|
文章目录
前言寻找目标思路分析步骤实现爬取过程实现效果以下是全部代码
 提示:以下是本篇文章正文内容,下面案例可供参考 提示:以下是本篇文章正文内容,下面案例可供参考
前言
大家点进来看selenium操作,那么你应该知道 selenium 是什么了这里不再过多的介绍,selenium它能做到自动操作,下面演示selenium自动化实现对网页的内容爬取进行保存和下载。
寻找目标
我先找到了一个专门发布表情包的网站,就叫做发表情网,可以通过搜索关键词得到大量相关的表情包,下面对这个网站的爬取进行介绍。这里我是进行热门表情包的抓取 
这个网站是属于静态加载的网站。我们不需要通过寻找数据接口去爬取,直接使用普通的爬虫代码进行爬取就可以了,或者使用selenium进行操作都可以。我们的操作对象找到了接下来就是开始干活。 
思路分析
selenium创建浏览器对象,总之爬取的第一步都是先对网页发起请求,请求成功后在网页里确定我们的操作步骤要干嘛(点击哪里或者要输查找什么东西等。。。)通过selenium提供的找元素的方法进行合适自己的使用,然后提取自己所需要的信息,我这里仅进行(图片,标题,详情页)的提取,如需要其他可自行添加,最后就是保存至Excel和下载图片。
步骤实现
首先我们要拿到浏览器的对象,接着开始访问网页找到热门表情包,并点击进入,在网页上通过xpath找到标签位置。  进到所需的热门表情包之后我们右键检查看看这些一个个表情包都储存在哪里,检查发现我们要的东西都在属性class="ui segment imghover"里面。 进到所需的热门表情包之后我们右键检查看看这些一个个表情包都储存在哪里,检查发现我们要的东西都在属性class="ui segment imghover"里面。 
接下来我们用selenium提供的xpath方法找到所有的div,再进行循环所有的div就可以获取我们所需的数据。title那里进行了一下处理,防止有些表情包名字过长导致后面下载图片的时候报错。  这样子我们所需的数据就爬取下来了,但只是得到第一页的内容,我们想要更多的表情包就得设置个翻页。那么我们怎么操作selenium帮我们进行自动翻页呢? 这样子我们所需的数据就爬取下来了,但只是得到第一页的内容,我们想要更多的表情包就得设置个翻页。那么我们怎么操作selenium帮我们进行自动翻页呢?  我在网页滑下来看了一下,右键检查了下一页,发现第二页表情包的链接href储存在a标签中,那么我们就可以通过selenium定位到下一页的标签,找到标签后我们就进行一个判断,如果我们的这个下一页的标签能获取到href的这个属性那就点击进行翻页。 