Pasolli E, et al. Cell 176.3 (2019)。注意SGB.Jan19数据库不需要提前下载,运行的时候会自动下载(这个有点奇怪)。 #SGB.Jan19数据库,其余数据库phylophlan_metagenomic查看,该数据库不需要提前下载,运行的时候会自动下载,而且是运行一次下载一次 phylophlan_metagenomic -i metabat_bin/ \ -o bin_result \ --nproc 24 \ -n 1 \ -d SGB.Jan19 \ --verbose 2>&1 | tee logs/phylophlan_metagenomic.log #-n 1 输出最近的注释结果结果生成一个tsv文件,包含物种注释信息。 构建进化树,这一步建议是筛选好了bins再进行,缩短运行时间。 #配置文件 python phylophlan_write_config_file \ -o custom_config_nt.cfg \ -d n \ --db_dna makeblastdb \ --map_dna diamond \ --msa muscle \ --trim trimal \ --tree1 fasttree \ --tree2 raxml-o: 输出文件名,-d: 设置该配置文件针对的数据库类型 (这里应该指的是核酸序列或者蛋白序列,我猜的) #进化树 phylophlan -i metabat_bin/ \ -d phylophlan/phylophlan \ --diversity low \ -f custom_config_nt.cfg \ --nproc 18--diversity 参数有三个选型,指定构建系统发育树的类型。
等待结果文件就行了。最后说一句,这个软件一次过的可能性根据自己的代码能力来,换句话说就是以此过蛮难的,多来几次就好了。 最后呢,补充bins依靠NR数据库的物种注释: #NR下载后创建索引 diamond makedb --in nr -d nr.dmnd #对bins进行处理 for ((i=1; i new_bin${i}.fa done cat new_bin*.fa > all_bin.fasta seqkit translate --threads 20 all_bin.fasta > all_bin.fa #注释 diamond blastp -d nr.dmnd -q all_bin.fa -p 30 -f 6 -sensitive --id 90 -k 50 -e 0.000001 -c 1 -b 12 -o result.tab #安装MEGAN wget https://software-ab.informatik.uni-tuebingen.de/download/megan6/MEGAN_Community_unix_6_21_16.sh sh MEGAN_Community_unix_6_21_16.sh #需要Xmanager或者在服务器安装 #下载GI号对应的taxanomy的mapping文件 wget https://software-ab.informatik.uni-tuebingen.de/download/megan6/prot_acc2tax-Jul2019X1.abin.zip unzip prot_acc2tax-Jul2019X1.abin.zip #使用MEGAN的LCA算法进行物种信息注释 ../MEGAN/megan/tools/blast2lca -i all_nr_match.txt -f BlastTab -ms 50 -me 0.000001 -a2t prot_acc2tax-Jul2019X1.abin -o nr_blast_otu_tax.tsv嗯,差不多就是这样的过程,好像过程也麻烦,还是推荐phylophlan进行注释。 到这里Binning的过程基本就结束了,最后的到的东西是: ① Binning得到的多个bins的基因组; ② 每个bins的完整度、污染度信息文件; ③ 每个bins的在不同位点的定量文件; ④ 每个bins的物种注释文件; ⑤ 每个bins的功能注释文件; ⑥ bins构建的系统发育树。 这时候你就可以根据需要进行分析了。 扫码关注微生物多组学公众号,后期会更新更多的组学干货。您的关注使我们最大的鼓励。
|




【本文地址】