我在网页滑下来看了一下,右键检查了下一页,发现第二页表情包的链接href储存在a标签中,那么我们就可以通过selenium定位到下一页的标签,找到标签后我们就进行一个判断,如果我们的这个下一页的标签能获取到href的这个属性那就点击进行翻页。  这里还要解决一下爬完表情包之后,防止翻页这里获得href后一直点击后面的下一页链接,要加个while给个判断条件,设置想要点击多少次下一页进行爬取,接下来我们就可以构造字典和列表进行数据的存储,调用其他函数进行相关的操作。 这里还要解决一下爬完表情包之后,防止翻页这里获得href后一直点击后面的下一页链接,要加个while给个判断条件,设置想要点击多少次下一页进行爬取,接下来我们就可以构造字典和列表进行数据的存储,调用其他函数进行相关的操作。  对数据进行保存至Excel的操作 对数据进行保存至Excel的操作  对数据图片进行下载保存操作 对数据图片进行下载保存操作 
爬取过程

到这我们的热门表情包就爬取下来,拥有这么多表情包是不是很爽,以后再也不怕不够别人斗图了。 
实现效果

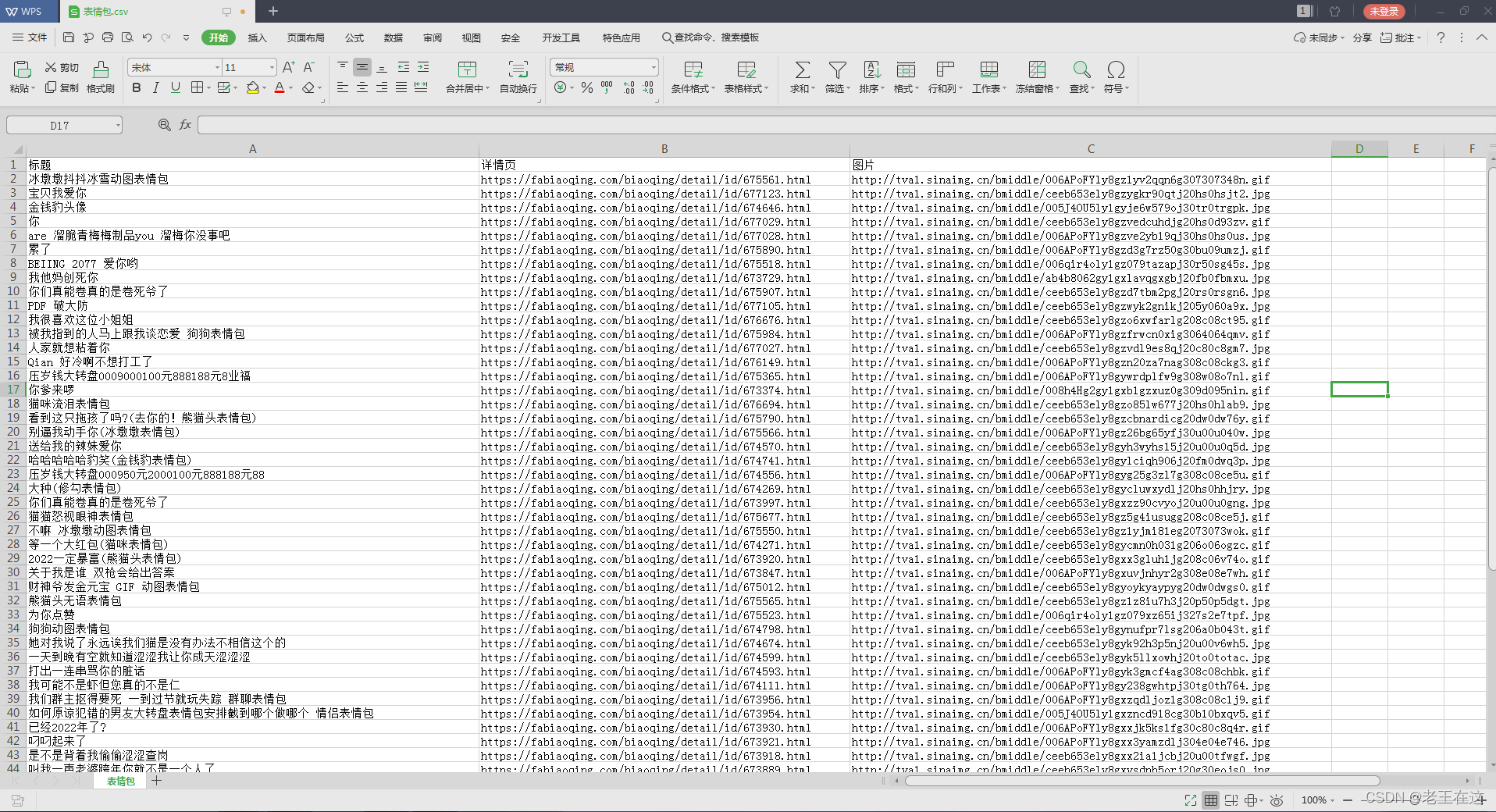
以下是全部代码
# @Author : 王同学
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait # 显示等待
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ActionChains # 动作链
import time
import re
import requests
import os.path
import csv
driver = webdriver.Chrome() # 创建浏览器对象
wait = WebDriverWait(driver,10)
def get_conten(url):
driver.get(url) # 对网页发送请求
time.sleep(1)
mood = wait.until(EC.presence_of_element_located((By.ID,'pcheaderbq'))) # 找到热门表情包点击
mood.click() # 找到热门表情包点击
time.sleep(1)
chains = wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="bqb"]/div[3]/a[8]'))) # 移动到页面末尾,加载元素
ActionChains(driver).move_to_element(chains).perform() # 开始移动
time.sleep(3)
def get_data():
all_data = [] # 定义列表 储存数据
n = 1
while n |